yarn集群调优
一、概述
每个job提交到yarn上执行时,都会分配Container容器去运行,而这个容器需要资源才能运行,这个资源就是Cpu和内存。
1、CPU资源调度
目前的CPU被Yarn划分为虚拟CPU,这是yarn自己引入的概念,因为每个服务器的Cpu计算能力不一样,有的机器可能是 其他机器的计算能力的2倍,然后可以通过多配置几个虚拟内存弥补差异。在yarn中,cpu的相关配置如下。
yarn.nodemanager.resource.cpu-vcores
表示该节点服务器上yarn可以使用的虚拟的CPU个数,默认是8,推荐配置与核心个数相同,如果节点CPU的核心个数不足8个,需要调小这个值,yarn不会智能的去检测物理核数。如果机器性能较好,可以配置为物理核数的2倍。
yarn.scheduler.minimum-allocation-vcores
表示单个任务最小可以申请的虚拟核心数,默认为1
yarn.sheduler.maximum-allocation-vcores
表示单个任务最大可以申请的虚拟核数,默认为4;如果申请资源时,超过这个配置,会抛出 InvalidResourceRequestException
2、Memory资源调度
yarn一般允许用户配置每个节点上可用的物理资源,可用指的是将机器上内存减去hdfs的,hbase的等等剩下的可用的内存。
yarn.nodemanager.resource.memory-mb
设置该节点上yarn可使用的内存,默认为8G,如果节点内存不足8G,要减少这个值,yarn不会智能的去检测内存资源,一般这个值式yarn的可用内存资源。
yarn.scheduler.minmum-allocation-mb
单个任务最小申请物理内存量,默认是1024M,根据自己业务设定
yarn.scheduler.maximum-allocation-mb
单个任务最大可以申请的物理内存量,默认为8291M
二、如果设置这几个参数
如果一个服务器是32核,虚拟后为64核,128G内存,我们该如何设置上面的6个参数呢?即如何做到资源最大化利用
生产上我们一般要预留15-20%的内存,那么可用内存就是128*0.8=102.4G,去除其他组件的使用,我们设置成90G就可以了。
1、yarn.sheduler.maximum-allocation-vcores
一般就设置成4个,cloudera公司做过性能测试,如果CPU大于等于5之后,CPU的利用率反而不是很好。这个参数可以根据生成服务器决定,比如公司服务器很富裕,那就直接设置成1:1;设置成32,如果不是很富裕,可以直接设置成1:2。我们以1:2来计算。
2、yarn.scheduler.minimum-allocation-vcores
如果设置vcoure = 1,那么最大可以跑64/1=64个container,如果设置成这样,最小container是64/4=16个。
3、yarn.scheduler.minmum-allocation-mb
如果设置成2G,那么90/2=45最多可以跑45个container,如果设置成4G,那么最多可以跑24个;vcore有些浪费。
4、yarn.scheduler.maximum-allocation-mb
这个要根据自己公司的业务设定,如果有大任务,需要5-6G内存,那就设置为8G,那么最大可以跑11个container。
三、任务调度调优
FairScheduler—公平调度
根据我的经验及理解,相对于CapacityScheduler调度器,FairScheduler在配置过程上更加简单,但资源调度上就相对粗暴一些;
CapacityScheduler—容器调度
该调度器在资源调度上更加精细,但配置过程相对复杂一些。
由于两种调度器实现的功能并无太大差异,对于生产系统来讲,两种调度器均可使用,笔者本次主要针对FairScheduler调度器进行实践及探究。
实践探究
FairScheduler支持Fair(公平排序算法)和Fifo(先进先出)两种调度模式,来实现各个租户和任务之间资源的调度,然而如何行之有效的结合Fair和Fifo两种模式来平衡任务差异性与资源利用最大化之间的关系,是多租户平台需要探究的问题,经过长期的生产实践及相关测试,笔者得出如下结论:
模式设置:队列之间使用Fifo(先进先出)模式,队列内部任务之间使用Fifo(先进先出)模式
实践结论:这种组合模式下,队列内部先提交的任务可获得充足的资源以最快速度完成,但在空闲资源较少的情况时,后提交任务的队列需要等待前面队列中任务释放资源后才可启动,若前面队列任务执行较慢,则会大大增加后续队列所有任务的等待时间,从而增加后续队列所有任务的延迟时间;
