震惊性能测试圈的经典案例!!
JVM性能案例分享---今天来给大家分享几则性能分析和调优的案例:
案例一:回收器选择不当导致频繁FGC
【问题描述】
使用单台8C8G压力机Jmeter压测A系统,约3mins内存就占满4G,频繁出现FGC。
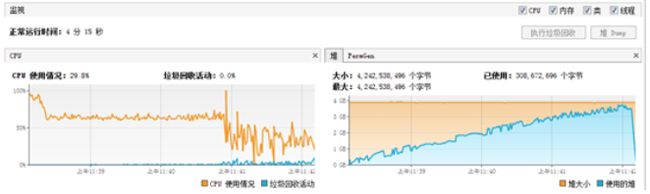
【性能场景】
单机模式下,使用500并发持续压测http明文接口;
默认jvm配置:-Xms1024m -Xmx2048m -XX:NewSize=512m。
【分析和调优过程】
1. 怀疑依赖jar包的方法导致内存泄露,打印dump内存文件进行分析,占用内存较大对象都是比较底层方法,没有线索。排查jar包内的方法,是否存在大对象或者一直new对象的操作,方法都很简单,并没有上述情况。
2. 转变思考方向,从jvm调优入手。加大堆内存:-Xms4096m-Xmx4096m -XX:NewSize=512m –Xss512k,FullGC频率比之前降低,但对压测结果并没有改善;继续调整:-Xms4096m-Xmx4096m -XX:NewSize=512m –Xss256k,FullGC频率又有所降低。
3. 查询当前jvm的相关信息,发现默认使用的UseParallelGC(新生代用ParallelGC回收器, 老年代使用串行回收器)收集器。在多核大并发情况下,CMS回收器性能更优。jvm参数开启CMS回收器,并增加CMS回收器相关配置: -XX:+CMSClassUnloadingEnabled -Xmx4096m -Xms4096m-XX:PermSize=512m -Xss256k -XX:CMSInitiatingOccupancyFraction=75-XX:+UseConcMarkSweepGC,性能问题解决,FullGC频率降低10分钟1次,每次FullGC都比较彻底,长时间压测性能结果很稳定。
案例二:堆内存参数设置不当导致频繁FGC
【问题描述】
现象:使用jvm默认收集器时,FGC很正常。开启cms收集器后,FGC10几秒1次,观察内存情况,发现old区内存增长很快。默认jvm配置如下:-XX:+CMSClassUnloadingEnabled–Xmx4096m –Xms4096m -XX:+UseConcMarkSweepGC。
【分析和调优过程】
1. 思考发生FGC的原因,Old区内存不够了,然而jvm配置了足够大的堆内存。用jmap –heap pid,查看了一下内存分配的情况。发现jvm默认分配给Eden区只有256Mb,s0和s1区只有32Mb。
