Hadoop 2.7 安装和配置
内容
- 一、安装规划
- 二、安装准备
-
- 1、检查节点的网络管理器
- 2、使用下面的命令来验证网络管理器服务的状态:
- 3、检查节点的IP地址
- 4、设置节点的IP地址
- 5、编辑网卡配置文件
- 6、使配置文件生效
- 7、检查网络互连
- 三、关闭防火墙服务
-
- 1、检查防火墙服务状态
- 2、禁用并停止防火墙服务
- 3、确认防火墙状态
- 四、设置主机名
-
- 1、修改主机名
- 2、修改hosts文件
- 五、设置免密登录
-
- 1、配置SSH免密登录
- 2、为root用户生成证书
- 3、在master节点上合并公钥
- 4、检查合并生成的authorized_ keys文件
- 5、复制authorized_ keys 文件到slave服务器
- 六、安装JDK 1.8
-
- 1、下载JDK
- 2、分发JDK1.8安装文件
- 3、安装JDK1.8 (在三台服务器分别执行)
- 4、设置环境变量(在三台服务器分别执行)
- 七、安装Hadoop 2.7
-
- 1、下载Hadoop安装文件并上传到master服务器
- 2、解压缩
- 3、修改配置文件
- 4、修改slaves配置文件
- 八、Hadoop管理
-
- 1、格式化namenode
- 2、启动Hadoop集群
- 3、检查Hadoop服务状态
- 4、通过Web界面查看Hadoop状态
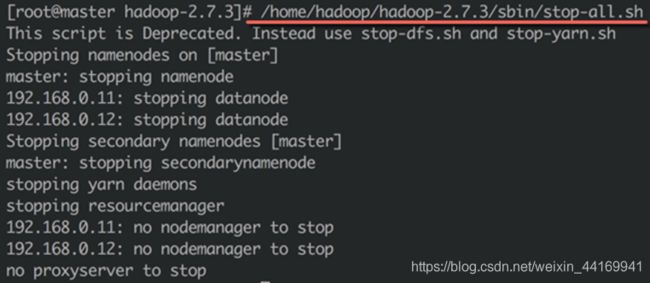
- 5、停止Hadoop服务
一、安装规划
3台服务器,以最小模式(Minimal) 模式安装的CentOS 7系统
IP地址规划
master 192.168.0.10
slave1 192.168.0.11
slave2 192.168.0.12
二、安装准备
在三台服务器分别执行:
1、检查节点的网络管理器
● 网络管理器(Network Manager) 是一个动态网络的控制器与配置系统,它用于当网络设备可用时保持设备和连接开启并激活。默认情况下,CentOS/RHEL 7安装有网络管理器,并处于启用状态。
