白话空间统计二十九:空间插值(二)
前文再续,书接上一回……上回书说到,空间插值可以对数据进行估算,这一张我们来具体说说空间插值的一些概念。
首先,来说说插值的输入与输出问题。
首先输入的肯定是用来进行插值的观测点数据,一般来说都是点要素(ArcGIS也支持面插值),需要有空间位置和用于预测的属性值。如下所示,华北区主要城市的气温观测数据:
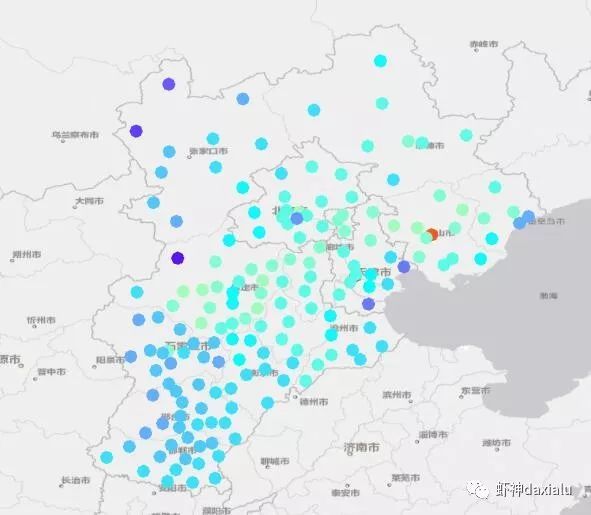
输出的结果一般来说,是一个连续的栅格数据,比如华北区某天的气温,如下所示:

