数据挖掘读书笔记--第八章(中):分类:贝叶斯分类法 、基于规则分类
散记知识点
——“继续学习经典分类算法”
3. 贝叶斯分类法(Naive Bayesian)
贝叶斯分类法是统计学分类方法,基于贝叶斯定理。朴素贝叶斯分类法可以与决策树和经过挑选的神经网络分类器相媲美。用于大型数据库,贝叶斯分类法也表现出高准确率和高速度。
3.1 贝叶斯定理
设数据元组 X X 有 n n 个属性,给定 X X 的 n n 个属性值已知的条件下, X X 被认定为类别 C C 的概率为 P(C|X) P ( C | X ) ,称为后验概率也即我们要求的概率。
P(X)、P(C) P ( X ) 、 P ( C ) 称为先验概率,其中 P(X) P ( X ) 可以用 X X 出现的概率来估计。比如,在顾客集合中,年龄为35岁且收入为4万美元的概率。 P(C) P ( C ) 为类别的先验概率,可以用类 C C 在整个数据集出现的频率来估计。
P(X|C) P ( X | C ) 是在类别为 C C 的条件下, X X 的后验概率。例如,已知类别为顾客 X X 购买计算机,则 X X 的年龄为35岁收入为4万元的概率。
根据已知数据集 D D ,我们可以得到 P(X)、P(C)和P(X|C) P ( X ) 、 P ( C ) 和 P ( X | C ) ,则在给定一个新的数据元组 X X ,来判断它是否属于某类的概率为 P(C|X) P ( C | X ) :(例如,已知年龄为30岁收入为3万美元顾客,则他会购买计算机的概率为:)
即为贝叶斯公式。
3.2 朴素贝叶斯分类
朴素贝叶斯分类法有个前提条件:为了简化运算,假设在给定类别 C C 的条件下,每个属性相互独立。这一假设称为类条件独立性,大大简化的计算量,故被称为“朴素”贝叶斯分类。
朴素贝叶斯分类的主要过程如下:
(1) 数据集 D D 中,每个数据元组 X X 有 n n 个属性 A1,A2,...,An A 1 , A 2 , . . . , A n 的属性值组成: X={x1,x2,...,xn} X = { x 1 , x 2 , . . . , x n } 。同时,有 m m 个类 C1,C2,...,Cn C 1 , C 2 , . . . , C n 。
(2) 给定数据元组 X X ,使用贝叶斯定理预测 X X 属于使得 P(Ci|X) P ( C i | X ) 最大的类 Ci C i :
P(Ci|X)>P(Cj|X) 1⩽j⩽m, j≠i P ( C i | X ) > P ( C j | X ) 1 ⩽ j ⩽ m , j ≠ iP(Ci|X) P ( C i | X ) 的类称为最大后验假设。则:P(Ci|X)=P(X|Ci)P(Ci)P(X) P ( C i | X ) = P ( X | C i ) P ( C i ) P ( X )(3) 由于 P(X)=∑mi=1P(X|Ci)P(Ci) P ( X ) = ∑ i = 1 m P ( X | C i ) P ( C i ) 对所有类为常数。所以只需关心 P(X|Ci)P(Ci) P ( X | C i ) P ( C i ) 最大即可。
- ①如果类先验概率可知,类先验概率可用 P(Ci)=|Ci,D| / |D| P ( C i ) = | C i , D | / | D | 估计,其中 |Ci,D| | C i , D | 是 D D 中 Ci C i 类的训练元组个数。
②如果类别的先验概率未知,则通常假定这些类是等概率的,即 P(C1)=P(C2)=...=P(Cm) P ( C 1 ) = P ( C 2 ) = . . . = P ( C m ) ,据此简化为对 P(Ci|X) P ( C i | X ) 最大化。
(4) 若数据集具有许多属性,计算 P(X|Ci) P ( X | C i ) 开销很大,使用类条件独立的朴素假定:即在给定类别条件下,属性值相互独立:
P(X|Ci)=∏k=1nP(xk|Ci)=P(x1|Ci)P(x2|Ci)...P(xn|Ci) P ( X | C i ) = ∏ k = 1 n P ( x k | C i ) = P ( x 1 | C i ) P ( x 2 | C i ) . . . P ( x n | C i )其中, xk x k 为元组 X X 在属性 Ak A k 的值。对于属性,考察两种情况:如果 Ak A k 是离散属性,则 P(xk|Ci) P ( x k | C i ) 是 D D 中属性 Ak A k 的值为 xk x k 的 Ci C i 类的元组数除以 D D 中 Ci C i 类的元组数。
如果 Ak A k 是连续值属性,通常假定连续值服从均值为 μ μ 、标准差为 σ σ 的高斯分布:
g(x,μ,σ)=12π−−√σe−(x−μ)22σ2 g ( x , μ , σ ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2因此P(xk|Ci)=g(x,μCi,σCi) P ( x k | C i ) = g ( x , μ C i , σ C i )其中 μCi,σCi μ C i , σ C i 分别是 Ci C i 类训练元组属性 Ak A k 的均值和标准差。

(5) 对给定数据元组 X X 预测它的类标号 Ci C i :
argmaxCiP(X|Ci)P(Ci) 1⩽j⩽m arg max C i P ( X | C i ) P ( C i ) 1 ⩽ j ⩽ m
