- 前言
- 概念
- 链表的设计
- 完整代码
- List接口
- 抽象父类设计
- 链表—LinkedList
- 虚拟头结点
- 概念
- 结构设计
- 方法变动
- 双向链表
- 概念
- 双向链表设计
- 方法变动
- 循环链表
- 单向循环链表
- 双向循环链表
- 小结
- 单向链表 VS 双向链表
- 动态数组 VS 链表
- 声明
前言
在前面的实现的动手写个Java动态数组里,虽然对于用户而言,看是实现了动态扩容的功能,实际上,只是依托底层写的方法ensureCapacity在数组容量不足的时候,对重新申请一个原数组1.5倍容量的新数组,再将原有数组中存放的元素复制到新数组来,数组指针指向新数组,从根本上来说,这并不是真正的动态。
同时,数组的拷贝,以及数组申请的空间并未全部存储元素,会降低效率,也会造成内存空间的浪费,但这对于链表来说,并不是个问题,链表是做到了用多少内存就申请多少内存空间,这才是真正的动态数据结构。
概念
什么是链表?
链表是一种链式存储的线性表,所有元素的内存地址不一定是连续的
链表的结构
对链表而言,数据是存储在“结点”(Node)中的,可以使用一个数据域来存储数据,这里我称为 element;然后结点中还有一个用来指向下一个结点位置的结点域,一般称为 next。而对于链表的结尾,一般是以 NULL 作为结尾,所以链表中的最后一个结点的结点域 next 指向的是 NULL,图示链表结构:
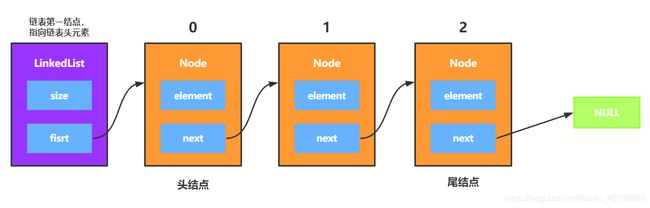
链表的设计
/**
* 定义链表第一结点,指向链表头一个元素
*/
private Node first;
/**
* 定义结点类Node,包含元素和指向下一个结点的地址引用
* @param
*/
private static class Node{
E element;
Node next;
public Node(E element, Node next) {
this.element = element;
this.next = next;
}
}
Node类是链表中结点的定义,first节点,size并不是存储链表元素,而是用于存储链表的元素数量,在上一节动手实现Java动态数组的时候说到了,链表的大部分接口和动态数组是一致的,Java语言长久不衰的原因有一点就是使用Java这种静态编译型的语言能够写出可维护性高的代码,提倡OCP原则,面向接口编程,面向抽象编程。
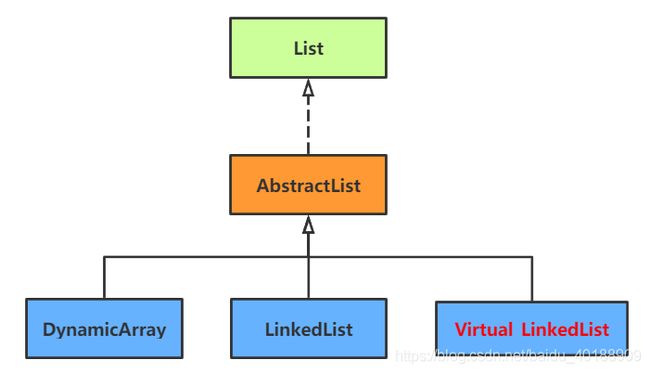
在这里把链表和动态数组是一致的方法及属性抽取成List接口和AbstractList抽象类,画一下类图关系:

List接口中定义的属性与方法
1、属性:
int ELEMENT_NOT_FOUND = -1;—— 查无元素的返回标志
2、接口方法:
int size();—— 查询当前链表元素的数量boolean isEmpty();—— 判断链表是否为空E set(int index, E element);—— 设置index位置的元素E get(int index);—— 获取index位置的元素boolean contains(E element);—— 是否包含element元素int indexOf(E element);—— 查看元素的索引void add(E element);—— 添加元素到尾部void add(int index, E element);—— 在index位置插入一个元素E remove(int index);—— 删除index位置的元素void clear();—— 清除所有元素
AbstractList抽象类定义的属性与方法
将不影响编码的共同方法,在抽象类AbstractList实现,其他方法放到链表类LinkedList或动态数组DynamicArray具体编码实现,这样做的好处就是,提高了代码的复用性和可维护性
1、属性:
protected int size;—— 查无元素的返回标志
2、抽象类方法:
int size();—— 查询当前链表元素的数量boolean isEmpty();—— 判断链表是否为空boolean contains(E element);—— 是否包含element元素void add(E element);—— 添加元素到尾部protected void outOfBounds(int index)—— 非法索引访问抛出异常protected void rangeCheck(int index)—— 索引检查函数protected void rangeCheckForAdd(int index)—— 添加元素的索引检查函数