模式设置:队列之间使用Fifo(先进先出)模式,队列内部任务之间使用Fair(公平排序)模式
实践结论:这种模式与第一种模式存在同样的问题,后续队列中的任务在资源较为紧张的情况下延时过大。
模式设置:队列之间使用Fair(公平排序)模式,队列内部任务之间使用Fifo(先进先出)模式
实践结论:这种模式下,无论各个队列提交任务的次序如何,均可在抢占时间到达时,获得配置的最小资源量供队列内任务运行,而队列内部的Fifo模式也可保证先提交的任务获得充足的资源,以最快速度完成,且整体资源利用率较高。
模式设置:队列之间使用Fair(公平排序)模式,队列内部任务之间使用Fair(公平排序)模式
实践结论:这种模式与第三种类似,可以保证每个队列提交的任务都可以获取资源,但队列内部任务之间的Fair模式,使得任务之间公平的获取资源,如果出现队列内同一时间段提交大量任务的情况,则这些任务各自获取的资源量就很小,也就意味着队列内所有任务执行速度都非常缓慢,即所有任务都会出现较大延时。
综上所述,在任务差异性较大的多租户平台中,较为合理的调度模式为上述第三种:在队列间使用Fair(公平排序)模式,队列内部的任务间使用Fifo(先进先出)模式。
=========================
四、篇外—小米的yarn调度
本篇文章将浅析 YARN 调度器以及在小米的探索与实践
什么是YARN?
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。也就是说 YARN 在 Hadoop 集群中充当资源管理和任务调度的框架。
YARN 基本结构:(图片来自 Apache Yarn 官网)
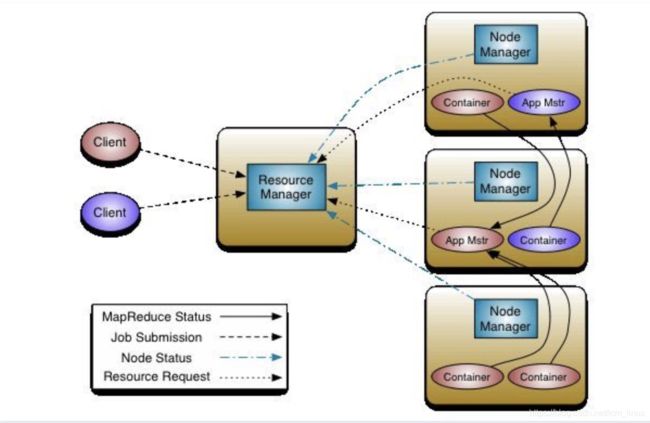
负责资源管理和调度的组件:全局的资源管理器 ResourceManager(RM)和每个应用程序的 ApplicationMaster(AM)。应用程序可以是单个作业,也可以是 DAG 作业。ResourceManager 和 NodeManager 组成数据计算框架。
ResourceManager 负责集群资源的统一管理和调度;
NodeManager 负责单节点资源管理和使用,处理来自 ResourceManager/ApplicationMaster 的命令;
ApplicationMaster 负责应用程序的管理;
Container 是对任务运行环境的抽象,描述任务运行资源(节点、内存、CPU), 启动命令以及环境。
调度器的选择
我们都希望自己提交的作业能够很快被调度并且拿到足够的资源保证 job 进行顺畅。对于共享型集群来说,保证每个作业可以被合理的调度并分配相应的资源,同时考虑成本问题,变得更加困难。但是通过不断的探索 Yarn 的调度策略与可配置方案也可以逐渐接近目标。
Yarn 提供了三种可用资源调度器 (直接从 MRv1 基础上修改而来的):
FIFO Scheduler ,Capacity Scheduler,Fair Scheduler。
FIFO Scheduler:从字面不难看出就是先进先出策略,所有的任务都放在一个队列中,只有执行完一个任务后,才会进行下一个。这种调度方式最简单,但真实场景中并不推荐,因为会有很多问题,比如如果有大任务独占资源,会导致其他任务一直处于 pending 状态等。
Capacity Scheduler:也就是所谓的容量调度,这种方案更适合多租户安全地共享大型集群,以便在分配的容量限制下及时分配资源。采用队列的概念,任务提交到队列,队列可以设置资源的占比,并且支持层级队列、访问控制、用户限制、预定等等配置。不过对于资源占用比需要不断的摸索与权衡。
如果选择 Cpapacity Scheduler,需要配置 ResourceManager 使用 CapacityScheduler,即 conf/yarn-site.xml 中设置属性:
Cpapacity Scheduler
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
调度配置文件 etc/hadoop/capacity-scheduler.xml:
capacity-scheduler.xml
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>a,b,c</value>
<description>The queues at the this level (root is the root queue).