3.3 Python简单实现朴素贝叶斯分类器
# -*- coding: utf-8 -*-
__author__ = "Yunfan Yang"
def data_prep(filename):
"""数据预处理,属性列表以及数据元组列表"""
with open(filename,'r') as f:
raw_data = f.read() # 读取数据
# print(raw_data)
data_list = raw_data.split('\n')[:-1] # 将文本数据转换为列表
Attributes = [] # 属性和类别名称列表
X_list = [] # 数据元组列表
for i in range(len(data_list)):
X = []
if i == 0:
Attributes = data_list[i].split(',') # 创建属性列表
else:
X = data_list[i].split(',') # 元组列表
X_list.append(X)
return Attributes, X_list
def get_class_value(Attributes, X_list):
"""获取类别列表"""
classes_values = []
for X in X_list:
if X[-1] not in classes_values:
classes_values.append(X[-1])
return classes_values
def calculate_prob(attribute_and_value, classes_values, Attributes, X_list):
"""计算概率(先验概率和后验概率)"""
for key,value in attribute_and_value.items():
index = Attributes.index(key) # 获取属性在属性列表中的索引
attribute_value = value
prior_prob = {}
posterior_prob = {}
for label in classes_values: # 遍历类别列表
class_count = 0
attribute_count = 0
for X in X_list: # 遍历数据集
if X[-1] == label:
class_count += 1
if X[index] == attribute_value:
attribute_count += 1
prior_prob[label] = class_count / len(X_list) # 类别自身的先验概率
posterior_prob[label] = attribute_count / class_count # 类别条件下,属性值的后验概率
return prior_prob, posterior_prob
def Bayesian_Predict(input_X, classes_values, Attributes, X_list):
"""朴素贝叶斯分类预测"""
pre_dict = {}
for label in classes_values: # 遍历类别值列表
X_C_prob = 1
for key,value in input_X.items(): # 遍历输入数据元组的键值对
attribute_and_value = {}
attribute_and_value[key]=value # 生成属性和属性值字典
prior_prob, posterior_prob = calculate_prob(attribute_and_value, classes_values, Attributes, X_list) # 计算概率值
X_C_prob *= posterior_prob[label] # 累乘得到,类别条件下,数据元组的后验概率
C_X_prob = X_C_prob * prior_prob[label] # 给定数据元组条件下的类别概率
pre_dict[label] = C_X_prob # 键为类别值,值为后验假设概率
# 按照从大到小排列
predict = sorted(pre_dict.items(), reverse=True, key=lambda x:x[1])
# 最可能的类别值
result = predict[0][0]
# 最可能类别值的概率
sum = 0
for value in predict:
sum+=value[1]
result_prob = predict[0][1] / sum # 预测类别的概率
print("\n该数据元组最可能的类别是:", result)
print("判断为该类别的概率为:{}%".format(round(result_prob*100,1)))
if __name__=="__main__":
filename = 'raw_data.csv' # 读取文件,数据预处理
Attributes, X_list = data_prep(filename) # 对于每个X,第一个值时标号,最后一个是类别,中间都是属性值
# print(Attributes)
# print(X_list)
classes_values = get_class_value(Attributes, X_list)