LinkedList链表类定义的属性与方法
1、属性
private Node—— 定义链表第一结点,指向链表头一个元素first;
2、方法
E set(int index, E element);—— 设置index位置的元素E get(int index);—— 获取index位置的元素int indexOf(E element);—— 查看元素的索引void add(int index, E element);—— 在index位置插入一个元素E remove(int index);—— 删除index位置的元素public E remove(E element);—— 删除指定元素void clear();—— 清除所有元素private Node—— 获取index位置对应的结点对象node(int index)
完成设计后,是具体的方法编码实现,一些简单的方法在这里就不作解释了,注释已经很清楚了,这里讲一些重点的方法
链表初始化
定义在LinkedList 中的private Node 以及抽象父类AbstractList中的protected int size;是组成链表的第一结点,在没有添加元素结点之前,它的值是这样的:
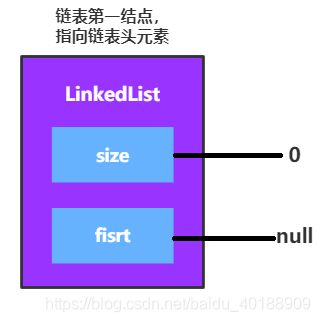
再看一下void add(int index, E element);方法,这是向指定索引添加元素的方法,我们往指定索引添加元素时,需要找到该索引前的节点,再修改指针指向,完成添加元素结点的操作,将该操作提取成private Node方法。
讲一下node方法吧,首先这里,我们要明白,first是一个地址引用,也就是链表第一节结点,如果size为0,first指向的是null,如果size不为0,则指向的是链表头结点,来看看node的代码实现:
/**
* 获取index位置对应的结点对象
* @param index
* @return
*/
private Node node(int index){
rangeCheck(index);
Node node = first;
for (int i = 0; i < index; i++) {
node = node.next;
}
return node;
}
要查找index索引位置的结点,从first出发,需要next寻找index次,例如我们查找索引为2的结点,过程如下图:
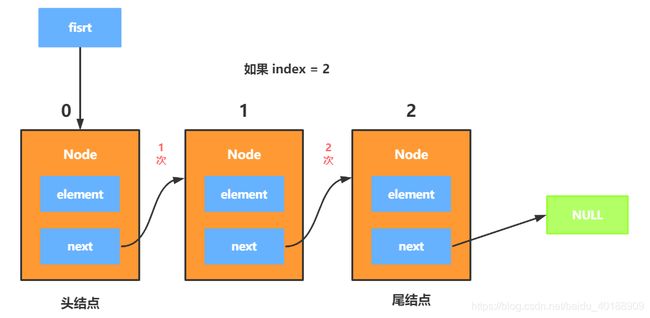
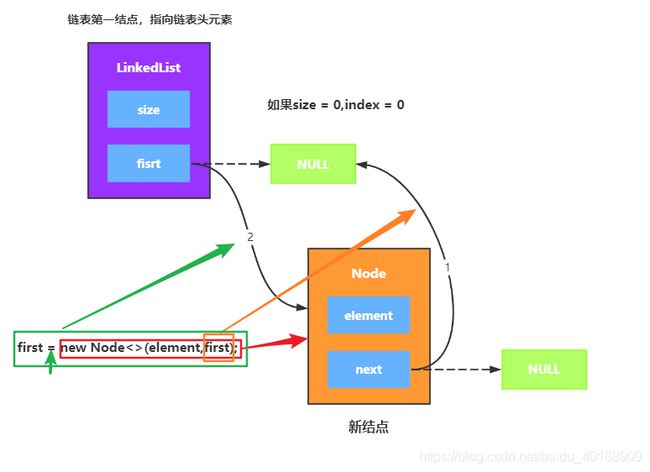
讲完上面的方法,回到add方法,添加的过程是将新结点指向要插入的索引结点,修改索引前一结点的指向,将其指向新结点,然后size++,这里依据index = 0条件成立与否要划分两种情况,因为index = 0 ,前面是没有元素结点的,只有first节点地址引用,上代码,分析:
/**
* 在index位置插入一个元素
*
* @param index
* @param element
*/
@Override
public void add(int index, E element) {
rangeCheckForAdd(index);
if (index == 0){
first = new Node<>(element,first);
}else {
Node prev = node(index - 1);
prev.next = new Node<>(element,prev.next);
}
size++;
}
如果index != 0,就很好理解了,先是Node,找到索引位置的前一结点,然后修改指针指向,prev.next = new Node<>(element,prev.next);,画图解释:
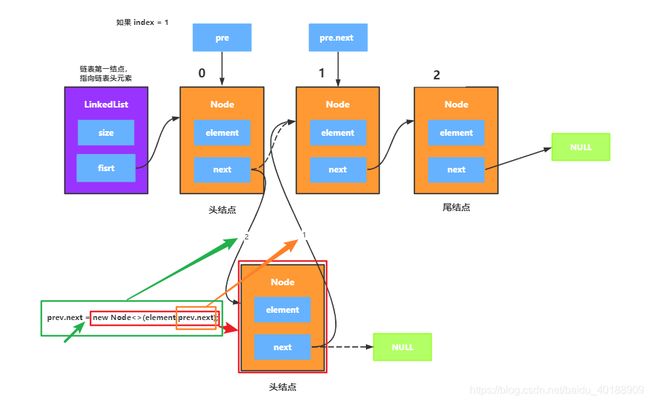
当然index = 0 ,也是很好理解的,这里以size = 0,index = 0 为例,画图演示:
删除结点,和添加的原理是差不多的,这里就不画图解说了。看完上面对于几个重点方法的分析后,相信对于上面链表的结构就不会带有疑惑了
完整代码
List接口
public interface List {
//查无元素的返回标志
int ELEMENT_NOT_FOUND = -1;
/**
* 元素的数量
* @return
*/
int size();
/**
* 是否为空
* @return
*/
boolean isEmpty();
/**
* 设置index位置的元素
* @param index
* @param element
* @return 原来的元素ֵ
*/
E set(int index, E element);
/**
* 获取index位置的元素
* @param index
* @return
*/
E get(int index);
/**
* 是否包含某个元素
* @param element
* @return
*/
boolean contains(E element);
/**
* 查看元素的索引
* @param element
* @return
*/
int indexOf(E element);
/**
* 添加元素到尾部
* @param element
*/
void add(E element);
/**
* 在index位置插入一个元素
* @param index
* @param element
*/
void add(int index, E element);
/**
* 删除index位置的元素
* @param index
* @return
*/
E remove(int index);
/**
* 删除指定元素
* @param element
* @return
*/
public E remove(E element);
/**
* 清除所有元素
*/
void clear();
}
抽象父类设计
抽象父类AbstractList是对接口List的实现
public abstract class AbstractList implements List {
/**
* 元素的数量
*/
protected int size;
/**
* 元素的数量
* @return
*/
public int size() {
return size;
}
/**
* 是否为空
* @return
*/
public boolean isEmpty() {
return size == 0;
}
/**
* 是否包含某个元素
* @param element
* @return
*/
public boolean contains(E element) {
return indexOf(element) != ELEMENT_NOT_FOUND;
}
/**
* 添加元素到尾部
* @param element
*/
public void add(E element) {
add(size, element);
}
/**
* 非法索引访问数组异常
* @param index
*/
protected void outOfBounds(int index) {
throw new IndexOutOfBoundsException("Index:" + index + ", Size:" + size);
}
/**
* 索引检查函数
* @param index
*/
protected void rangeCheck(int index) {
if (index < 0 || index >= size) {
outOfBounds(index);
}
}
/**
* 数组添加元素的索引检查函数
* @param index
*/
protected void rangeCheckForAdd(int index) {
//index > size,元素可以添加在数组size位置,即数组尾部下一存储单元
if (index < 0 || index > size) {
outOfBounds(index);
}
}
}
链表—LinkedList
public class LinkedList extends AbstractList {
/**
* 定义链表第一结点,指向链表头一个元素
*/
private Node first;
/**