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.a.queues</name>
<value>a1,a2</value>
<description>The queues at the this level (root is the root queue).
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.b.queues</name>
<value>b1,b2,b3</value>
<description>The queues at the this level (root is the root queue).
</description>
</property>
Fair Scheduler:就是公平调度器,能够公平地共享大型集群中的资源,Fair 调度器会为所有运行的 job 动态的调整系统资源。当只有一个 job 在运行时,该应用程序最多可获取所有资源,再提交其他 job 时,资源将会被重新分配分配给目前的 job,这可以让大量 job 在合理的时间内完成,减少作业 pending 的情况。可见 Fair Schedule 比较适用于多用户共享的大集群。
如果选择 Fair Schedule,需要配置 ResourceManager 使用 Fair Scheduler,即 conf/yarn-site.xml 中设置属性:
Fair Scheduler
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
调度配置文件 etc/hadoop/fair-scheduler.xml:
fair-scheduler.xml
<?xml version="1.0"?>
<allocations>
<queue name="sample_queue">
<minResources>10000 mb,0vcores</minResources>
<maxResources>90000 mb,0vcores</maxResources>
<maxRunningApps>50</maxRunningApps>
<maxAMShare>0.1</maxAMShare>
<weight>2.0</weight>
<schedulingPolicy>fair</schedulingPolicy>
<queue name="sample_sub_queue">
<aclSubmitApps>charlie</aclSubmitApps>
<minResources>5000 mb,0vcores</minResources>
</queue>
<queue name="sample_reservable_queue">
<reservation></reservation>
</queue>
</queue>
<queueMaxAMShareDefault>0.5</queueMaxAMShareDefault>
<queueMaxResourcesDefault>40000 mb,0vcores</queueMaxResourcesDefault>
<!-- Queue 'secondary_group_queue' is a parent queue and may have
user queues under it -->
<queue name="secondary_group_queue" type="parent">
<weight>3.0</weight>
<maxChildResources>4096 mb,4vcores</maxChildResources>
</queue>
<user name="sample_user">
<maxRunningApps>30</maxRunningApps>
</user>
<userMaxAppsDefault>5</userMaxAppsDefault>
<queuePlacementPolicy>
<rule name="specified" />
<rule name="primaryGroup" create="false" />
<rule name="nestedUserQueue">
<rule name="secondaryGroupExistingQueue" create="false" />
</rule>
<rule name="default" queue="sample_queue"/>
</queuePlacementPolicy>
