jieba 使用笔记
jieba 使用笔记
- 初始化
- 分词 jieba.cut(sentence, cut_all , HMM)
- 自定义词典
- 词性标注
- 关键词提取
- Tokenize:返回词语在原文的起止位置
- ChineseAnalyzer for Whoosh 搜索引擎
安装: pip 即可
初始化
import jieba
import jieba.posseg # 词性标注
import jieba.analyse # 关键词
from jieba.analyse import ChineseAnalyzer # 搜索引擎
# jieba.initialize() # 手动初始化(可选)
分词 jieba.cut(sentence, cut_all , HMM)
cut_all= 参数用来控制分词模式 False 为精确模式 True为全模式
HMM= 参数用来控制是否使用 HMM 模型用于新词发现
jieba提供3种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
并行分词(不支持win)
jieba.enable_parallel(2) # 开启并行分词模式,参数为并行进程数
jieba.disable_parallel() # 关闭并行分词模式
cut/cut_for_search 返回 generator
lcut/lcut_for_search 返回 list
为print更清晰 易于比较 使用 str.ljust()/center()/rjust()函数实现输出的字符串左对齐、居中、右对齐
default = jieba.cut('在南京市长江大桥研究生命的起源他来到了网易杭研大厦') # 默认模式 默认cut_all=False, HMM=True
hmm = jieba.cut('在南京市长江大桥研究生命的起源他来到了网易杭研大厦', cut_all=False, HMM=True)
accurate = jieba.cut('在南京市长江大桥研究生命的起源他来到了网易杭研大厦', cut_all=False, HMM=False) # 精确模式
full = jieba.cut('在南京市长江大桥研究生命的起源', cut_all=True) # 全模式
search = jieba.cut_for_search('在南京市长江大桥研究生命的起源') # 搜索引擎模式
default_list = jieba.lcut('在南京市长江大桥研究生命的起源') # 返回list
search_list = jieba.lcut_for_search('在南京市长江大桥研究生命的起源')
# jieba.Tokenizer(dictionary=) # 新建分词器
print('default'.rjust(15), "/".join(default))
print('hmm'.rjust(15), "/".join(hmm))
print('accurate'.rjust(15), "/".join(accurate))
print('full'.rjust(15), "/".join(full))
print('search'.rjust(15), "/".join(search))
print('default_list'.rjust(15), default_list)
print('search_list'.rjust(15), search_list)

自定义词典
词典格式:
一词一行 一行:词语 词频(可省)词性(可省) 空格分隔 顺序不可颠倒 UTF-8编码
华能 3 nz
云泥 ns
河势 n
庙沟 ns
使用 add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典。
使用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
注意:自动计算的词频在使用 HMM 新词发现功能时可能无效。
jieba.load_userdict('../Data/dict/30wChinsesSeqDic_clean.txt')
jieba.add_word('加入自定义词')
test_sent1 = jieba.cut('在南京市长江大桥研究生命的起源和加入自定义词')
print('test_sent1', "/".join(test_sent1))
jieba.del_word('加入自定义词')
test_sent2 = jieba.cut('在南京市长江大桥研究生命的起源和加入自定义词')
print('test_sent2', "/".join(test_sent2))
jieba.suggest_freq('研究生命', True)
test_sent3 = jieba.cut('在南京市长江大桥研究生命的起源和加入自定义词')
print('test_sent3', "/".join(test_sent3))

词性标注
jieba.posseg.POSTokenizer(tokenizer=None) 新建自定义分词器,tokenizer 参数可指定内部使用的 jieba.Tokenizer 分词器。jieba.posseg.dt 为默认词性标注分词器。
标注句子分词后每个词的词性,采用和 ictclas 兼容的标记法。
返回 generator
words = jieba.posseg.cut('在南京市长江大桥研究生命的起源')
[print(word, flag) for word, flag in words]

关键词提取
两种方式:
- TF-IDF :
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
sentence 为待提取的文本
topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
withWeight 为是否一并返回关键词权重值,默认值为 False
allowPOS 仅包括指定词性的词,默认值为空,即不筛选
jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件 - TextRank :
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=(‘ns’, ‘n’, ‘vn’, ‘v’))
直接使用,接口相同,注意默认过滤词性。
jieba.analyse.TextRank() 新建自定义 TextRank 实例
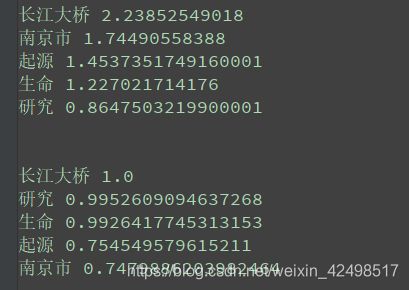
tf_tags = jieba.analyse.extract_tags('在南京市长江大桥研究生命的起源', topK=5, withWeight=True, allowPOS=())
[print(keyword, withWeight) for keyword, withWeight in tf_tags]
print('\n')
# jieba.analyse.set_idf_path('file_name') # file_name为自定义 逆向文件频率(IDF)文本语料库 的路径
# jieba.analyse.set_stop_words(file_name) # file_name为自定义 停止词(Stop Words)文本语料库 的路径
tr_tags = jieba.analyse.textrank('在南京市长江大桥研究生命的起源', topK=5, withWeight=True, allowPOS=('ns', 'n', 'vn', 'v'))
[print(keyw, Weight) for keyw, Weight in tr_tags]
Tokenize:返回词语在原文的起止位置
注意,输入参数只接受 unicode
有默认模式与搜索模式
words_locat = jieba.tokenize('研究生命起源', mode='default', HMM=False)
[print("word %s\t\t start: %d \t\t end:%d" % (w[0].rjust(10), w[1], w[2])) for w in words_locat]
words_locat_search = jieba.tokenize('研究生命起源', mode='search', HMM=False)
[print("word %s\t\t start: %d \t\t end:%d" % (w[0].rjust(10), w[1], w[2])) for w in words_locat_search]

ChineseAnalyzer for Whoosh 搜索引擎
简单测试下
analyzer = ChineseAnalyzer()
[print(t.text) for t in analyzer("在南京市长江大桥研究生命的起源")]
print(analyzer)
# Out[]
# CompositeAnalyzer(ChineseTokenizer(), LowercaseFilter(), StopFilter(stops=frozenset({'that', 'or', 'with', 'for', 'if', '了', 'and', 'a', 'you', 'have', 'from', 'is', 'may', 'in', 'we', 'as', 'of', 'us', 'tbd', 'when', 'by', 'it', 'this', 'on', 'can', 'the', 'yet', 'not', 'at', '和', 'an', 'are', 'to', 'your', 'will', '的', 'be'}), min=1, max=None, renumber=True), StemFilter(stemfn=, lang=None, ignore=frozenset(), cachesize=50000, _stem=))