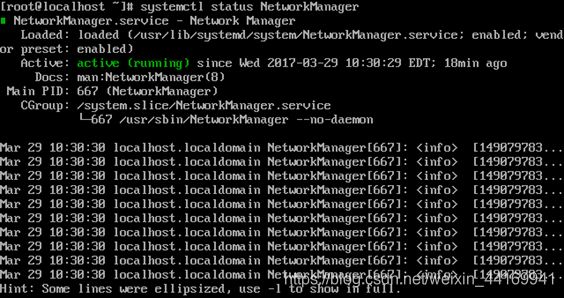
2、使用下面的命令来验证网络管理器服务的状态:
systemctl status NetworkManager
3、检查节点的IP地址
● 运行以下命令来检查受网络管理器管理的网络,接口:
nmcli dev status

此时,说明当前服务器节点的网卡名称是enpOs5
确保网卡enp0s5没有分配IP地址
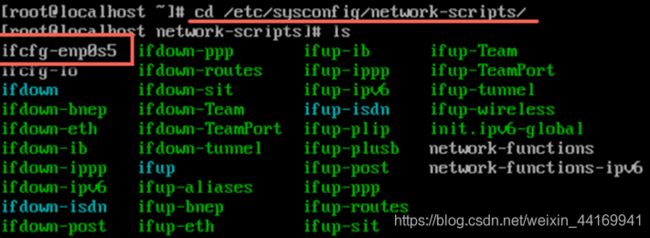
4、设置节点的IP地址
● 进入/etc/sysconfig/network-scripts目录,找到该网卡的配置文件(ifcfg-enp0s5) 。如果没有,请创建一个。
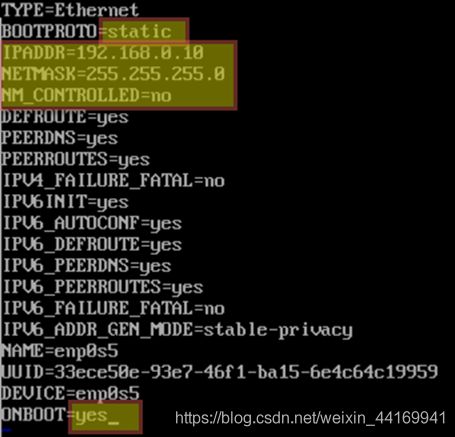
5、编辑网卡配置文件
打开配置文件并编辑以下变量
● “BOOTPROTO=static”表示该网卡使用的是静态IP
● “IPADDR”是指网卡的IP地址
● “NETMASK”是指网络的子网掩码
● “NM_ CONTROLLED=no"表示该网卡通过配置文件进行设置而不是通过网络管理器进行管理
● “ONBOOT=yes”表示系统将在启动时启用该网卡
6、使配置文件生效
● 保存修改并使用以下命令来重启网络服务:systemctl restart network
● 通过如下命令查看是否设置成功:ip addr show

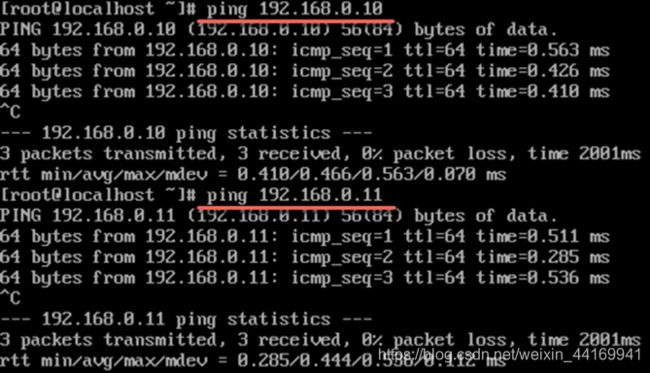
7、检查网络互连
● 同样的步骤,在另外两个节点上执行之后检查三个简单间是否可以ping通
三、关闭防火墙服务
在三台服务器分别执行:
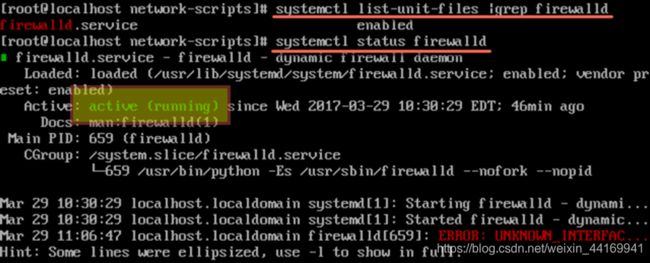
1、检查防火墙服务状态
● 运行如下命令检查Centos7开机是否自启动:systemctl list-unit-files |grep firewalld
● 如果出现“enabled”说明防火墙服务开机自动
2、禁用并停止防火墙服务
● 依次运行如下命令禁用并停止防火墙服务
