初识pandas 读取excel,绘图
昨天在决策树的认识时,使用到了pandas库,之前对这个库认识不多,但是昨天使用的时候就感觉挺方便的,今天学习一下pandas的一些用法.我主要学习到的功能为:
- 读取保存excel数据
- 使用pandas来绘制简单图形
我在平时使用中就感觉到了使用openpyxl读取excel数据以及绘制简单的scatter,plot图时略显麻烦,所以着重学习了这两个方面.
首先,导入
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
因为数据为中文,所以需要设置一些东西.panda其实也是以numpy和matplotlib为基础的
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
一些要用到的数据,主要用来设置刻度的
rapx = (114.4936096 - 112.6832583)/50
rapy = (23.87839806 - 22.49308313)/50
minx = 112.6832583+rapx*2
maxx = 114.4936096+rapx*2
miny = 22.49308313
maxy = 23.87839806
通过pd.read_excel来读取.函数名简单明了!同样的也可以读csv等文件.然后将数据的前五行输出查看一下
data = pd.read_excel('./二次打包.xlsx')
print(data.head())
u1s1,直接在终端显示略丑,在jupyter显示就挺好看的

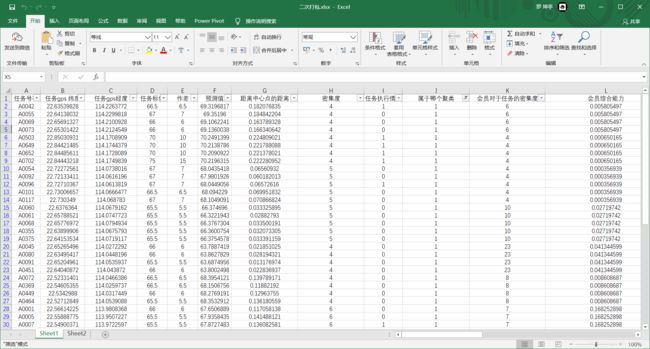
索引操作.有三种方式:
- 直接索引data[ ][ ]的形式,不过需要注意的是,使用这种方式是先列后行,而且不支持切片操作
- 使用iloc,使用这个以后就可以直接根据数字序号进行索引了,而且变回了先行后列的索引方式,支持切片
- 使用loc,使用这个可以直接用列名或者行名来索引,即字符串
dropna()可以将含空的数据全部删除.有时用openpyxl的maxrow读取数据读到None就挺烦的.
test_data = data.iloc[:, 1:3]
df = pd.DataFrame(test_data)
df = df.dropna()
绘图,很方便,直接对dataframe对象.plot()就好,里面一些参数的设置.其中x=1,y=0这个就很方便,就是设置dataframe的第几列做x,第几列做y.可以用数字索引,也可以用’列名’的方式索引,很舒服
df.plot(kind = 'scatter',x=1, y=0, xlim=[minx, maxx], ylim=[miny, maxy], grid=1, xticks=np.arange(
minx, maxx, rapx), yticks=np.arange(miny, maxy, rapy),rot=-90)
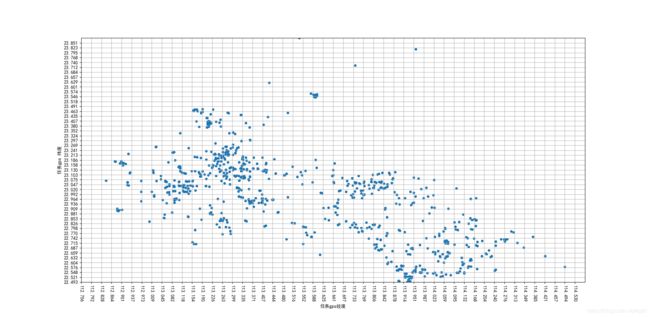
不过,并不是一直都很舒服.比如说画散点图的时候,一定要输入,x和y.这时就很难受,因为我的x想用默认的1,2,3,4…但是pandas我找了一圈好像没找到解决办法,所以最后索性就直接用plt.scatter()了.在使用这个的时候,还碰到一个问题,不知道为啥,如果先画折线图再画散点图,散点图就不知道为啥没了…待研究…
data_old = pd.read_excel('./新新完整.xlsx')
print(data_old.index.values)
data_old.plot(y='修正预测')
plt.scatter(y = data_old['任务标价'],x = data_old.index.values,c='r')
plt.show()

最后,保存excel的操作.to_excel(文件名)就好,这里设置index=0的意思是,不要行名.下面两张图是index=0和1的对比,看一眼就懂了
data['任务标价'][0]=111
data.to_excel('test.xlsx',index=0)
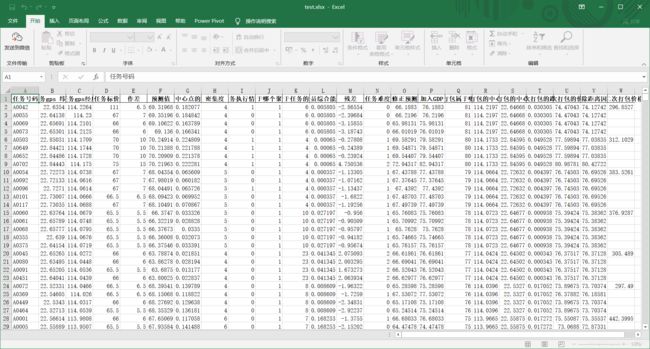
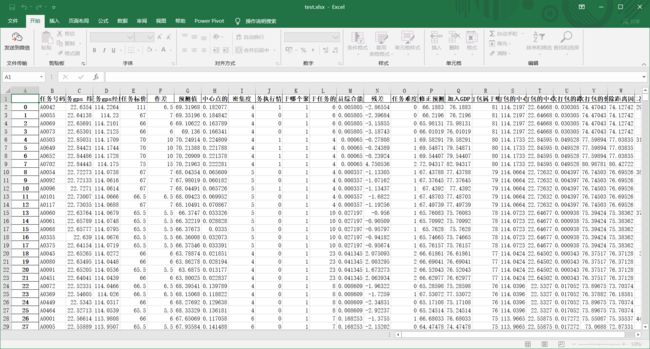
总的来说,pandas用起来很舒服,理论上.因为现在对openpyxl也比较熟悉了,虽然麻烦是麻烦了点,但是熟练的原因,可能还是不太想进入不熟悉的领域,得逼自己多用用pandas,熟悉熟悉.