利用python进行保险数据分析及可视化
前言
现在数据分析在各个行业都在广泛的使用,尤其由于python语言的简便、高效性,在一些中小型企业的实际应用中逐渐替代excel公式、透视图等传统方式。网上各种博客论坛这类文章很多,但保险行业的数据分析文章相对较少,笔者正好是保险行业的,有一些计算机编程基础,写了这篇博文,希望与大家共同进步学习。
几乎所有的数据分析都需要经历以下五步:
一、明确问题
二、理解数据
三、数据清洗
四、数据分析和可视化
五、结论和建议
一、明确问题
本文原始数据是基于一个54517条的历史车险保单的csv文件,由于涉及行业保密消息,选取了时间相对“较远”的2015年的数据。
由于本篇仅是对保险行业数据分析的一个初探,旨在共同学习交流,所以提出的统计分析问题相对维度较少,包含以下三个方面:
-
1、车辆使用年限中保费排在前十的
-
2、保费前十的起保日期
-
3、用户消费行为(购买次数)
二、理解数据
1、先导入基础库,使用python的pandas和numpy库
import pandas as pd
import numpy as np
2、导入基础数据
data=pd.read_csv('2015-01.csv')3、查看data数据的第一行
data.head(1)
4、查看data数据字段信息
data.info()
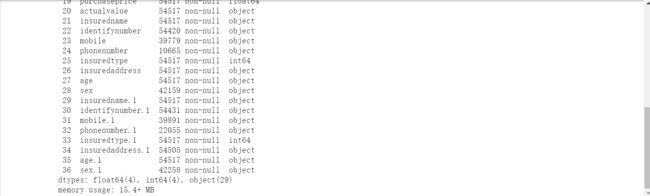
这是一个拥有54517行,37个字段的数据, 部分字段有缺省值。能与本文分析相关的字段有:sumpremium保费、startdate起保时间、insuredname被保险人、licenseno车牌号等。
三、数据清洗
在上一步中可以看到,startdate起保时间的数据类型是object,我们首先需要把该字段格式修改为日期格式
data['startdate']=pd.to_datetime(data['startdate'],errors='coerce') #将startdate由str格式修改成日期格式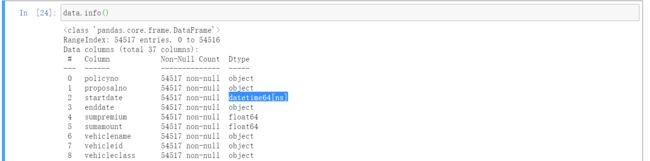
由于我们需要的字段都没有缺省值,所以处理缺省值这一步我们省了,但在实际工作中原始数据会有一些字段有缺省值和异常值,常用的处理方法有:
data.dropna() #只要行中有一个缺失值就会删除该行
data.dropna(how='all',axis=0) #行中全部为缺失值则删除
data.dropna(subset=['mobile.1','phonenumber.1'],how='all',axis=0) #行中其中两个字段为缺失值则删除
data['age.1'].fillna(df['age.1'].mean()) #均值填补法
data['age.1'].fillna(df['age.1'].median()) #中位数填补法
data['age.1'].fillna(df['age.1'].mode()[0]) #众数填补法
data['age.1'].fillna(100) #全用某一个值填补
。。。。。。。
四、数据分析及可视化
1、车辆使用年限中保费排在前十的
数据清洗完毕后,下面就需要写python语句来呈现分析结果。车辆使用年限是useyears字段,保费是sumpremium字段,我们需要使用groupby语句,以useyears维度来呈现保费的sum信息,并显示前10名,故coding如下:
sumpremium_first10=data[data['sumpremium']>0].groupby('insuredname')\
.sum()['sumpremium'].sort_values(ascending=False).head(10)查看计算结果:
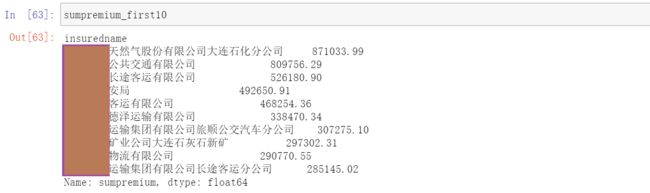
进行可视化作图:
导入plotly可视化库
import plotly as py
import plotly.graph_objs as go
py.offline.init_notebook_mode()
pyplot=py.offline.iplottrace_basic是数据,layout是布局。
trace_basic=[go.Bar(x=sumpremium_first10.index.tolist(),y=sumpremium_first10.values.tolist(),marker=dict(color='orange'),opacity=0.5)]
layout=go.Layout(title='保费前10名客户',xaxis=dict(title='客户'))
figure_basic=go.Figure(data=trace_basic,layout=layout)
pyplot(figure_basic)最终效果图如下:(关键信息已打码)

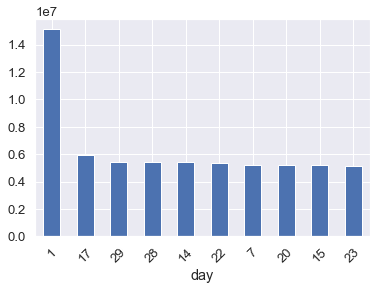
2、保费前十的起保日期
添加一个day字段来展示具体日期
data['day']=data['startdate'].dt.day #添加一个字段显示日期使用groupby函数,根据新建的day日期维度来统计保费和,并取前十名
sumpremium_first10day=data[data['sumpremium']>0]\
.groupby('day').sum()['sumpremium'].sort_values(ascending=False).head(10)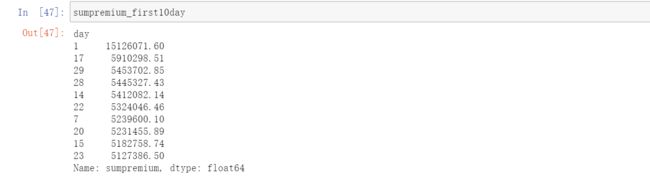
这次我们使用Python中的另一个可视化库seaborn来作图
导入seaborn库,设置背景格式
import seaborn as sns
sns.set(style='darkgrid',context='notebook',font_scale=1.2)做柱状图,并将横坐标轴刻度置成45度
sumpremium_first10day.plot(kind='bar')
plt.xticks(rotation=45)最终可视化图如下:
3、用户消费行为(购买次数)
这次行为分析,我们不做图,做类似excel的透视图进行呈现。
分析购买次数,要根据被保险人名称的维度进行分组分类,并要排除同一个保险人同一个车牌号的多次投保,熟悉车险的可能知道,同一个被保险人投保同一辆车大多需要投保一个商业、一个交强险,这个在系统里是用两行不同的数据来显示的。
故python代码如下:
customer=data[data['sumpremium']>0].groupby('insuredname')\
.agg({'licenseno':'nunique','sumpremium':np.sum}) #根据车牌号去重进行数据详细描述
customer.describe()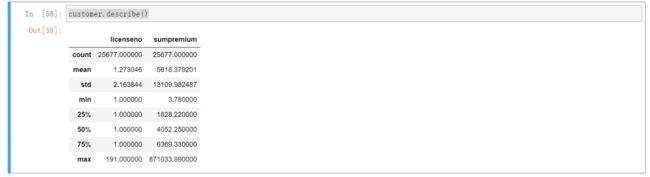
五、结论和建议
根据上面三个不同维度的分析,得到的初步分析结果如下:
- 用户平均投保车辆1.27台,最高客户投保了191台,该客户是企业的忠实客户。
- 用户平均消费金额5818元,50%的用户平均消费4052元,而75%的客户消费6369元,说明至少有25%的用户消费金额远大于平均用户,这类客户要着重维护。
- 月初1号是投保的最高峰,保费量远超其他日期,要合理安排月初的人力。
尾记
本博文利用python对保险行业的数据进行简单的分析,走了一遍全流程。使用了pandas、numpy库进行数据读取、清洗、计算和分析,并分别调用了plotly、seaborn库进行可视化绘图。为了方便演示,分析的维度不多,逻辑相对简单,旨在与大家共同交流学习!希望python语言能在保险行业的日常统计分析工作中发扬光大!