MyBatis—— SQL执行流程
一、SQL执行流程
我们通常都会先调用 SqlSession 接口的 getMapper方法为我们的Mapper接口生成实现类。然后就可以通过Mapper进行数据库操作。 比如像下面这样:
ArticleMapper articleMapper = session.getMapper(ArticleMapper.class);
Article article = articleMapper.findOne(1);
如果大家对 MyBatis 较为了解,会知道 SqlSession 是通过 JDK 动态代理的方式为接口 生成代理对象的。在调用接口方法时,相关调用会被代理逻辑拦截。在代理逻辑中可根据方 法名及方法归属接口获取到当前方法对应的 SQL 以及其他一些信息,拿到这些信息即可进 行数据库操作。
1. 为Mapper接口创建代理对象
// -☆- DefaultSqlSession
public T getMapper(Class type) {
return configuration.getMapper(type, this);
}
// -☆- Configuration
public T getMapper(Class type, SqlSession sqlSession) {
return mapperRegistry.getMapper(type, sqlSession);
}
// -☆- MapperRegistry
public T getMapper(Class type, SqlSession sqlSession) {
// 从 knownMappers 中获取与 type 对应的 MapperProxyFactory
final MapperProxyFactory mapperProxyFactory = (MapperProxyFactory) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
// 创建代理对象
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
Mapper 接口代理对象的创建逻辑初现端倪。MyBatis 在解析配置文件的节点的过程中,会调用 MapperRegistry 的 addMapper 方法将 Class 到 MapperProxyFactory 对象的映射关系存入到 knownMappers。
在获取到 MapperProxyFactory 对象后,即可调用工厂方法为 Mapper 接口生成代理对象 了。相关逻辑如下:
// -☆- MapperProxyFactory
public T newInstance(SqlSession sqlSession) {
// 创建 MapperProxy 对象,MapperProxy 实现了 InvocationHandler 接口,
// 代理逻辑封装在此类中
final MapperProxy mapperProxy = new MapperProxy(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
protected T newInstance(MapperProxy mapperProxy) {
// 通过 JDK 动态代理创建代理对象
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
上面代码首先创建了一个MapperProxy对象,该对象实现InvocationHandler接口。然后将对象作为参数传给重载方法,并在重载方法中调用JDK动态代理接口为Mapper生成代理对象。
代理对象已经创建完毕,下面就可以调用接口方法进行数据库操作了。由于接口 方法会被代理逻辑拦截,所以下面我们把目光聚焦在代理逻辑上面,看看代理逻辑会做哪些 事情。
2.执行代理逻辑
Mapper接口方法的代理逻辑首先会对拦截的方法进行一些检测,来决定是否执行后续的数据库操作。
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
// 如果方法是定义在 Object 类中的,则直接调用
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
/*
* 下面的代码最早出现在 mybatis-3.4.2 版本中,用于支持 JDK 1.8 中的
* 新特性 - 默认方法。这段代码的逻辑就不分析了,有兴趣的同学可以
* 去 Github 上看一下相关的相关的讨论(issue #709),链接如下:
*
* https://github.com/mybatis/mybatis-3/issues/709
*/
} else if (isDefaultMethod(method)) {
return invokeDefaultMethod(proxy, method, args);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
// 从缓存中获取 MapperMethod 对象,若缓存未命中,则创建 MapperMethod 对象
final MapperMethod mapperMethod = cachedMapperMethod(method);
// 调用 execute 方法执行 SQL
return mapperMethod.execute(sqlSession, args);
}
代理逻辑会首先检测被拦截的方法是不是定义在 Object 中的,比如 equals、hashCode 方法等。对于这类方法,直接执行即可。除此之外,MyBatis 从 3.4.2 版本开始,对 JDK 1.8 接口的默认方法提供了支持,具体就不分析了。完成相关检测后,紧接着从缓存中获取或者创建 MapperMethod 对象,然后通过该对象中的 execute 方法执行 SQL。在分析 execute 方法之前,我们先来看一下 MapperMethod 对象的创建过程。MapperMethod 的创建过程看似普通,但却包含了一些重要的逻辑,所以不能忽视。
3.创建MapperMethod对象
public class MapperMethod {
private final SqlCommand command;
private final MethodSignature method;
public MapperMethod(Class mapperInterface, Method method, Configuration config) {
// 创建 SqlCommand 对象,该对象包含一些和 SQL 相关的信息
this.command = new SqlCommand(config, mapperInterface, method);
// 创建 MethodSignature 对象,从类名中可知,该对象包含了被拦截方法的一些信息
this.method = new MethodSignature(config, mapperInterface, method);