systemctl disable firewalld
systemct stop firewalld

3、确认防火墙状态
● 再次运行命令检查当前防火墙的状态
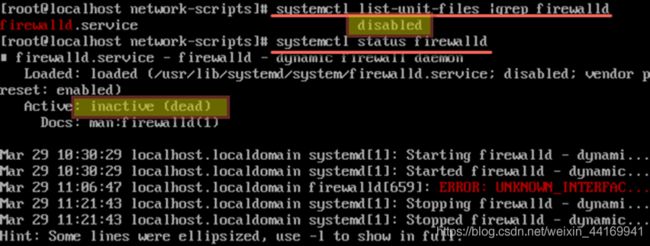
分别在另外两台服务器上执行相同的操作关闭防火墙服务
四、设置主机名
在三台服务器分别执行:
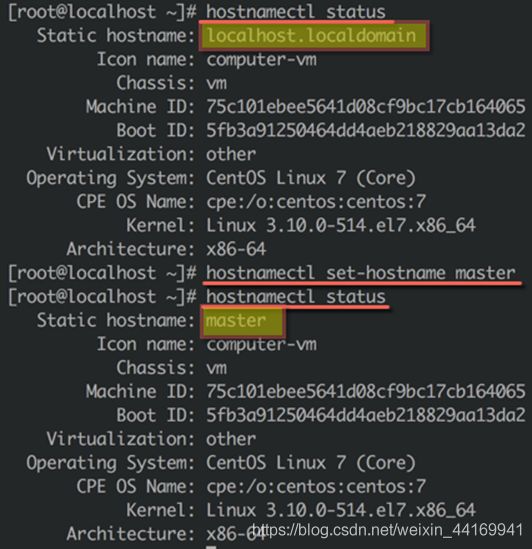
1、修改主机名
● 运行如下命令, 将全节点的主机名修改为:master
hostnamectl status:查看主机名称
hostnamectl set-hostname master:设置主机名称
●对比前后设置
●退出shell环境,重新登录后可以查看到修改后的主机名master
●分别将另外两个节点的主机名设置为slave1和slave2
2、修改hosts文件
● 修改/etc/hosts文件,分别在三个节点的每个hosts文件中增加如下三行代码

五、设置免密登录
在三台服务器分别执行:
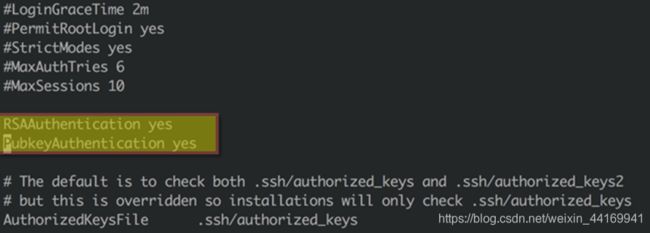
1、配置SSH免密登录
● 默认情况下服务器间通过SSH协议相互访问时需要输入用户名和密码,但是Hadoop希望通过SSH登录到各个节点进行操作时不输入名户名和口令,这就要求使用相同的用户root,同时设置服务器间相互免密访问
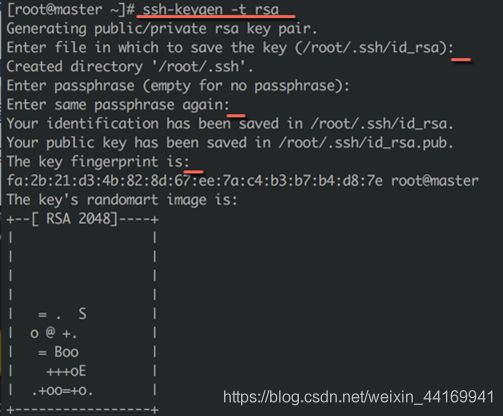
2、为root用户生成证书
● 执行如下命令为root用户生成RSA公私密钥对:ssh-keygen -t rsa
● 在三次需要输入信息的时候都直接按回车键,直到出现RSA 2048图案
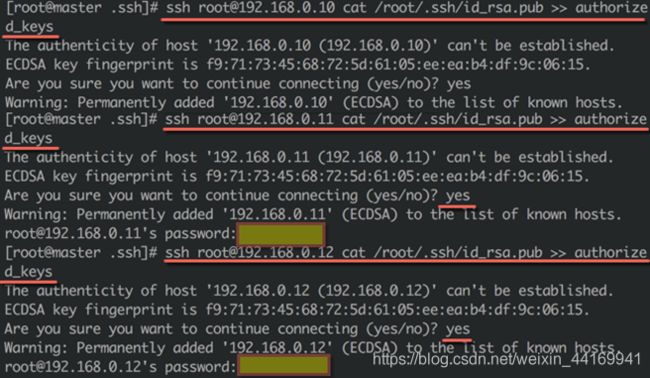
3、在master节点上合并公钥
● 进入master节点的/root/.ssh目录,在该目录下存放有刚刚为root用户生成的公钥id_ rsa.pub和私钥id_rsa
● 执行如下命令,将三个服务器上的公钥id_ rsa.pub合并到文件 authorized keys 中
