序列比对(十六)——Baum-Welch算法估算HMM参数
原创:hxj7
本文介绍了如何用Baum-Welch算法来估算HMM模型中的概率参数。
Baum-Welch算法应用于HMM的效果
前文《序列比对(15)EM算法以及Baum-Welch算法的推导》介绍了EM算法和Baum-Welch算法的推导过程。Baum-Welch算法是EM算法的一个特例,用来估算HMM模型中的概率参数。其具体步骤如下:

本文给出了Baum-Welch算法的C代码,还是以投骰子为例,估算出了转移概率以及发射概率。
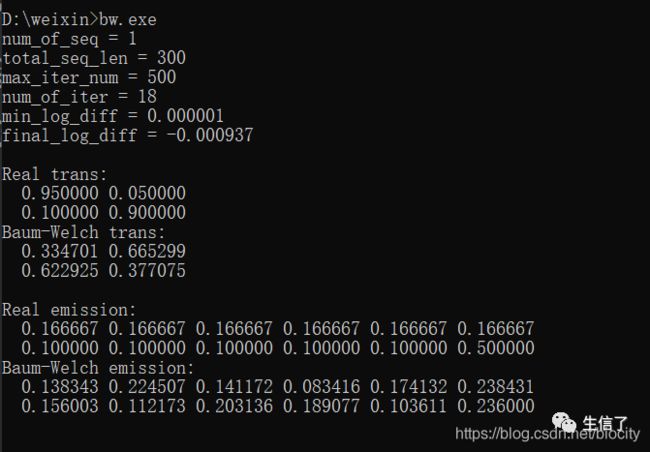
具体效果如图:
(下面几张图中的 Real 表示真实的转移概率以及发射概率,而Baum-Welch表示用Baum-Welch算法估算的转移概率以及发射概率。)
首先是当若干条序列总长度为300时:


然后是当若干条序列总长度为30000时:


可以看出总长度为30000时已经很接近真实值了。但是,Baum-Welch算法的结果时一个局部最优值,很依赖初始值的设定。所以,当初始值不同时,也有可能会出现这种结果:

小结一下:
- Baum-Welch算法通过多次迭代来估算HMM模型中的概率参数。
- 本文代码设定了迭代的终止条件:当“归一化后的平均对数似然”的变化小于预先设定的阈值时或者迭代次数超出最大迭代次数时,迭代终止。
- Baum-Welch算法的最终结果非常依赖初始值的设定。
- 本文代码中的初始值是随机值。
- 在计算期望次数时,使用了伪计数。
代码中所用公式及其推导
其中的 A k l A_{kl} Akl指的是 a k l a_{kl} akl在所有训练序列中出现的期望次数,而 E k ( b ) E_k(b) Ek(b)指的是 e k ( b ) e_k(b) ek(b)在所有训练序列中出现的期望次数。用符号表示就是(其中 x j x^j xj表示第j条符号序列):
(1.1) A k l = ∑ j ∑ π P ( π j ∣ x j , θ ) A k l ( π j ) = ∑ j ∑ i P ( π i j = k , π i + 1 j = l ∣ x j , θ ) \begin{aligned} \displaystyle A_{kl} & = \sum_{j} \sum_{\pi} P(\pi^j|x^j,\theta) A_{kl}(\pi^j) \\ & = \sum_{j} \sum_i P(\pi_i^j=k, \pi_{i+1}^j=l|x^j,\theta) \tag{1.1} \end{aligned} Akl=j∑π∑P(πj∣xj,θ)Akl(πj)=j∑i∑P(πij=k,πi+1j=l∣xj,θ)(1.1)
(1.2) E k ( b ) = ∑ j ∑ π P ( π j ∣ x j , θ ) E k ( b , π j ) = ∑ j ∑ i P ( π i j = k , x i j = b ∣ x j , θ ) = ∑ j ∑ { i ∣ x i j = b } P ( π i j = k ∣ x j , θ ) \begin{aligned} \displaystyle E_k(b) & = \sum_j \sum_\pi P(\pi^j|x^j, \theta) E_k(b, \pi^j) \\ & = \sum_{j} \sum_i P(\pi_i^j=k, x_i^j=b|x^j,\theta) \\ & = \sum_{j} \sum_{\{i|x_i^j=b\}} P(\pi_i^j=k|x^j,\theta) \tag{1.2} \end{aligned} Ek(b)=j∑π∑P(πj∣xj,θ)Ek(b,πj)=j∑i∑P(πij=k,xij=b∣xj,θ)=j∑{i∣xij=b}∑P(πij=k∣xj,θ)(1.2)
我们可以推导出,对某一条序列 x j x^j xj有如下结论:
(2.1) P ( π i = k , π i + 1 = l ∣ x , θ ) = f ~ k ( i ) a k l e l ( x i + 1 ) b ~ l ( i + 1 ) P(\pi_i=k, \pi_{i+1}=l|x,\theta) = \tilde{f}_k(i) a_{kl} e_l(x_{i+1}) \tilde{b}_l(i+1) \tag{2.1} P(πi=k,πi+1=l∣x,θ)=f~k(i)aklel(xi+1)b~l(i+1)(2.1)