}
}
主要是创建 SqlCommand 和 MethodSignature 对象。这两个对象分别记录了不同的信息,这些信息在后续的方法调用中都会被用到。
1、SqlCommand 中保存了一些和 SQL 相关的信息
2、MethodSignature 即方法签名,顾名思义,该类保存了一些和目标方法相关的信息。比如目标方法的返回类型,目标方法的参数列表信息等。
4.执行execute方法
前面已经分析了 MapperMethod 的初始化过程,现在 MapperMethod 创建好了。那么,接下来要做的事情是调用 MapperMethod 的 execute 方法,执行 SQL。代码如下:
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
// 根据 SQL 类型执行相应的数据库操作
switch (command.getType()) {
case INSERT: {
// 对用户传人的参数进行转换
Object param = method.convertArgsToSqlCommandParam(args);
// 执行插入操作,rowCountResult 方法用于处理返回值
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
//执行更新操作
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
//执行删除操作
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
// 根据目标方法的返回类型进行相应的查询操作
if (method.returnsVoid() && method.hasResultHandler()) {
/*
* 如果方法返回值为 void,但参数列表中包含 ResultHandler,表明使用者
* 想通过 ResultHandler 的方式获取查询结果,而非通过返回值获取结果
*/
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
// 执行查询操作,并返回多个结果
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
// 执行查询操作,并将结果封装在 Map 中返回
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
// 执行查询操作,并返回一个 Cursor 对象
result = executeForCursor(sqlSession, args);
} else {
Object param = method.convertArgsToSqlCommandParam(args);
// 执行查询操作,并返回一个结果
result = sqlSession.selectOne(command.getName(), param);
}
break;
case FLUSH:
// 执行刷新操作
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
// 如果方法的返回值为基本类型,而返回值却为 null,此种情况下应抛出异常
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
如上,execute 方法主要由一个 switch 语句组成,用于根据 SQL 类型执行相应的数据库操作。该方法的逻辑清晰。
// -☆- DefaultSqlSession
@Override
public T selectOne(String statement, Object parameter) {
// Popular vote was to return null on 0 results and throw exception on too many.
List list = this.selectList(statement, parameter);
if (list.size() == 1) {
return list.get(0);
} else if (list.size() > 1) {
throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}
selectOne 方法在内部调用 selectList 了方法,并取 selectList 返回值的第 1 个元素 作为自己的返回值。如果 selectList 返回的列表元素大于 1,则抛出异常。
5.获取BoundSql对象
DefaultSqlSession中的selectOne()方法最终也会调用到selectList()方法。它先从数据大管家configuration中根据请求方法的全名称拿到对应的MappedStatement对象,然后调用执行器的查询方法。
//statement是调用方法的全名称,parameter为参数的Map
@Override
public List selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
//在mapper.xml中每一个SQL节点都会封装为MappedStatement对象
//在configuration中就可以通过请求方法的全名称获取对应的MappedStatement对象
MappedStatement ms = configuration.getMappedStatement(statement);
// 调用 Executor 实现类中的 query 方法
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
在configuration这个大管家对象中,保存着mapper.xml里面所有的SQL节点。每一个节点对应一个MappedStatement对象,而动态生成的各种sqlNode保存在SqlSource对象,SqlSource对象有一个方法就是getBoundSql()。
我们先来看一下BoundSql类哪有哪些属性。
public class BoundSql {
//动态生成的SQL,解析完毕带有占位性的SQL
private final String sql;
//每个参数的信息。比如参数名称、输入/输出类型、对应的JDBC类型等
private final List parameterMappings;
//参数
private final Object parameterObject;
private final Map additionalParameters;
private final MetaObject metaParameters;
}
接下来,开始分析 BoundSql 的构建过程。我们源码之 旅的第一站是 MappedStatement 的 getBoundSql 方法,代码如下:
// -☆- MappedStatement