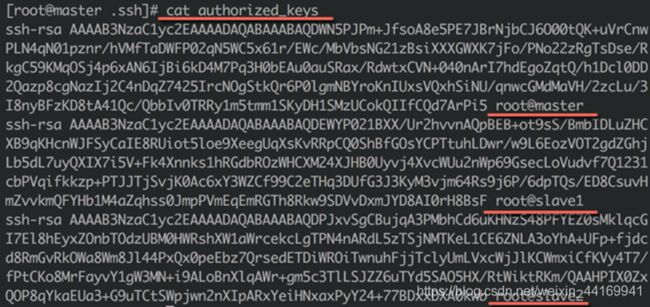
4、检查合并生成的authorized_ keys文件
● 运行如下命令查看authorized_keys文件,确认其中包含了root用户在master、slave1和slave2三台服务器上的公钥信息:cat authorized_keys
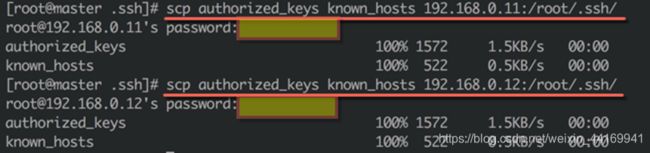
5、复制authorized_ keys 文件到slave服务器
● 执行如下命令,将刚刚合并生成的authorized_ keys和known_ hosts两个文件分别上传到slave1和slave2服务器上
scp authorized_ keys known hosts 192.168.0.11:/root/.ssh
scp authorized keys known hosts 192.168.0.12:/root/.ssh
六、安装JDK 1.8
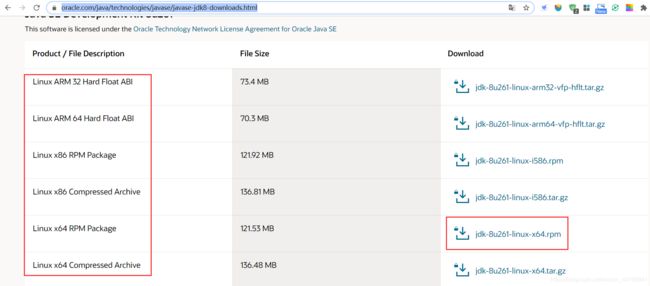
1、下载JDK
●打开Oracle官网,下载JDK的rpm格式的64位Linux操作系统的安装包
https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
2、分发JDK1.8安装文件
●上传下载的JDK到服务器master的/root目录下(可以通过Xshell、putty、 winscp等软件)
●执行如下命令将JDK安装文件.上传到slave1和slave2两台服务器上
scp jdk-8u121-linux-x64.rpm 192.168.0.11:/root

注意:如果上一步的免密配置成功,此时不需要输入密码。
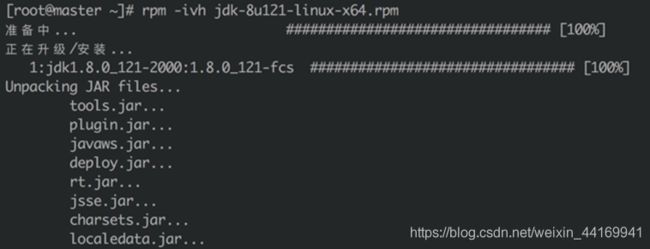
3、安装JDK1.8 (在三台服务器分别执行)
● 运行如下命令安裝JDK:rpm -ivh jdk-8u121-linux-x64.rpm
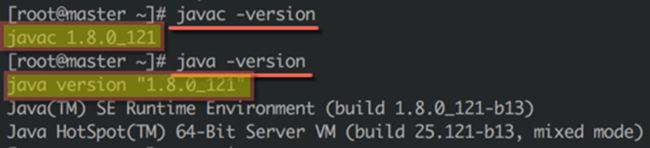