* 定义结点类Node,包含元素和指向下一个结点的地址引用
* @param
*/
private static class Node{
E element;
Node next;
public Node(E element, Node next) {
this.element = element;
this.next = next;
}
}
/**
* 设置index位置的元素
*
* @param index
* @param element
* @return 原来的元素ֵ
*/
@Override
public E set(int index, E element) {
Node node = node(index);
E old = node.element;
node.element = element;
return old;
}
/**
* 获取index位置的元素
*
* @param index
* @return
*/
@Override
public E get(int index) {
return node(index).element;
}
/**
* 查看元素的索引
*
* @param element
* @return
*/
@Override
public int indexOf(E element) {
//如果元素为空
if (element == null){
Node node = first;
for (int i = 0;i < size;i++){
if (node.element == null) return i;
node = node.next;
}
}else {
//元素不为空
Node node = first;
for (int i = 0;i < size;i++){
if (element.equals(node.element)) return i;
node = node.next;
}
}
//查无此元素
return ELEMENT_NOT_FOUND;
}
/**
* 在index位置插入一个元素
*
* @param index
* @param element
*/
@Override
public void add(int index, E element) {
rangeCheckForAdd(index);
if (index == 0){
first = new Node<>(element,first);
}else {
Node prev = node(index - 1);
prev.next = new Node<>(element,prev.next);
}
size++;
}
/**
* 删除index位置的元素
*
* @param index
* @return
*/
@Override
public E remove(int index) {
rangeCheck(index);
Node node =first;
if (index == 0){
first = first.next;
}else {
Node prev = node(index - 1);
node = prev.next;
prev.next = node.next;
}
size--;
return node.element;
}
/**
* 删除指定元素
*
* @param element
* @return
*/
@Override
public E remove(E element) {
return remove(indexOf(element));
}
/**
* 清除所有元素
*/
@Override
public void clear() {
size = 0;
first =null;
}
/**
* 获取index位置对应的结点对象
* @param index
* @return
*/
private Node node(int index){
rangeCheck(index);
Node node = first;
for (int i = 0; i < index; i++) {
node = node.next;
}
return node;
}
@Override
public String toString() {
StringBuilder string = new StringBuilder();