public BoundSql getBoundSql(Object parameterObject) {
// 调用 sqlSource 的 getBoundSql 获取 BoundSql
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
List parameterMappings = boundSql.getParameterMappings();
if (parameterMappings == null || parameterMappings.isEmpty()) {
// 创建新的 BoundSql,这里的 parameterMap 是 ParameterMap 类型。
// 由 节点进行配置,该节点已经废弃,不推荐使用。
// 默认情况下,parameterMap.getParameterMappings() 返回空集合
boundSql = new BoundSql(configuration, boundSql.getSql(), parameterMap.getParameterMappings(), parameterObject);
}
// check for nested result maps in parameter mappings (issue #30)
for (ParameterMapping pm : boundSql.getParameterMappings()) {
String rmId = pm.getResultMapId();
if (rmId != null) {
ResultMap rm = configuration.getResultMap(rmId);
if (rm != null) {
hasNestedResultMaps |= rm.hasNestedResultMaps();
}
}
}
接下来,我们把目光转 移到 SqlSource 实现类的 getBoundSql 方法上。SqlSource 是一个接口,它有如下几个实现类:
- DynamicSqlSource
- RawSqlSource
- StaticSqlSource
- ProviderSqlSource
- VelocitySqlSource
仅前两个实现类会在映射文件解析的过程中被使用。 当 SQL 配置中包含${}(不是#{})占位符,或者包含、等标签时,会被认为是 动态 SQL,此时使用 DynamicSqlSource 存储 SQL 片段。否则,使用 RawSqlSource 存储 SQL 配置信息。相比之下 DynamicSqlSource 存储的 SQL 片段类型较多,解析起来也更为复杂一 些。因此下面我将分析 DynamicSqlSource 的 getBoundSql 方法。弄懂这个,RawSqlSource 也 不在话下。
public class DynamicSqlSource implements SqlSource {
public BoundSql getBoundSql(Object parameterObject) {
DynamicContext context = new DynamicContext(configuration, parameterObject);
//rootSqlNode为sqlNode节点的最外层封装,即MixedSqlNode。
//解析完所有的sqlNode,将sql内容设置到context
rootSqlNode.apply(context);
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
// 构建 StaticSqlSource,在此过程中将 sql 语句中的占位符 #{} 替换为占位符,
// 并为每个占位符构建相应的 ParameterMapping
SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
//创建BoundSql对象
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
for (Map.Entry entry : context.getBindings().entrySet()) {
boundSql.setAdditionalParameter(entry.getKey(), entry.getValue());
}
return boundSql;
}
}
对于一个包含了${}占位符,或、等标签的 SQL,在解析的过程中,会被分解 成多个片段。每个片段都有对应的类型,每种类型的片段都有不同的解析逻辑。在源码中, 片段这个概念等价于 sql 节点,即 SqlNode。
动态SQL要根据不同的sqlNode节点,调用对应的apply方法,有的还要通过Ognl表达式来判断是否需要添加当前节点,比如IfSqlNode。
rootSqlNode.apply(context)是一个迭代调用的过程。最后生成的内容保存在DynamicContext对象,比如select * from user WHERE uid=#{uid}。
然后调用SqlSourceBuilder.parse()方法
// -☆- SqlSourceBuilder
public SqlSource parse(String originalSql, Class parameterType,
Map additionalParameters) {
// 创建 #{} 占位符处理器
ParameterMappingTokenHandler handler = new ParameterMappingTokenHandler(
configuration, parameterType, additionalParameters);
// 创建 #{} 占位符解析器
GenericTokenParser parser = new GenericTokenParser("#{", "}", handler);
// 解析 #{} 占位符,并返回解析结果
String sql = parser.parse(originalSql);
// 封装解析结果到 StaticSqlSource 中,并返回
return new StaticSqlSource(configuration, sql, handler.getParameterMappings());
}
它主要做了两件事:
1、将SQL语句中的#{}替换为占位符
2、将#{}里面的字段封装成ParameterMapping对象,添加到parameterMappings。
ParameterMapping对象保存的就是参数的类型信息,如果没有配置则为null。
ParameterMapping{property=‘uid’, mode=IN, javaType=class java.lang.Object, jdbcType=null, numericScale=null, resultMapId=‘null’, jdbcTypeName=‘null’, expression=‘null’}