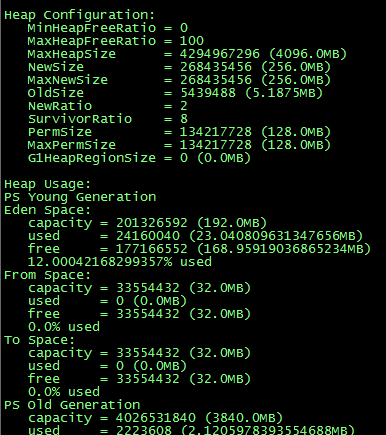
2. 回顾一下发生YGC时,会将没有回收的对象S0+eden -> S1,默认设置新生代很小,导致S1装不下由S0+eden复制而来的对象,会直接放入老年代内存,导致Old内存迅速增长。现象与猜想是否正确呢,jvm调优来验证一下。调整为:-XX:NewRatio=3 -XX:SurvivorRatio=8-XX:+CMSClassUnloadingEnabled-Xmx4096m -Xms4096m -XX:+UseConcMarkSweepGC。
3. 一时心急,把年轻代设置放在了最前面,结果服务启动报错,Too small for new size specified。调整一下位置:-XX:+CMSClassUnloadingEnabled-Xmx4096m -Xms4096m -XX:NewRatio=3 -XX:SurvivorRatio=8-XX:+UseConcMarkSweepGC。
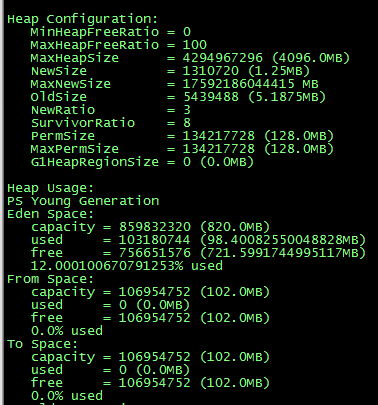
4. 查看一下此时内存分配。压测结果稳定,没有再出现FullGC的情况。
案例三:Tomcat大量线程阻塞
【问题描述】
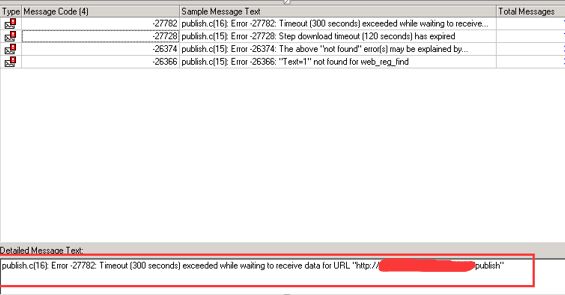
现象:一发布接口,并发10路,运行一分钟多,接口开始一直失败,LR显示超时,如下图:
【分析过程】
1. 使用Jstack导出线程快照,用IBM一个线程分析工具查看,发现有大量线程在等待,如下图:
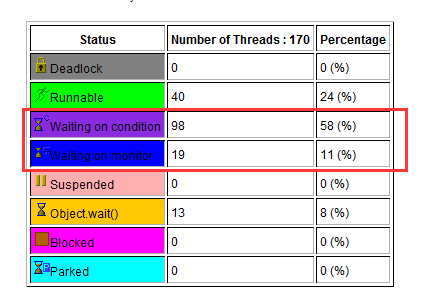
2. 查看详细的线程信息发现处于blocked状态的都在争同一个资源,而且就是状态runnable锁住的资源。并且与hbase有关。如下图:
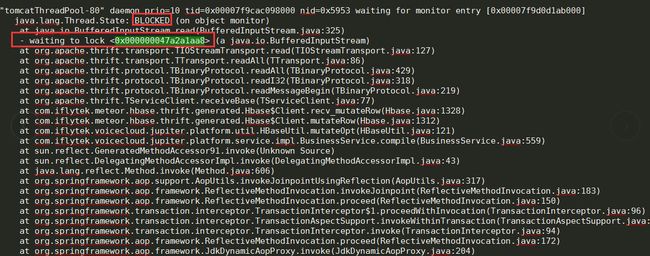
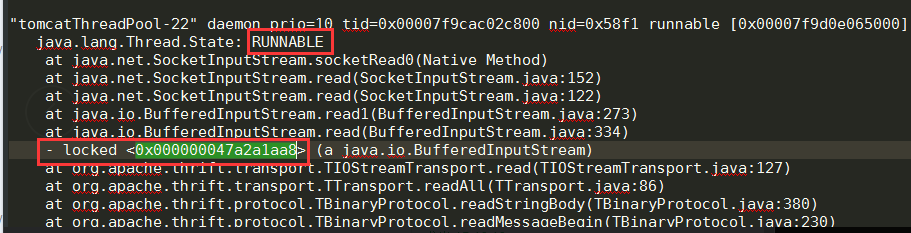
3. 与开发沟通后,怀疑定义了一个全局变量(hbase客户端初始化)导致的。改成每个线程都去初始化一个实例。

4. 修改后重新测试,没有出现超时失败问题。
通过这些案例,相信大家已对性能分析和调优的套路有所领略,对性能测试的魅力也有所感触,更多分享,敬请期待。