● 运行如下命令检验
4、设置环境变量(在三台服务器分别执行)
● 新建文件/etc/ profile.d/java.sh,键入如下内容
export JAVA_HOME=/usr/java/jdk1.8.0_121
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar

● 执行如下命令,使环境变量设置生效,并检查:source /etc/profile.d/java.sh

七、安装Hadoop 2.7
1、下载Hadoop安装文件并上传到master服务器
●从Hadoop官方网站下载Hadoop安装文件,hadoop-2.7.3.tar.gz
●通过工具上传到master服务器上,并运行如下命令将安装文件分发到slave1和slave2节点
scp hadoop-2.7.3.tar.gz 192.168.0.11:/root
scp hadoop-2.7.3.tar.gz 192.168.0.12:/root
2、解压缩
● 创建/home/hadoop目录及数据目录,将安装文件移入该目录
mkdir /home/ hadoop
cd /home/hadoop/
mkdir tmp hdfs hdfs/data hdfs/ name
mv hadoop-2.7.3.tar.gz /home/hadoop
● 输入如下命令解压安装文件:tar zxvf hadoop-2.7.3.tar.gz
3、修改配置文件
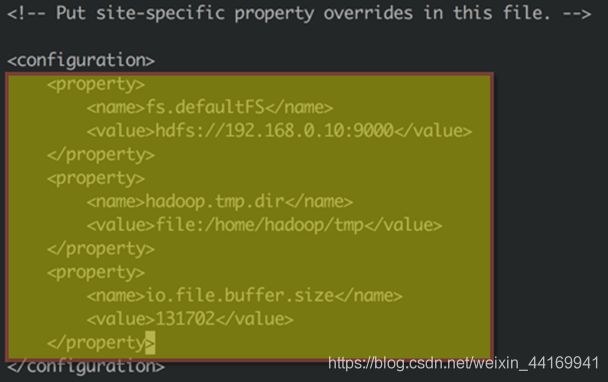
● 修改core-site.xml配置文件
● 修改/home/hadoop/hadoop-2.7.3/etc/hadoop/core-site.xml配置文件
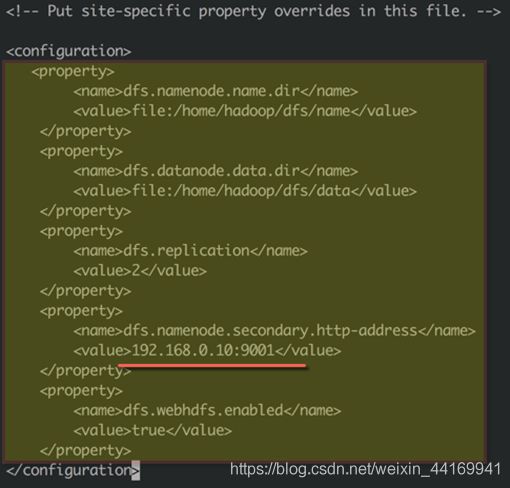
● 修改hdfs-site.xml配置文件
● 修改/home/hadoop/hadoop-2.7.3/etc/hadoop/hdfs-site.xml配置文件
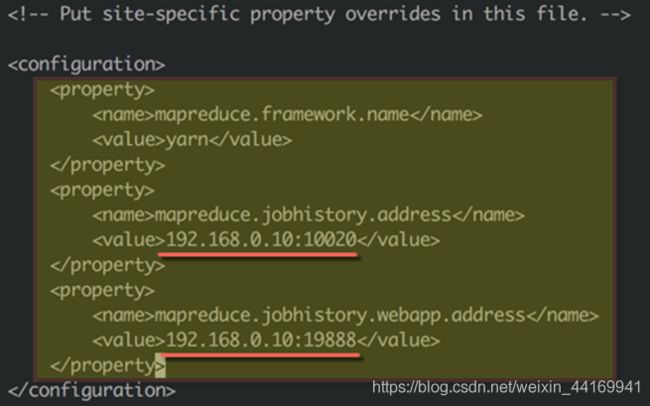
