R语言笔记(一):理解hist绘图函数中的参数breaks和freq
breaks接收的可以是单个的数值,也可以是向量,当接收的是单个数值时表示间隔点的个数,当接收的是间隔点的值。
freq是接收的是True和False,当freq=True时,纵轴是频数,当freq=False时,纵轴是密度,当freq缺省时,当且仅当breaks是等距的,freq取True。
举例:
chara是包含了1500部小说的总字数数据的向量,单位为万,对这个数据绘制直方图,观察不同总字数的小说的频数。
- breaks取单个数值
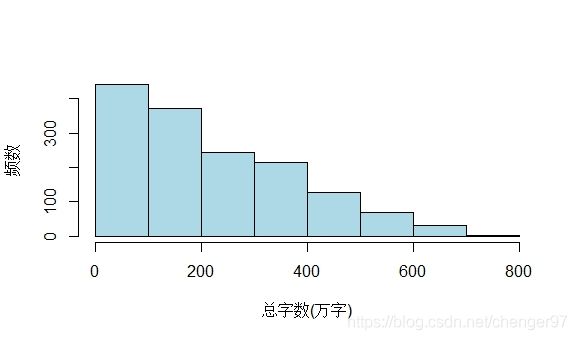
hist(chara, breaks = 9, xlab = "总字数(万字)", ylab = "频数", main = "", col = "lightblue")
这里取9个间隔点,分别为:0,100,200,300,400,500,600,700,800
此时breaks是等距的,freq缺省,所以纵轴为频数。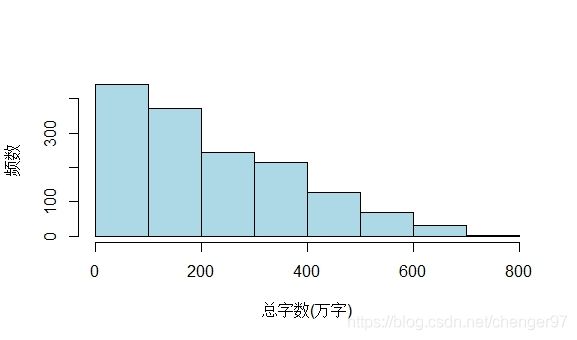
- breaks取向量
hist(chara, breaks = c(0,200,300,400,800), xlab = "总字数(万字)", ylab = "频数", main = "", col = "lightblue")
这里设置的间隔点为:0,200,300,400,800
此时breaks不是等距的,freq缺省,所以纵轴是密度。

- breaks为函数
情况1:
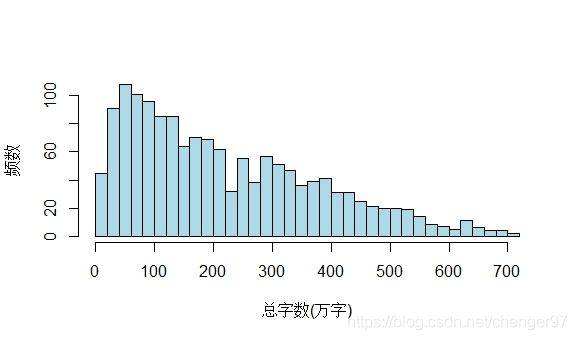
hist(chara, breaks = function(x) length(x)/50, xlab = "总字数(万字)", ylab = "频数", main = "", col = "lightblue")
此时break后的函数得到的是一个数值,所以与前面取单个数值的情况相同,这里的函数值代表间隔点个数。
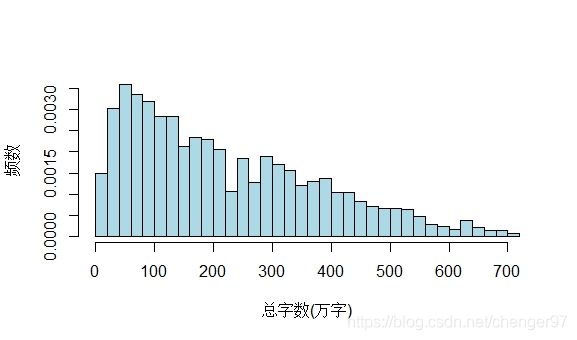
可以给freq取F使纵轴变为密度:
hist(chara, breaks = function(x) length(x)/50,freq = F, xlab = "总字数(万字)", ylab = "频数", main = "", col = "lightblue")
情况2:
hist(chara, breaks = function(x) c(0:ceiling(max(x))), xlab = "总字数(万字)", ylab = "频数", main = "", col = "lightblue")
breaks后函数的取值为一个向量,所以和breaks后取向量的情况相同,向量代表间隔点的值。
这里的每隔1取一个间隔点。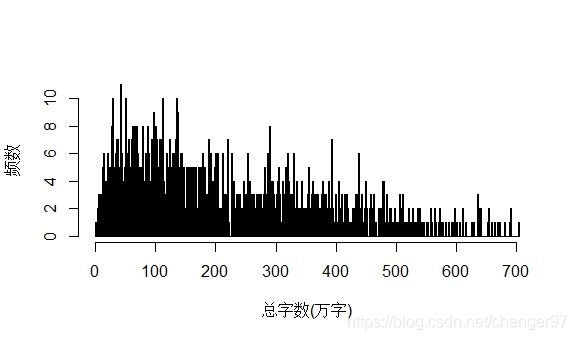
也可以做间隔100取一个间隔点:
hist(chara, breaks = function(x) seq(0,(floor(max(x)/100)+1)*100,100), xlab = "总字数(万字)", ylab = "频数", main = "", col = "lightblue")