string.append("size=").append(size).append(", [");
Node node = first;
for (int i = 0; i < size; i++) {
if (i != 0) {
string.append(", ");
}
string.append(node.element);
node = node.next;
}
string.append("]");
return string.toString();
}
}
虚拟头结点
概念
改进链表:创建带有虚拟头结点的链表
Why:有时候为了让代码更加精筒,统一所有节点的处理逻辑,可以在最前面增加一个虚拟的头结点(不存储数据)
类图关系: 在继承关系与抽象接口设计上,Virtual_LinkedList与LinkedList一样,并未改动
结构设计
带虚拟头结点链表的结构

Virtual_LinkedList 链表类定义的属性与方法
1、属性
private Node—— 定义链表第一结点,指向链表头一个元素first;
2、方法
-
public Virtual_LinkedList()—— 构造方法,用于初始化创建虚拟头结点 -
E set(int index, E element);—— 设置index位置的元素 -
E get(int index);—— 获取index位置的元素 -
int indexOf(E element);—— 查看元素的索引 -
void add(int index, E element);—— 在index位置插入一个元素 -
E remove(int index);—— 删除index位置的元素 -
public E remove(E element);—— 删除指定元素 -
void clear();—— 清除所有元素 -
private Node—— 获取index位置对应的结点对象node(int index)
方法变动
1、第一个需要变动的地方是增加构造方法public Virtual_LinkedList(),用于初始化创建虚拟头结点
/**
* 构造函数,无论有无数据都要创建虚拟头结点
*/
public Virtual_LinkedList() {
first = new Node<>(null,null);
}
2、变动方法 — private Node
前面说到该方法是通过index索引对应的结点对象,是从索引为 0 的元素结点开始查找,现在是从虚拟头结点开始遍历查找,指针应该从first改为first.next,让指针还是指向索引为 0 的元素结点
/**
* 获取index位置对应的结点对象
* @param index
* @return
*/
private Node node(int index){
rangeCheck(index);
Node node = first.next;
for (int i = 0; i < index; i++) {
node = node.next;
}
return node;
}
3、变动方法 — public int indexOf(E element),增加了头结点,遍历时应该从fiirst.next开始
/**
* 查看元素的索引
*
* @param element
* @return
*/
@Override
public int indexOf(E element) {
//如果元素为空
if (element == null){
Node node = first.next;
for (int i = 0;i < size;i++){
if (node.element == null) return i;
node = node.next;
}
}else {
//元素不为空
Node node = first.next;
for (int i = 0;i < size;i++){
if (element.equals(node.element)) return i;
node = node.next;
}
}
//查无此元素
return ELEMENT_NOT_FOUND;
}
4、变动方法 — void add(int index, E element);
