python网络编程——缓存与消息队列
缓存与消息队列是解决, 服务负载较重时常用的两项技术,这两项技术都是非常强大的工具因而广为流行。
1.使用Memcached
Memcached意为“内存缓存守护进程”。Memcached将安装它的服务器上的空闲RAM与一个很大的近期最少使用的缓存结合使用,但Memcached缺乏认证以及安全管制,这代表应该将Memcached服务器放置在防火墙后。如果想在Python中使用Memcached需在终端运行:
pip install python3-memcached
服务器可以丢弃Memcached中的数据。Memcached实际上将重复计算花销较高的结果记录下来,以此来加速操作。下面的代码将展示Memcached的基本模式:在运行一个花销很大的整数平方操作前,代码首先会检查Memcached中是否已经保存了之前的计算过的答案。如果缓存中已经存在相应的答案,那么就不需要进行重复的计算,就能将答案返回。
#!/usr/bin/python
#coding:utf-8
import memcache,random,time,timeit
def compute_square(mc,n):
value = mc.get('sq:%d' % n)
if value is None:
time.sleep(0.001)
value = n * n
mc.set('sq:%d' % n,value)
return value
def main():
mc = memcache.Client(['127.0.0.1:11211'])
def make_request():
compute_square(mc,random.randint(0,5000))
print('Ten successive runs:')
for i in range(1,11):
print(' %.2fs' % timeit.timeit(make_request,number=2000),end='')
print()
if __name__ == '__main__':
main()
测试结果:

可以看到程序刚开始计算某个数的平方时,RAM(随机存取存储器)缓存中并没有存储过该整数的平方,因此必须进行计算程序运行时间较长。但是随着程序的运行,就会开始不断遇到一些相同的整数进行,此时缓存中已经存储了一些整数的平方,所以加快了运行速度。但是当Memcached存满或所有可能输入都已经计算过之后,速度就不在变化了。
2.散列与分区
当Memcached客户端得到包含多个Memcached实例列表时,会根据每个键的字符串的散列值对Memcached数据库进行分区 ,由计算出的散列值决定用Memcached集群中的那台服务器来存储特定的记录。我自己将它理解为生活中对物品的分类放着这样会方便自己快速找到需要的物品。下面是模仿英语词典的程序:
#!/usr/bin/python
#coding:utf-8
import hashlib
def alpha_shard(word):
if word[0] < 'g':
return 'server0'
if word[0] < 'n':
return 'server1'
if word[0] < 't':
return 'server2'
else:
return 'server3'
def hash_shard(word):
return 'server%d' % (hash(word) % 4)
def md5_shard(word):
data = word.encode('utf-8')
return 'server%d' % (hashlib.md5(data).digest()[-1] % 4)
if __name__ == '__main__':
words = open('words.txt').read().split()
for function in alpha_shard,hash_shard,md5_shard:
d = {'server0':0,'server1':0,'server2':0,'server3':0}
for word in words:
d[function(word.lower())] += 1
print(function.__name__[:-6])
for key,value in sorted(d.items()):
print("{} {} {:.2}".format(key,value,value / len(words)))
print()
第一个算法是将字母表分为4个大致平均的部分,并根据单词的首字母来分配键;另外两个算法使用了散列值。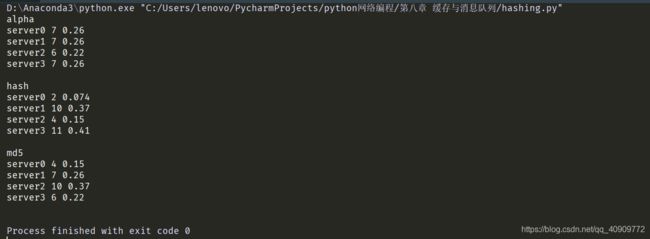
可以看到使用散列值进行查找的算法运行速度很快。
3.消息队列
“消息队列”是在消息的传输过程中保存消息的容器。消息队列管理器在将消息从它的源中继到它的目标时充当中间人。队列的主要目的是提供路由并保证消息的传递;如果发送消息时接收者不可用,消息队列会保留消息,直到可以成功地传递它。
在python中使用消息队列
下面的代码将使用蒙特卡洛方法(使用随机数或更常见的伪随机数来解决很多计算问题的方法)计算圆周率。下面是消息传递的拓扑:

bitsource生成的表示坐标轴的二进制字符串进行监听,always_yes监听模块只接受以00开始的字符串,然后直接生成结果Y,并推送给tally模块。judge模块会请求pythagoras模块计算两个整数坐标值的平方和,然后判断对应的点是否在第一象限的四分之一圆里,并根据结果奖T或F推送到输出队列中。