最后返回的BoundSql对象就包含一个带有占位符的SQL和参数的具体信息。
二、执行SQL
创建完BoundSql对象,调用query方法,这里要来说说 executor 变量,该变量类型为 Executor。Executor 是一个接口,它 的实现类如下:
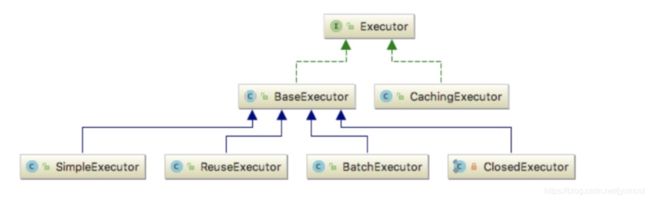
默认情况下,executor 的类型为 CachingExecutor,该类是一 个装饰器类,用于给目标 Executor 增加二级缓存功能。
public class CachingExecutor implements Executor {
public List query(MappedStatement ms, Object parameterObject,
RowBounds rowBounds, ResultHandler resultHandler,
CacheKey key, BoundSql boundSql)throws SQLException {
//二级缓存的应用
//如果配置则走入这个流程
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
//从缓存中获取数据
List list = (List) tcm.getObject(cache, key);
if (list == null) {
list = delegate. query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
return delegate. query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
}
接着看query方法,创建PreparedStatement预编译对象,执行SQL并获取返回集合。
public class SimpleExecutor extends BaseExecutor {
public List doQuery(MappedStatement ms, Object parameter,
RowBounds rowBounds, ResultHandler resultHandler,
BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
//获取Statement的类型,即默认的PreparedStatementHandler
//需要注意,在这里如果配置了插件,则StatementHandler可能返回的是一个代理
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
//创建PreparedStatement对象,并设置参数值
stmt = prepareStatement(handler, ms.getStatementLog());
//执行execute 并返回结果集
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
}
prepareStatement方法获取数据库连接并构建Statement对象设置SQL参数。
1. 创建StatementHandler
在 MyBatis 的源码中,StatementHandler 是一个非常核心接口。之所以说它核心,是因 为从代码分层的角度来说,StatementHandler 是 MyBatis 源码的边界,再往下层就是 JDBC 层 面的接口了。StatementHandler 需要和 JDBC 层面的接口打交道,它要做的事情有很多。在 执行 SQL 之前,StatementHandler 需要创建合适的 Statement 对象,然后填充参数值到 Statement 对象中,最后通过 Statement 对象执行 SQL。

2. 创建PreparedStatement
JDBC 提供了三种 Statement 接口,分别是 Statement、PreparedStatement 和
CallableStatement。他们的关系如下:

上面三个接口的层级分明,其中 Statement 接口提供了执行 SQL,获取执行结果等基本 功能。PreparedStatement 在此基础上,对 IN 类型的参数提供了支持。使得我们可以使用运 行时参数替换 SQL 中的问号?占位符,而不用手动拼接 SQL。CallableStatement 则是在 PreparedStatement 基础上,对 OUT 类型的参数提供了支持,该种类型的参数用于保存存储 过程输出的结果。
public class SimpleExecutor extends BaseExecutor {
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
// 获取数据库连接
C onnection connection = getConnection(statementLog);
// 创建 Statement,
stmt = handler.prepare(connection, transaction.getTimeout());
// 为 Statement 设置 IN 参数
handler.parameterize(stmt);
return stmt;
}
}
上面代码的逻辑比较简单,总共包含三个步骤。如下:
- 获取数据库连接
- 创建 Statement
- 为 Statement 设置 IN 参数
获取Connection连接
我们看到getConnection方法就是获取Connection连接的地方。但这个Connection也是一个代理对象,它的调用程序处理器为ConnectionLogger。显然,它是为了更方便的打印日志。
public abstract class BaseExecutor implements Executor {
protected Connection getConnection(Log statementLog) throws SQLException {
//从c3p0连接池中获取一个连接
Connection connection = transaction.getConnection();
//如果日志级别为Debug,则为这个连接生成代理对象返回
//它的处理类为ConnectionLogger
if (statementLog.isDebugEnabled()) {
return ConnectionLogger.newInstance(connection, statementLog, queryStack);
} else {
return connection;
}
}
}
MyBatis 并未没有在 getConnection 方法中直接调用 JDBC DriverManager 的 getConnection 方 法获取获取连接,而是通过数据源获取连接。MyBatis 提供了两种基于 JDBC 接口的数据源, 分别为 PooledDataSource 和 UnpooledDataSource。创建或获取数据库连接的操作最终是由这 两个数据源执行。