# 输入的未知分类元组
input_X = {'age':'youth', 'income':'high', 'student': 'yes', 'credit_rating':'fair'}
# 进行分类预测
Bayesian_Predict(input_X, classes_values, Attributes, X_list)
运行结果为:
该数据元组最可能的类别是: yes
判断为该类别的概率为:67.3%3.4 零概率值处理
在计算的过程中,有可能会出现某个后验概率值 P(xk|Ci)=0 P ( x k | C i ) = 0 的情况。考虑这个零概率值,会使得 P(X|Ci) P ( X | C i ) 为0,一个零概率值将消除概率累乘中涉及到 Ci C i 的所有属性值的后验概率影响。
可以使用拉普拉斯校准法避免这个问题:在计算 P(xk|Ci) P ( x k | C i ) 时,分子分母计数同时加1。
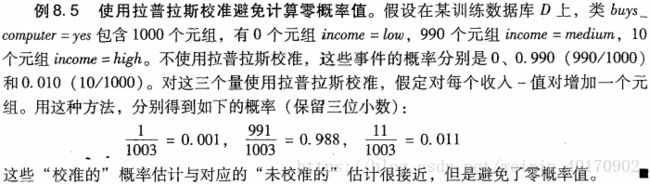
4. 基于规则分类
4.1 IF-THEN规则分类
IF-THEN规则表达式形如: IF条件THEN结论 例如,R1:IF age=youth AND student=yes THEN buys_computer=yes
规则R可以用覆盖率和准确率评估,在数据集 D D ,设 ncovers n c o v e r s 为规则R覆盖的元组数, ncorrect n c o r r e c t 为R正确分类的元组数,则R的覆盖率和准确率定义为:
4.2 由决策树提取规则
提取方法:
- 对每条从根结点到树叶结点的路径创建一条规则。
- 沿着给定路径上的每个分裂准则的逻辑(根结点=分枝)AND形成规则的前件(IF部分)。
- 存放类预测的树叶结点形成规则的后件(THEN部分)。
与决策树相比, IF-THEN规则更容易理解,特别当决策树非常大时。
4.3 顺序覆盖算法的规则归纳
使用顺序覆盖算法可以直接从训练数据提取 IF-THEN规则(不需要产生决策树)。顺序覆盖算法是最广泛使用的挖掘分类规则析取集的方法。
(1) 顺序覆盖算法
算法的一般策略如下:
- 一次学习一个规则。每学习一个规则,就删除该规则覆盖的元组,并在剩下的元组上重复该过程。
- 在为 C C 类学习规则时,希望规则覆盖 C C 类所有(或很多)训练元组,并且没有(或很少)覆盖其他类的元组,以此来保证规则的高准确率。
- 继续执行直到满足终止条件:①不在有训练元组;②返回规则质量低于设定阈值。

(2) 规则质量度量
单纯地考虑规则准确率和覆盖率有的时候并不可靠。
假设学习类 c c 的规则,当前规则为 R:IF condition THEN class=c R : I F c o n d i t i o n T H E N c l a s s = c ,考虑一个新的规则 R′:IF condition′ R ′ : I F c o n d i t i o n ′ THEN class=c T H E N c l a s s = c ,比较前后两个规则谁比较好,则可以使用以下度量:
- ① 熵:考虑 condition′ c o n d i t i o n ′ 覆盖的数据元组集合 D D , pi p i 为 D D 中 Ci C i 类的概率。则熵越小, condition′ c o n d i t i o n ′ 越好,规则就越好。
- ② 信息增益:在机器学习中,用于学习规则的元组为正元组,其余元组为负元组,设 pos(neg) p o s ( n e g ) 和 pos′(neg′) p o s ′ ( n e g ′ ) 为被 R R 和 R′ R ′ 覆盖的正(负)元组数。在一阶归纳学习器FOIL中,估计扩展 condition′ c o n d i t i o n ′ 的信息增益:
FOILGain=pos′×(log2pos′pos′+neg′−log2pospos+neg) F O I L G a i n = p o s ′ × ( log 2 p o s ′ p o s ′ + n e g ′ − log 2 p o s p o s + n e g )它偏向于具有高准确率且覆盖许多正元组的规则。
- ③ 统计显著性检验:确定规则的效果是否并非出于偶然性,而是预示属性值与类之间的真实相关性。该检验将规则付该元组的观测类分布与规则随机预测产生的期望类分布进行比较,评估这两个分布之间的观测差是否是随机的,使用似然率统计量:
LikelihoodRatio=2∑i=1mfilog(fiei) L i k e l i h o o d R a t i o = 2 ∑ i = 1 m f i log ( f i e i )其中, m m 为类数, fi f i 是满足规则的元组中类 i i 的观测频率。 ei e i 是规则随机预测时类 i i 的期望频率。该统计量服从自由度为 m−1 m − 1 的 χ2 χ 2 分布。似然率越高,规则正确预测数与“随机猜测”的差距越明显。似然率有助于识别具有显著覆盖率的规则。
(3) 规则剪枝
为防止过拟合,对规则 R R 剪枝,如果在独立的元组集上评估, R R 剪枝后具有更好的质量。与决策树一样,这些元组集称为剪枝集。给定规则 R R ,FOIL剪枝策略:
这个值将随着 R R 在剪枝集上的准确率增加而增加。因此,如果 R R 剪枝后 FOILPrune F O I L P r u n e 值较高,则对 R R 剪枝。