</allocations>
展开源码
对比 Fari Scheduler 与 Capacity Scheduler:
随着 Hadoop 版本逐渐演化,Fair Scheduler 和 Capacity Scheduler 的功能越来越完善,因此两个调度器的功能也逐渐趋近,由于 Fair Scheduler 支持多种调度策略,因此可以认为 Fair Scheduler 具备了 Capacity Scheduler 的所有功能。
Capacity Scheduler 与 Fair Scheduler 比较表
Fair Scheduler(公平调度器)
实践与探索
通过分析常见的几种调度器,选用 Fair Schedule 调度器更适合共享型大集群,那么怎样的配置方案更适合多团队多用户呢?资源该按照什么比例分配给队列?用户的不同作业类型该如何区分?每个用户都希望自己可以享用更大的资源,又该如何保证成本问题?… 实际情况下遇到的问题不计其数,不同的集群规模和应用场景也有不同阶段的问题,都是需要经过探索与实践去逐一攻破。
Fair Scheduler 支持的自定义配置项
minResource:最小资源保证
maxResource:最多可以使用的资源
maxRunningApps:最多同时运行作业数量
minSharePreemptionTimeout:最小共享量抢占时间
schedulingMode/schedulingPolicy:队列采用的调度模式
aclSubmitApps:可在队列中提交作业的用户列表
aclAdministerApps:队列的管理员列表
userMaxJobsDefault:用户的 maxRunningJobs 属性默认值
defaultMinSharePreemptionTimeout:队列 minSharePreemptionTimeout 属性默认值
defaultPoolSchedulingMode:队列 schedulerMode 属性默认值
fairSharePreemptionTimeout:公平共享量抢占时间
fairSharePreemptionThreshold:队列的公平份额抢占阈值,默认值是 0.5f
allowPreemptionFrom:确定是否允许调度程序抢占队列中的资源,默认为 true
(另外通过配置 yarn-site.xml 的 yarn.scheduler.fair.preemption 可以控制集群是否开启抢占功能)
抢占:当某个队列中有剩余资源,调度器会将这些资源共享给其他队列,而当该队列中有新的应用程序提交时,调度器会为它回收资源。那些超额使用的行为即为超发。
划分队列组织结构
合理的队列组织方案也十分重要,如下图就是小米的队列组织模型:

一级队列:root 队列下面分为三大队列
离线分析 MR/Spark 作业队列:默认开启抢占,大量离线作业比较耗费资源,但是作业等级不算高,因此为了提高资源的利用率,可以允许在集群资源空闲的时候尽可能的超发资源,当然也意味着超发的资源会被回收;
在线计算流式作业队列:针对于作业等级较高的服务,为了保证资源需要设置不支持抢占,当然也需要设置最大超发限制,避免出现集群大作业独占集群资源;
资源池 reserved 队列:预留资源来保证新队列增加,或者其他队列的资源增配相当于资源池的概念,当然也可用于作业超发使用。
二级 / 三级 / 四级队列:
二级队列可对应公司组织架构下的各个部门,三级队列可以对应到部门下的各个 team,每个 team 当然也有会不同的提交作业类型分组这就是四级队列。
资源与成本优化
资源与成本永远是最难平衡的问题,那么针对于共享集群该如何去平衡?
通过我们逐渐探索与实践,采用了这样的方案:
业务队列资源配额:若干队列仅靠管理员的人工评估无法完成,既然队列是归属团队的,我们提供一套系统,开放部分队列配置项让用户申请修改,可以按照实际需求申请计算资源;管理员重心则放在保证集群整体健康上,同时让计算资源不再成为各业务部门的发展瓶颈。
计算资源成本优化:既然开放了资源申请,当然也需要让用户有节约资源的意识,减少由于申请不合理或者作业本身的问题导致资源浪费。比如根据用户的队列资源情况生成每月或者每周的虚拟账单 (按照申请的 cpu 和内存进行费用计算),虚拟账单主要用于帮助业务评估投入产出,以及队列的资源调整;针对队列还可以做资源和作业的监控,让用户清楚的知道自己哪些作业需要优化,队列需要调整。
总结
可能资源调度并没有最优解,需要不断探索实践去寻找适合目前现状的方案;在发展的不同阶段遇到不同的问题,通过解决问题逐渐去优化和完善。