tally模块接受由每个随机串生成的T或F,通过计算T的数量与T和F总数的比值,就能估算出圆周率。
代码:
#!/usr/bin/python
#coding:utf-8
import random, threading, time, zmq
B = 32 #每个随机整数的精度位数
def ones_and_zeros(digits):
"""以至少'd'个二进制数字表示'n',不带特殊前缀。lstrip() 方法用于截掉字符串左边的空格或指定字符。
zfill() 方法返回指定长度的字符串,原字符串右对齐,前面填充0。getrandbits(n)以长整型形
式返回n个随机位(二进制数)"""
return bin(random.getrandbits(digits)).lstrip('0b').zfill(digits)
def bitsource(zcontext, url):
"""在单位平方中生成随机点。"""
zsock = zcontext.socket(zmq.PUB)
zsock.bind(url)
while True:
zsock.send_string(ones_and_zeros(B * 2))
time.sleep(0.01)
def always_yes(zcontext, in_url, out_url):
"""左下象限的坐标在单位圆内。"""
isock = zcontext.socket(zmq.SUB)
isock.connect(in_url)
isock.setsockopt(zmq.SUBSCRIBE, b'00')
osock = zcontext.socket(zmq.PUSH)
osock.connect(out_url)
while True:
isock.recv_string()
osock.send_string('Y')
def judge(zcontext, in_url, pythagoras_url, out_url):
"""确定每个输入坐标是否在单位圆内。"""
isock = zcontext.socket(zmq.SUB)
isock.connect(in_url)
for prefix in b'01', b'10', b'11':
isock.setsockopt(zmq.SUBSCRIBE, prefix)
psock = zcontext.socket(zmq.REQ)
psock.connect(pythagoras_url)
osock = zcontext.socket(zmq.PUSH)
osock.connect(out_url)
unit = 2 ** (B * 2)
while True:
bits = isock.recv_string()
n, m = int(bits[::2], 2), int(bits[1::2], 2)
psock.send_json((n, m))
sumsquares = psock.recv_json()
osock.send_string('Y' if sumsquares < unit else 'N')
def pythagoras(zcontext, url):
"""返回数字序列的平方和"""
zsock = zcontext.socket(zmq.REP)
zsock.bind(url)
while True:
numbers = zsock.recv_json()
zsock.send_json(sum(n * n for n in numbers))
def tally(zcontext, url):
"""计算单位圆内有多少点,然后打印p/q"""
zsock = zcontext.socket(zmq.PULL)
zsock.bind(url)
p = q = 0
while True:
decision = zsock.recv_string()
q += 1
if decision == 'Y':
p += 4
print(decision, p / q)
#args中保存的是没有利用的所有多余参数,保存方式为元组
def start_thread(function, *args):
thread = threading.Thread(target=function, args=args)
thread.daemon = True #你可以很容易地控制整个程序
thread.start()
def main(zcontext):
pubsub = 'tcp://127.0.0.1:6700'
reqrep = 'tcp://127.0.0.1:6701'
pushpull = 'tcp://127.0.0.1:6702'
start_thread(bitsource, zcontext, pubsub)
start_thread(always_yes, zcontext, pubsub, pushpull)
start_thread(judge, zcontext, pubsub, reqrep, pushpull)
start_thread(pythagoras, zcontext, reqrep)
start_thread(tally, zcontext, pushpull)
time.sleep(30)
if __name__ == '__main__':
main(zmq.Context())