之前我们说到添加新结点的方法的思想,是要找到插入的索引位置的前一位置,再来改动指针指向,但是索引为 0 的位置,前面是没有元素结点了,所以这种情况是不通用的,需要根据index == 0的情况分为两种情况,但是有了虚拟头结点,那就变成通用的了,同时也是精简了代码,统一所有结点的处理逻辑
/**
* 在index位置插入一个元素
*
* @param index
* @param element
*/
@Override
public void add(int index, E element) {
rangeCheckForAdd(index);
//这里区分index = 0,是为了应对索引检查函数,node(0 - 1),-1是没法通过检查的,但是添加的逻辑是统一的
Node prev = (index == 0 ? first : node(index - 1));
prev.next = new Node<>(element,prev.next);
size++;
}
5、变动方法 — E remove(int index);同样的,删除方法也是跟 add方法一样,统一所有结点的处理逻辑
/**
* 删除index位置的元素
*
* @param index
* @return
*/
@Override
public E remove(int index) {
rangeCheck(index);
Node node;
Node prev =(index == 0 ? first : node(index - 1));
node = prev.next;
prev.next = node.next;
size--;
return node.element;
}
双向链表
概念
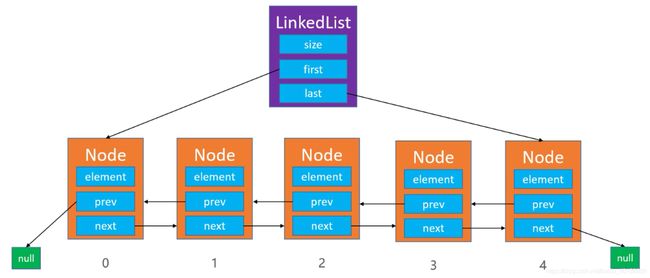
此前,我们在上面编写的都是单向链表,缺点是比较明显的,每次是获取结点元素都需要从头结点开始遍历。而使用双向链表能有效的提升链表的综合性能
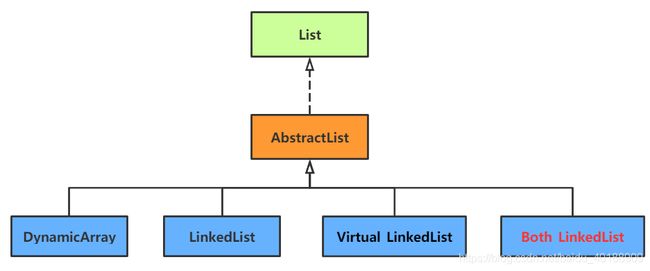
类图关系: 在继承关系与抽象接口设计上,Both_LinkedList与LinkedList一样,并未改动
双向链表设计
/**
* 定义链表尾结点指针,指向链表尾元素
*/
private Node last;
/**
* 定义结点类Node,包含元素和指向下一个结点的地址引用
* @param
*/
private static class Node{
E element;
Node prev;
Node next;
public Node(Node prev, E element, Node next) {
this.prev = prev;
this.element = element;
this.next = next;
}
}
方法变动
1、变动方法 — private Node
此前的node方法,由于是单向链表,所以都是从头开始遍历寻找,现在是双向链表,根据索引位于中间结点位置的前后,决定遍历方向
/**
* 获取index位置对应的结点对象
* @param index
* @return
*/
private Node node(int index){
rangeCheck(index);
//如果查找的元素在链表前半部分
if (index < (size >> 1)) {
Node node = first;
for (int i = 0; i < index; i++) {
node = node.next;
}
return node;
} else {
//如果查找的元素在链表后半部分
Node node = last;
for (int i = size - 1; i > index; i--) {
node = node.prev;
}
return node;
}
}
2、变动方法 — void add(int index, E element);
/**
* 在index位置插入一个元素
*
* @param index
* @param element
*/
@Override
public void add(int index, E element) {
rangeCheckForAdd(index);
//往最后面添加元素
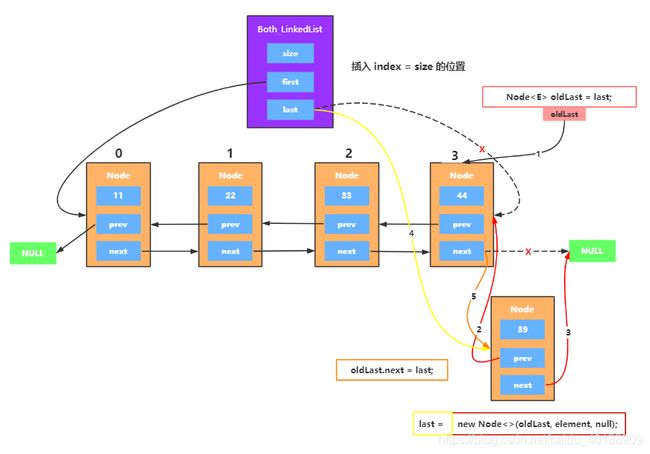
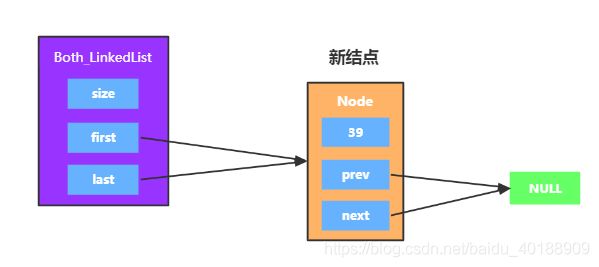