有同学看见了之后,可能会问:为什么不直接生成矢量数据呢?比如生成点?实际上点数据在空间表达上面是一个离散的结构如下所示:
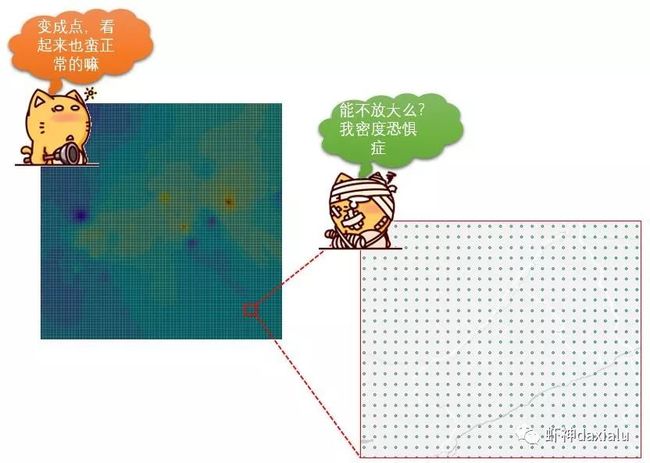
一旦放大,点与点之间就会出现缝隙,因为点结构本身是离散的,既然我们要进行预测,预测完了之后依然还留有空缺,那么不是等于工作未完成么,所以插值出来的结果,一般都采用连续的栅格进行存储。
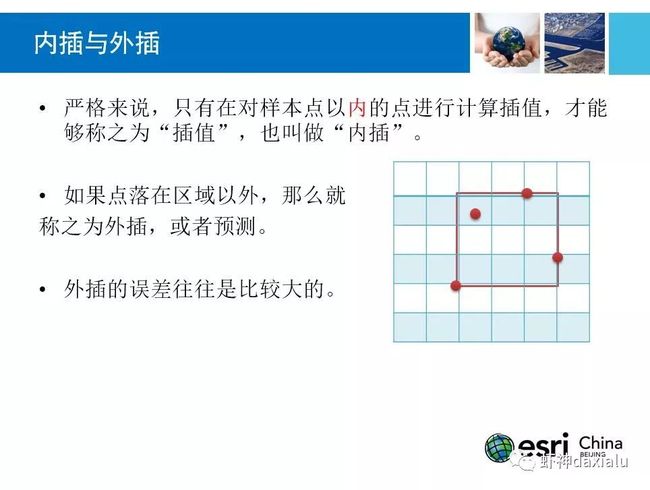
有些书里面,把插值叫做“内插法”,那么这个内插法的内,是什么意思呢?来看下面这这种情况:
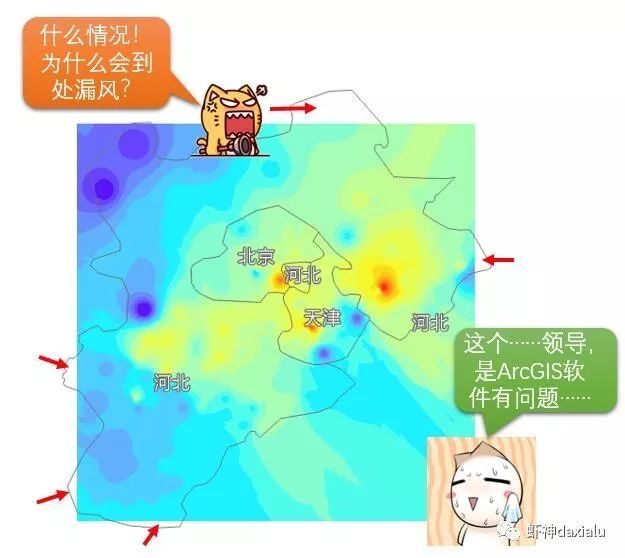
实际上我们只需要具体看看数据就会明白过来:
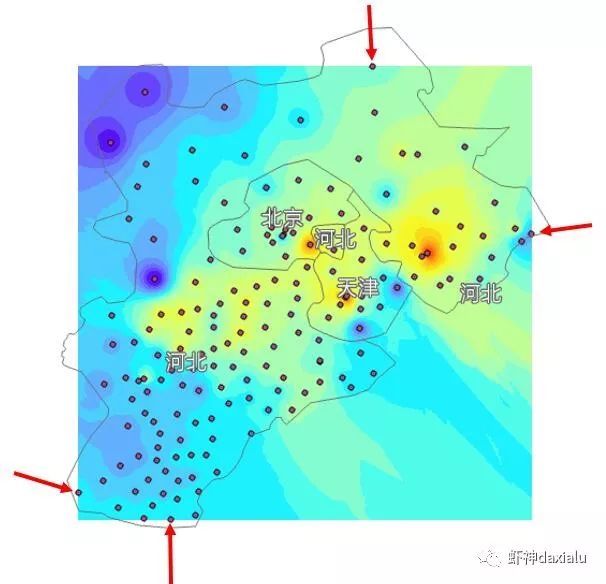
正好是以所有观测点的最大外接矩形为边界,这也就是内插法的“内”的由来:
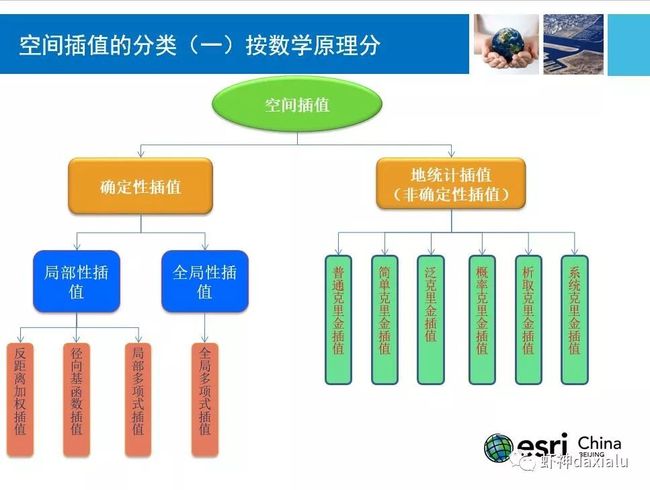
下面我们来看看各种插值方法的分类,首先是第一种分类方法:
首先看见数学这两字,就有很多同学开始瑟瑟发抖.gif了……但是别怕,按照虾神一贯的循循善诱(毁人不倦)的方式,是肯定不会列出一堆谁也看不懂的数学公式来说(zhuang)明(bi)的。
按照数学原理来分,会分成确定性插值和地统计插值(也可以叫非确定性),那么这个确定和非确定怎么理解呢?

首先看看确定性插值是啥?官方的说法是:确定性插值是以研究区域内的相似性,或者以平滑度为基础,由已知样点来创建连续的栅格表面的插值方法。
地统计方法利用的是已知样点的统计特性,以变异函数理论和结构分析为基础,在有限区域内对区域化变量进行无偏最优估计的一种方法。
好吧,看完这两个官宣概念,想想大家和虾神一样,已经眼冒金星了……
实际上并没有那么玄乎,把上面两个概念,用人话来说,就是:
1、确定性的插值,就是确信研究区域内所有的点都和你有关系,然后根据距离来决定对你的影响……或者是根据每个点高低起伏不同来决定你把你放到哪个位置上:
距离来决定影响程度:
从空间分析的原理上来看,万事万物之间都是有关系的,只是关系的强弱会根据距离的不同而不同……所以确定性插值就贯彻了这个基本的思想,所有(研究范围内)的样本点,都与要插值的位置有关系(PS:我管你是喵星人还是汪星人……出现就相关)。
除了距离,还有一些插值方法是与平滑度有关的,比如样条函数插值(立个Flag,这个一个灰常灰常有意思的插值方法,后面我会详细说到):