执行预编译
public class PreparedStatementHandler
protected Statement instantiateStatement(Connection connection) throws SQLException {
String sql = boundSql.getSql();
return connection.prepareStatement(sql);
}
}
所以,在执行的onnection.prepareStatement(sql)的时候,实际调用的是ConnectionLogger类的invoke()。
public final class ConnectionLogger extends BaseJdbcLogger implements InvocationHandler {
public Object invoke(Object proxy, Method method, Object[] params)throws Throwable {
try {
if ("prepareStatement".equals(method.getName())) {
if (isDebugEnabled()) {
debug(" Preparing: " + removeBreakingWhitespace((String) params[0]), true);
}
//调用connection.prepareStatement
PreparedStatement stmt = (PreparedStatement) method.invoke(connection, params);
//又为stmt创建了代理对象,通知类为PreparedStatementLogger
stmt = PreparedStatementLogger.newInstance(stmt, statementLog, queryStack);
return stmt;
}
}
}
}
public static PreparedStatement newInstance(PreparedStatement stmt, Log statementLog, int queryStack) {
InvocationHandler handler = new PreparedStatementLogger(stmt, statementLog, queryStack);
ClassLoader cl = PreparedStatement.class.getClassLoader();
return (PreparedStatement) Proxy.newProxyInstance(cl,
new Class[]{PreparedStatement.class, CallableStatement.class}, handler);
}
最后返回的PreparedStatement又是个代理对象。
3. #{}占位符的解析与参数的设置过程
假设我们有这样一条 SQL 语句:
SELECT * FROM author WHERE name = #{name} AND age = #{age}
这个 SQL 语句中包含两个#{}占位符,在运行时这两个占位符会被解析成两个 ParameterMapping 对象。如下:
ParameterMapping{property='name', mode=IN, javaType=class java.lang.String, jdbcType=null, ...}
和
ParameterMapping{property='age', mode=IN, javaType=class java.lang.Integer, jdbcType=null, ...}
#{xxx}占位符解析完毕后,得到的 SQL 如下:
SELECT * FROM Author WHERE name = ? AND age = ?
这里假设下面这个方法与上面的 SQL 对应:
Author findByNameAndAge(@Param("name")String name, @Param("age")Integer age)
该方法的参数列表会被 ParamNameResolver 解析成一个 map,如下:
{
0: "name",
1: "age"
}
假设该方法在运行时有如下的调用:
findByNameAndAge("tianxiaobo", 20)
此时,需要再次借助 ParamNameResolver 的力量。这次我们将参数名和运行时的参数
值绑定起来,得到如下的映射关系。
{
"name": "tianxiaobo",
"age": 20,
"param1": "tianxiaobo",
"param2": 20
}
下一步,我们要将运行时参数设置到 SQL 中。由于原 SQL 经过解析后,占位符信息已 经被擦除掉了,我们无法直接将运行时参数 SQL 中。不过好在,这些占位符信息被记录在 了 ParameterMapping 中了,MyBatis 会将 ParameterMapping 会按照#{}占位符的解析顺序存 入到List中。这样我们通过ParameterMapping在列表中的位置确定它与SQL中的哪一个个? 占位符相关联。同时通过 ParameterMapping 中的 property 字段,我们可以到“参数名与参数 值”映射表中查找具体的参数值。这样,我们就可以将参数值准确的设置到 SQL 中了,此时 SQL 如下:
SELECT * FROM Author WHERE name = "tianxiaobo" AND age = 20
4. 处理查询结果
MyBatis 可以将查询结果,即结果集 ResultSet 自动映射成实体类对象。这样使用者就无 需再手动操作结果集,并将数据填充到实体类对象中。这可大大降低开发的工作量,提高工 作效率。在 MyBatis 中,结果集的处理工作由结果集处理器 ResultSetHandler 执行。 ResultSetHandler 是一个接口,它只有一个实现类 DefaultResultSetHandler。结果集的处理入 口方法是 handleResultSets,下面来看一下该方法的实现。
public class DefaultResultSetHandler implements ResultSetHandler {
public List三、总结
关于Mybatis执行方法的整个过程,我们简单归纳一下。
- 获取SqlSession,根据方法的返回值类型调用不同的方法。比如selectOne。
- 获取BoundSql对象,根据传递的参数生成SQL语句
- 从数据库连接池获取Connection对象,并为它创建代理,以便打印日志
- 从Connection中获取PreparedStatement预编译对象,并为它创建代理
- 预编译SQL,并设置参数
- 执行、返回数据集合
- 将数据集转换为Java对象