if (index == size) {
Node oldLast = last;
last = new Node<>(oldLast, element, null);
//这是链表添加的第一个元素
if (oldLast == null) {
first = last;
} else {
oldLast.next = last;
}
} else {
Node next = node(index);
Node prev = next.prev;
Node node = new Node<>(prev, element, next);
next.prev = node;
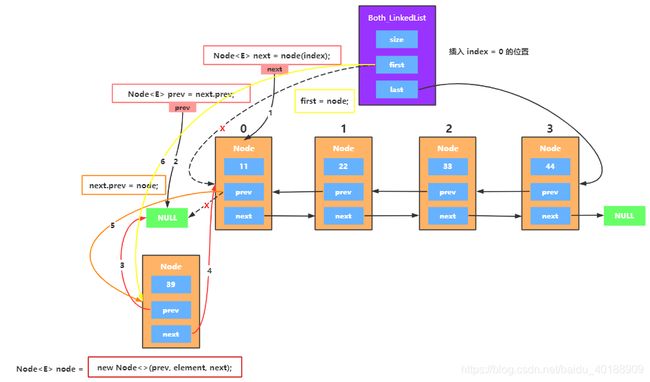
//index == 0,往最前面添加
if (prev == null) {
first = node;
} else {
prev.next = node;
}
}
size++;
}
按照 3 种情形分析,通用的插入于中间位置,插入index == 0头部位置,和插入index == size尾部部位置
1、插入中间位置
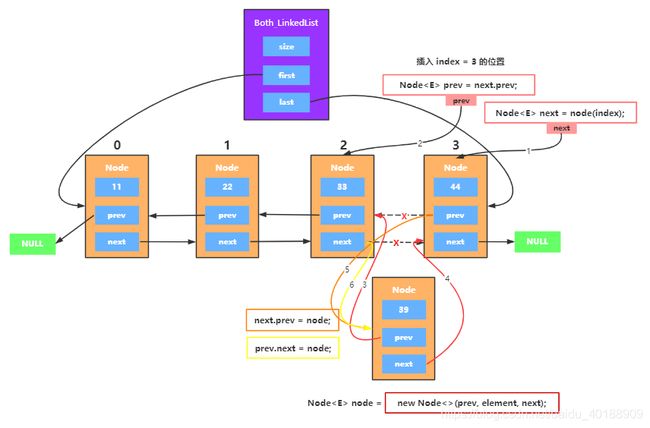
2、插入头部位置
3、插入尾部位置
这里需要注意的是,如果此时的双向链表是空链表,那么尾部插入的就是第一个元素
3、变动方法 — E remove(int index);
事实上,移除结点元素也是跟上面的添加元素一样,在这里就不画图做解释了,读一遍代码不懂的话,可以看着双向链表结构图,读或者DeBug一遍
/**
* 删除index位置的元素
*
* @param index
* @return
*/
@Override
public E remove(int index) {
rangeCheck(index);
Node node = node(index);
Node prev = node.prev;
Node next = node.next;
// index == 0
if (prev == null){
first = next;
}else {
prev.next = next;
}
// index == size - 1
if (next == null){
last = prev;
}else {
next.prev = prev;
}
size--;
return node.element;
}
循环链表
单向循环链表
结构设计:
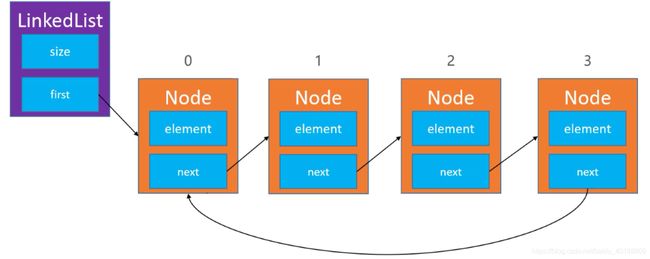
方法变动:
1、变动方法 — void add(int index, E element);
实际上,单向循环链表只是在单向链表的基础上,将尾结点的next指向头结点,所以添加操作只需要注意往头结点插入的情况改动方法就好,注意点有两个,index == 0``size == 0
/**
* 在index位置插入一个元素
*
* @param index
* @param element
*/
@Override
public void add(int index, E element) {
rangeCheckForAdd(index);
if (index == 0){
first = new Node<>(element,first);
Node last =(size == 0) ? first : node(size - 1);
last.next = first;
}else {
Node prev = node(index - 1);
prev.next = new Node<>(element,prev.next);
}
size++;
}
当size == 0,添加的操作就是下图的样子,同时当链表只有一个结点时,也是删除要注意的点
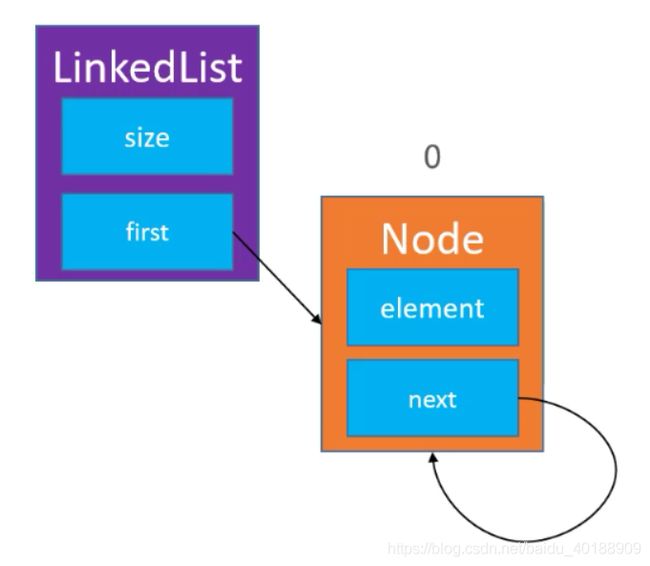
1、变动方法 — public E remove(int index);
/**
* 删除index位置的元素
*
* @param index
* @return
*/
@Override
public E remove(int index) {
rangeCheck(index);
Node node = first;
if (index == 0) {