样条函数会生成一个曲线,那么插值的时候就正好是把距离与这个曲面所表示的值带入就可以了,不同的距离产生的影响与平滑度有密切相关。
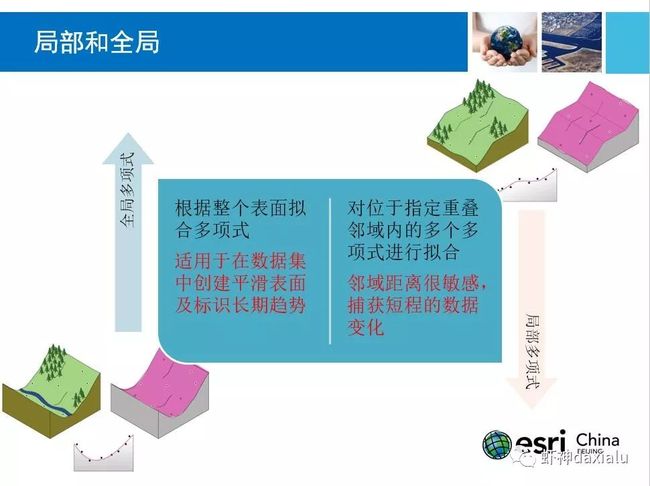
而确定性插值,又分为局部和全局两种,这个两个就比较好理解了,如下图所示:
那么地统计插值是啥意思?地统计插值是地统计学里面的一个具体内容,后面会专门将地统计学相关的插值,这里就提一个概念,为什么他和确定性插值不一样。
因为地统计学插值的核心,除了关注地理学第一定律里面的万事皆相关以外,还关注了数据的空间分布特征:如果是一直看虾神空间统计的同学都知道,数据的空间分布特征,主要有三种:

不同数据分布的情况下,实际上插值的计算应该是有不一样的,比如出现了随机的特性,那么你插值的可信度肯定要大打折扣……这个在后面讲地统计插值的时候还会继续详细叙述(又是一个Flag)。
所以地统计插值的核心,在于除了使用空间距离来进行加权以外,还会考虑数据的空间自相关表达出来的分布特征,所以在计算的时候,引入了变异函数,而变异函数就是地统计插值的理论研究核心。
那么第二种分类方法,就比较简单了,按照能否经过所有的采样点来分:

啥叫经过所有的创建点呢,也就是插值的结果栅格,会与采样点重合:

如上图所示,反距离权重插值法中,插值的结果,与插值样本的位置重合的时候,取出来的值也完全一样。
而地统计插值的时候:
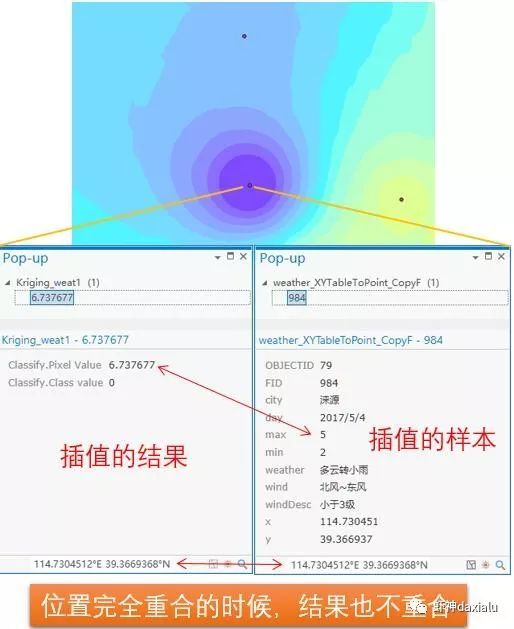
非精确性插值,在位置完全重合的时候,采样点与插值结果,一般也不相同。
有同学说,那非精确性插值这不就是错的了么……实际上非精确性插值是属于一种局部窗口的平滑插值,他可以有效的避免结果出现严重的波峰或者波谷——即他可以有效的处理异常值。
但是二者之间到底孰是孰非,就仁者见仁智者见智了。
说完分类,从下一篇开始,我们就开始说各种不同的插值方式,同时,大家关心的手算插值全流程,也会慢慢的展现……
(待续未完)