(2.2) P ( π i = k ∣ x , θ ) = f ~ k ( i ) b ~ k ( i ) s i P(\pi_i=k|x,\theta) = \tilde{f}_k(i) \tilde{b}_k(i) s_i \tag{2.2} P(πi=k∣x,θ)=f~k(i)b~k(i)si(2.2)
其中 f ~ k ( i ) \tilde{f}_k(i) f~k(i)、 b ~ k ( i ) \tilde{b}_k(i) b~k(i) 以及 s i s_i si 的定义在前文《序列比对(12):计算后验概率》中已经给出(下文给出了计算公式)。
公式(2.1)的推导如下:
P ( π i = k , π i + 1 = l ∣ x , θ ) = P ( π i = k , π i + 1 = l , x ∣ θ ) P ( x ∣ θ ) = P ( π i = k , π i + 1 = l , x 1 , . . . , x i , x i + 1 , . . . , x L ∣ θ ) P ( x ∣ θ ) = P ( x 1 , . . . , x i , π i = k ∣ θ ) P ( x i + 1 , . . . , x L , π i + 1 = l ∣ x 1 , . . . , x i , π i = k , θ ) P ( x ∣ θ ) = f k ( i ) P ( x i + 1 , . . . , x L , π i + 1 = l ∣ x 1 , . . . , x i , π i = k , θ ) P ( x ∣ θ ) = f k ( i ) P ( x i + 1 , . . . , x L , π i + 1 = l ∣ π i = k , θ ) P ( x ∣ θ ) = f k ( i ) P ( x i + 2 , . . . , x L , π i + 1 = l ∣ x i + 1 , π i + 1 = l , π i = k , θ ) P ( x i + 1 , π i + 1 = l ∣ π i = k , θ ) P ( x ∣ θ ) = f k ( i ) P ( x i + 2 , . . . , x L , π i + 1 = l ∣ π i + 1 = l , θ ) P ( x i + 1 , π i + 1 = l ∣ π i = k , θ ) P ( x ∣ θ ) = f k ( i ) b l ( i + 1 ) P ( x i + 1 , π i + 1 = l ∣ π i = k , θ ) P ( x ∣ θ ) = f k ( i ) b l ( i + 1 ) P ( π i + 1 = l ∣ π i = k , θ ) P ( x i + 1 ∣ π i = k , π i + 1 = l , θ ) P ( x ∣ θ ) = f k ( i ) b l ( i + 1 ) a k l P ( x i + 1 ∣ π i + 1 = l , θ ) P ( x ∣ θ ) = f k ( i ) b l ( i + 1 ) a k l e l ( x i + 1 ) P ( x ∣ θ ) \begin{aligned} & P(\pi_i=k, \pi_{i+1}=l|x,\theta) \\ & = \frac {P(\pi_i=k, \pi_{i+1}=l,x|\theta)} {P(x|\theta)} \\ & = \frac {P(\pi_i=k, \pi_{i+1}=l, x_1, ..., x_i, x_{i+1},...,x_L|\theta)} {P(x|\theta)} \\ & = \frac {P(x_1,...,x_i,\pi_i=k|\theta) P(x_{i+1},...,x_L,\pi_{i+1}=l|x_1,...,x_i,\pi_i=k,\theta)} {P(x|\theta)} \\ & = \frac {f_k(i) P(x_{i+1},...,x_L,\pi_{i+1}=l|x_1,...,x_i,\pi_i=k,\theta)}{P(x|\theta)} \\ & = \frac {f_k(i) P(x_{i+1},...,x_L,\pi_{i+1}=l|\pi_i=k,\theta)}{P(x|\theta)} \\ & = \frac {f_k(i) P(x_{i+2},...,x_L,\pi_{i+1}=l|x_{i+1},\pi_{i+1}=l,\pi_i=k,\theta) P(x_{i+1},\pi_{i+1}=l|\pi_i=k,\theta)}{P(x|\theta)} \\ & = \frac {f_k(i) P(x_{i+2},...,x_L,\pi_{i+1}=l|\pi_{i+1}=l,\theta) P(x_{i+1},\pi_{i+1}=l|\pi_i=k,\theta)} {P(x|\theta)} \\ & = \frac {f_k(i) b_l(i+1) P(x_{i+1},\pi_{i+1}=l|\pi_i=k,\theta)} {P(x|\theta)} \\ & = \frac {f_k(i) b_l(i+1) P(\pi_{i+1}=l|\pi_i=k,\theta) P(x_{i+1}|\pi_i=k,\pi_{i+1}=l,\theta)} {P(x|\theta)} \\ & = \frac {f_k(i) b_l(i+1) a_{kl} P(x_{i+1}|\pi_{i+1}=l,\theta)} {P(x|\theta)} \\ & = \frac {f_k(i) b_l(i+1) a_{kl} e_l(x_{i+1})} {P(x|\theta)} \end{aligned} P(πi=k,πi+1=l∣x,θ)=P(x∣θ)P(πi=k,πi+1=l,x∣θ)=P(x∣θ)P(πi=k,πi+1=l,x1,...,xi,xi+1,...,xL∣θ)=P(x∣θ)P(x1,...,xi,πi=k∣θ)P(xi+1,...,xL,πi+1=l∣x1,...,xi,πi=k,θ)=P(x∣θ)fk(i)P(xi+1,...,xL,πi+1=l∣x1,...,xi,πi=k,θ)=P(x∣θ)fk(i)P(xi+1,...,xL,πi+1=l∣πi=k,θ)=P(x∣θ)fk(i)P(xi+2,...,xL,πi+1=l∣xi+1,πi+1=l,πi=k,θ)P(xi+1,πi+1=l∣πi=k,θ)=P(x∣θ)fk(i)P(xi+2,...,xL,πi+1=l∣πi+1=l,θ)P(xi+1,πi+1=l∣πi=k,θ)=P(x∣θ)fk(i)bl(i+1)P(xi+1,πi+1=l∣πi=k,θ)=P(x∣θ)fk(i)bl(i+1)P(πi+1=l∣πi=k,θ)P(xi+1∣πi=k,πi+1=l,θ)=P(x∣θ)fk(i)bl(i+1)aklP(xi+1∣πi+1=l,θ)=P(x∣θ)fk(i)bl(i+1)aklel(xi+1)
同时,由我们知道:
f k ( i ) = f ~ k ( i ) ∏ r = 1 i s r b k ( i ) = b ~ k ( i ) ∏ r = i L s r P ( x ) = ∏ r = 1 L s r \displaystyle f_k(i) = \tilde{f}_k(i) \prod_{r=1}^{i} s_r \\ \displaystyle b_k(i) = \tilde{b}_k(i) \prod_{r=i}^{L} s_r \\ \displaystyle P(x) = \prod_{r=1}^L s_r fk(i)=f~k(i)r=1∏isrbk(i)=b~k(i)r=i∏LsrP(x)=r=1∏Lsr
所以:
P ( π i = k , π i + 1 = l ∣ x , θ ) = f k ( i ) b l ( i + 1 ) a k l e l ( x i + 1 ) P ( x ∣ θ ) = [ f ~ k ( i ) ∏ r = 1 i s r ] [ b ~ l ( i + 1 ) ∏ r = i + 1 L s r ] a k l e l ( x i + 1 ) ∏ r = 1 L s r = f ~ k ( i ) a k l e l ( x i + 1 ) b ~ l ( i + 1 ) \begin{aligned} P( & \pi_i=k, \pi_{i+1}=l|x,\theta) \\ & = \frac {f_k(i) b_l(i+1) a_{kl} e_l(x_{i+1})} {P(x|\theta)} \\ & = \frac {\bigg[ \tilde{f}_k(i) \displaystyle \prod_{r=1}^{i} s_r \bigg] \bigg[ \tilde{b}_l(i+1) \prod_{r=i+1}^{L} s_r \bigg] a_{kl} e_l(x_{i+1})} {\displaystyle \prod_{r=1}^L s_r} \\ & = \tilde{f}_k(i) a_{kl} e_l(x_{i+1}) \tilde{b}_l(i+1) \end{aligned} P(πi=k,πi+1=l∣x,θ)=P(x∣θ)fk(i)bl(i+1)aklel(xi+1)=r=1∏Lsr[f~k(i)r=1∏isr][b~l(i+1)r=i+1∏Lsr]aklel(xi+1)=f~k(i)aklel(xi+1)b~l(i+1)
公式(2.2)的证明已经在前文《序列比对(12):计算后验概率》中给出过了。
由式子(1.1)、(1.2)、(2.1)、(2.2),我们可以得到:
(3.1) A k l = ∑ j ∑ i f ~ k j ( i ) a k l e l ( x i + 1 j ) b ~ l j ( i + 1 ) \displaystyle A_{kl} = \sum_{j} \sum_i \tilde{f}^{j}_k(i) a_{kl} e_l(x^j_{i+1}) \tilde{b}^j_l(i+1) \tag{3.1} Akl=j∑i∑f~kj(i)aklel(xi+1j)b~lj(i+1)(3.1)
(3.2) E k ( b ) = ∑ j ∑ { i ∣ x i j = b } f ~ k j ( i ) b ~ k j ( i ) s i j \displaystyle E_k(b) = \sum_{j} \sum_{\{i|x_i^j=b\}} \tilde{f}^j_k(i) \tilde{b}^j_k(i) s^j_i \tag{3.2} Ek(b)=j∑{i∣xij=b}∑f~kj(i)b~kj(i)sij(3.2)
实际上,代码中使用了状态0,构建了初始概率向量。假设以B代表初始向量的“转移”期望次数,那么它是 A k l A_{kl} Akl当k=0时的一个特例:
(3.3) B 0 l = ∑ j b ~ l j ( 1 ) a 0 l e l ( x 1 j ) \displaystyle B_{0l} = \sum_j \tilde{b}^j_l(1) a_{0l} e_l(x^j_1) \tag{3.3} B0l=j∑b~lj(1)a0lel(x1j)(3.3)
由于我们使用了伪计数 r k l r_{kl} rkl 以及 r k ( b ) r_k(b) rk(b),所以:
(4.1) A k l ′ = A k l + r k l A'_{kl} = A_{kl} + r_{kl} \tag{4.1} Akl′=Akl+rkl(4.1)
(4.2) E k ′ ( b ) = E k ( b ) + r k ( b ) E'_{k}(b) = E_{k}(b) + r_{k}(b) \tag{4.2} Ek′(b)=Ek(b)+rk(b)(4.2)
(4.3) B 0 l ′ = B 0 l + r 0 l B'_{0l} = B_{0l} + r_{0l} \tag{4.3} B0l′=B0l+r0l(4.3)
最终,我们可以估算转移概率和发射概率:
(5.1) a k l = A k l ′ ∑ l ′ A k l ′ ′ a_{kl} = \frac {A'_{kl}} {\displaystyle \sum_{l'} A'_{kl'}} \tag{5.1} akl=l′∑Akl′′Akl′(5.1)
(5.2) e k ( b ) = E k ′ ( b ) ∑ b ′ E k ′ ( b ′ ) e_k(b) = \frac {E'_k(b)} {\displaystyle \sum_{b'} E'_k(b')} \tag{5.2} ek(b)=b′∑Ek′(b′)Ek′(b)(5.2)
本文代码实际使用的计算公式就是(5.1)和(5.2)。
具体代码
具体代码如下:
(本文代码利用结构体重新梳理了过程,与之前文章中的代码相比,更工整了。)
#include (公众号:生信了)