● 修改mapred-site.xm|配置文件
● 修改/home/hadoop/hadoop-2.7.3/tc/hadoop/mapred-site.xml配置文件
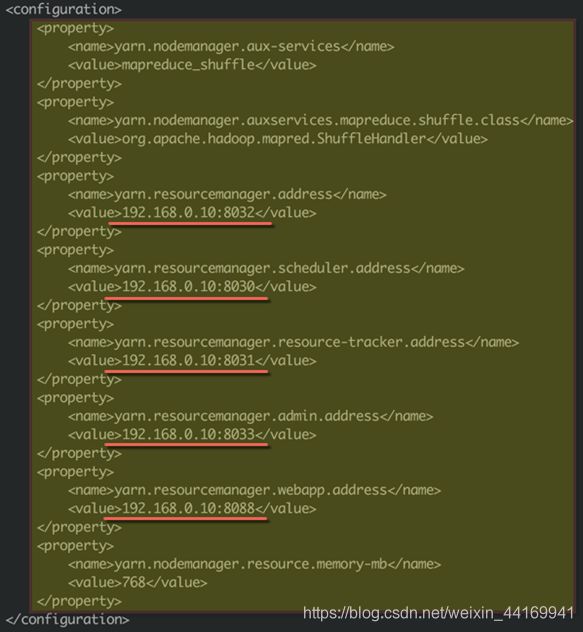
● 修改yarn-site.xml配置文件
● 修改/home/hadoop/hadoop-2.7.7/etc/hadoop/yarn-site.xml配置文件
(最后一项将768改为1024)
4、修改slaves配置文件
●修改/home/hadoop/hadoop-2.7.3/etc/hadoop/slaves配置文件,删除原有的localhost,添加slave1和slave2的IP
192.168.0.11
192.168.0.12
八、Hadoop管理
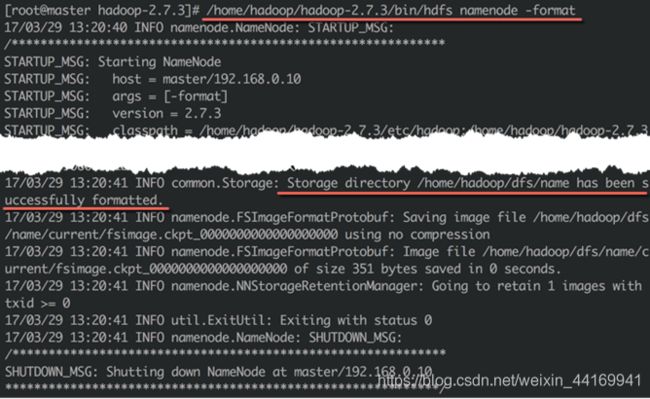
1、格式化namenode
● 在master节点上运行如下命令,格式化namenode
/home/hadoop/hadoop-2.7.3/bin/hdfs namenode -format
2、启动Hadoop集群
● 在master节点上运行如下命令,启动Hadoop集群
/home/hadoop/hadoop 2.7.3/sbin/start-all.sh
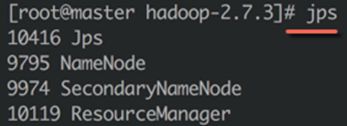
3、检查Hadoop服务状态
● 输入jps命令,可以查看Hadoop相关服务的运行状态
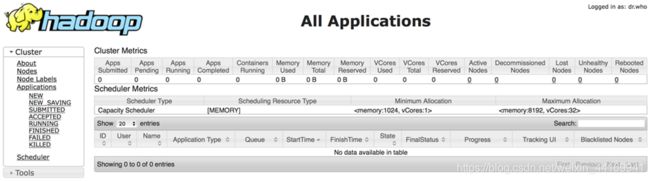
4、通过Web界面查看Hadoop状态
访问http://192.168.0.10:8088/页面,可以查看集群状态
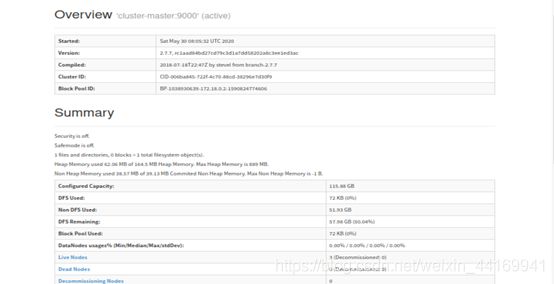
访问http://192.168.0.10:50070页面,可以查看详细信息
5、停止Hadoop服务
● 运行如下命令可以停止Hadoop服务
/home/hadoop/hadoop-2.7.3/sbin/stop-all.sh