if (size == 1) {
first = null;
} else {
Node last = node(size - 1);
first = first.next;
last.next = first;
}
} else {
Node prev = node(index - 1);
node = prev.next;
prev.next = node.next;
}
size--;
return node.element;
}
双向循环链表
结构设计:
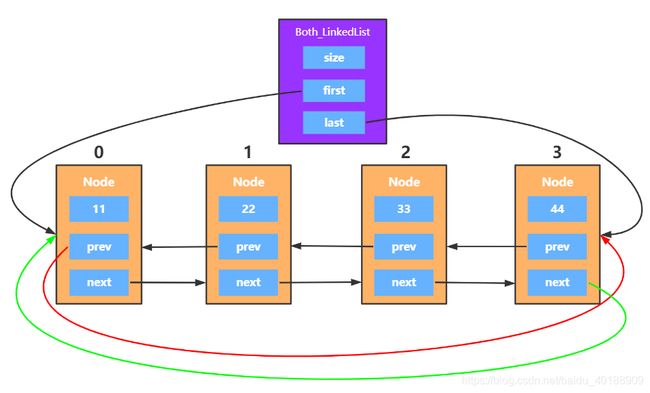
方法变动:
1、变动方法 — void add(int index, E element);
实际上,双向循环链表只是在双链表的基础上,将尾结点的next指向头结点,头结点的prev指向尾结点,所以其实很多都是不变的,我们只需要关注添加操作与删除操作就好了
/**
* 在index位置插入一个元素
*
* @param index
* @param element
*/
@Override
public void add(int index, E element) {
rangeCheckForAdd(index);
//往最后面添加元素
if (index == size) {
Node oldLast = last;
last = new Node<>(oldLast, element, first);
//这是链表添加的第一个元素
if (oldLast == null) {
first = last;
first.next = first;
first.prev = first;
} else {
oldLast.next = last;
first.prev = last;
}
} else {
Node next = node(index);
Node prev = next.prev;
Node node = new Node<>(prev, element, next);
next.prev = node;
prev.next = node;
//index == 0,往最前面添加
if (index == 0) {
first = node;
}
}
size++;
}
注意当size == 0,插入链表的头结点指针指向如下
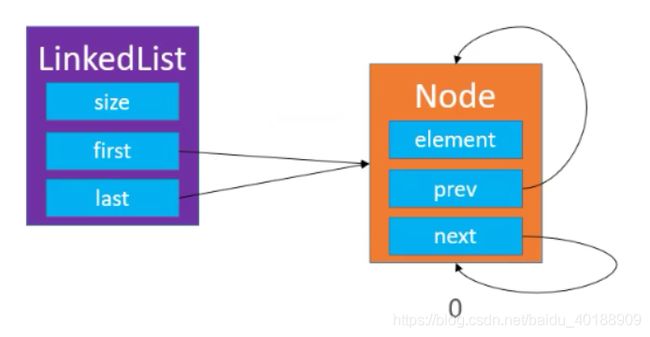
1、变动方法 — public E remove(int index);
/**
* 删除index位置的元素
*
* @param index
* @return
*/
@Override
public E remove(int index) {
rangeCheck(index);
Node node = first;
if (size == 1){
first = null;
last = null;
}else {
node = node(index);
Node prev = node.prev;
Node next = node.next;
prev.next = next;
next.prev = prev;
// index == 0
if (node == first){
first = next;
}
// index == size - 1
if (node == last){
last = prev;
}
}
size--;
return node.element;
}
小结
单向链表 VS 双向链表
粗略对比一下删除的操作数量:
![]()
![]()
相比之下,双向链表的操作缩减了一半,但是其占用的内存空间也增加了
动态数组 VS 链表
1、动态数组:开辟、销毁内存空间的次数相对较少,但可能造成内存空间浪费(可以通过缩容解决)
2、双向链表:开辟、销毁内存空间的次数相对较多,但不会造成内存空间的浪费
应用场景:
-
如果频繁在尾部进行添加、删除操作,动态数组、双向链表均可选择
-
如果频繁在头部进行添加、删除操作,建议选择使用双向链表
-
如果有频繁的(在任意位置)添加、删除操作,建议选择使用双向链表
-
如果有频繁的查询操作(随机访问操作),建议选择使用动态数组
声明
个人能力有限,有不正确的地方,还请指正
文章为原创,欢迎转载,注明出处即可
本文的代码已上传github,欢迎star
GitHub地址