Linux下用C编写WebSocet服务以响应HTML5的WebSocket请求
在HTML5中新增了WebSocket,使得通讯变得更加方便。这样一来,Web与硬件的交互除了CGI和XHR的方式外,又有了一个新的方式。那么使用WebSocket又如何与下层通信呢?看看WebSocket的相关介绍就会发现,其类似于HTTP协议的通信,但又不同于HTTP协议通信,其最终使用的是TCP通信。具体的可以参照该文WebScoket 规范 + WebSocket 协议。
我们先来看看通信的效果图

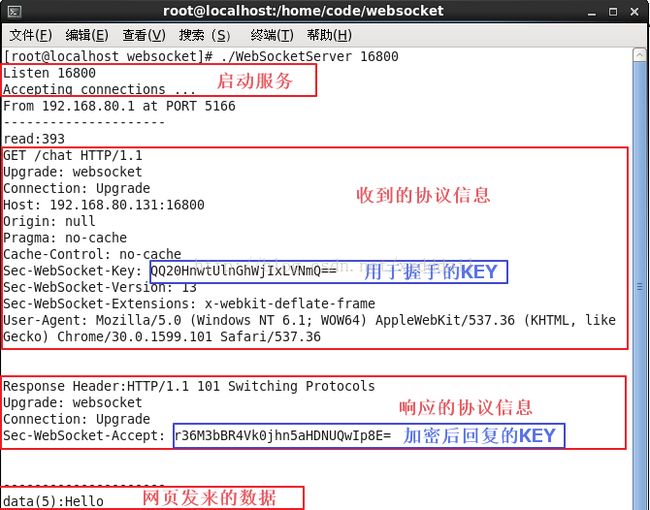
下面是实现的步骤
1.建立SOCKET监听
WebSocket也是TCP通信,所以服务端需要先建立监听,下面是实现的代码。
/* server.c */
#include
#include
#include
#include
#include
#include
#include "base64.h"
#include "sha1.h"
#include "intLib.h"
#define REQUEST_LEN_MAX 1024
#define DEFEULT_SERVER_PORT 8000
#define WEB_SOCKET_KEY_LEN_MAX 256
#define RESPONSE_HEADER_LEN_MAX 1024
#define LINE_MAX 256
void shakeHand(int connfd,const char *serverKey);
char * fetchSecKey(const char * buf);
char * computeAcceptKey(const char * buf);
char * analyData(const char * buf,const int bufLen);
char * packData(const char * message,unsigned long * len);
void response(const int connfd,const char * message);
int main(int argc, char *argv[])
{
struct sockaddr_in servaddr, cliaddr;
socklen_t cliaddr_len;
int listenfd, connfd;
char buf[REQUEST_LEN_MAX];
char *data;
char str[INET_ADDRSTRLEN];
char *secWebSocketKey;
int i,n;
int connected=0;//0:not connect.1:connected.
int port= DEFEULT_SERVER_PORT;
if(argc>1)
{
port=atoi(argv[1]);
}
if(port<=0||port>0xFFFF)
{
printf("Port(%d) is out of range(1-%d)\n",port,0xFFFF);
return;
}
listenfd = socket(AF_INET, SOCK_STREAM, 0);
bzero(&servaddr, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
servaddr.sin_port = htons(port);
bind(listenfd, (struct sockaddr *)&servaddr, sizeof(servaddr));
listen(listenfd, 20);
printf("Listen %d\nAccepting connections ...\n",port);
cliaddr_len = sizeof(cliaddr);
connfd = accept(listenfd, (struct sockaddr *)&cliaddr, &cliaddr_len);
printf("From %s at PORT %d\n",
inet_ntop(AF_INET, &cliaddr.sin_addr, str, sizeof(str)),
ntohs(cliaddr.sin_port));
while (1)
{
memset(buf,0,REQUEST_LEN_MAX);
n = read(connfd, buf, REQUEST_LEN_MAX);
printf("---------------------\n");
if(0==connected)
{
printf("read:%d\n%s\n",n,buf);
secWebSocketKey=computeAcceptKey(buf);
shakeHand(connfd,secWebSocketKey);
connected=1;
continue;
}
data=analyData(buf,n);
response(connfd,data);
}
close(connfd);
} 2.握手
在建立监听后,网页向服务端发现WebSocket请求,这时需要先进行握手。握手时,客户端会在协议中包含一个握手的唯一Key,服务端在拿到这个Key后,需要加入一个GUID,然后进行sha1的加密,再转换成base64,最后再发回到客户端。这样就完成了一次握手。此种握手方式是针对chrome websocket 13的版本,其他版本的可能会有所不同。下面是实现的代码。
char * fetchSecKey(const char * buf)
{
char *key;
char *keyBegin;
char *flag="Sec-WebSocket-Key: ";
int i=0, bufLen=0;
key=(char *)malloc(WEB_SOCKET_KEY_LEN_MAX);
memset(key,0, WEB_SOCKET_KEY_LEN_MAX);
if(!buf)
{
return NULL;
}
keyBegin=strstr(buf,flag);
if(!keyBegin)
{
return NULL;
}
keyBegin+=strlen(flag);
bufLen=strlen(buf);
for(i=0;i注意:
1.Connection后面的值与HTTP通信时的不一样了,是Upgrade,而Upgrade又对应到了websocket,这样就标识了该通信协议是websocket的方式。
2.在sha1加密后进行base64编码时,使用sha1加密后的串必须将其当成16进制的字符串,将每两个字符合成一个新的码(0-0xFF间)来进一步计算后,才可以进行base64换算(我开始时就在这里折腾了很久,后面才弄明白还要加上这一步),如果是直接就base64,那就会握手失败。
3.对于sha1和base64网上有很多,后面也附上我所使用的代码。
3.数据传输
握手成功后就可以进行数据传输了,只要按照WebSocket的协议来解就可以了。下面是实现的代码
char * analyData(const char * buf,const int bufLen)
{
char * data;
char fin, maskFlag,masks[4];
char * payloadData;
char temp[8];
unsigned long n, payloadLen=0;
unsigned short usLen=0;
int i=0;
if (bufLen < 2)
{
return NULL;
}
fin = (buf[0] & 0x80) == 0x80; // 1bit,1表示最后一帧
if (!fin)
{
return NULL;// 超过一帧暂不处理
}
maskFlag = (buf[1] & 0x80) == 0x80; // 是否包含掩码
if (!maskFlag)
{
return NULL;// 不包含掩码的暂不处理
}
payloadLen = buf[1] & 0x7F; // 数据长度
if (payloadLen == 126)
{
memcpy(masks,buf+4, 4);
payloadLen =(buf[2]&0xFF) << 8 | (buf[3]&0xFF);
payloadData=(char *)malloc(payloadLen);
memset(payloadData,0,payloadLen);
memcpy(payloadData,buf+8,payloadLen);
}
else if (payloadLen == 127)
{
memcpy(masks,buf+10,4);
for ( i = 0; i < 8; i++)
{
temp[i] = buf[9 - i];
}
memcpy(&n,temp,8);
payloadData=(char *)malloc(n);
memset(payloadData,0,n);
memcpy(payloadData,buf+14,n);//toggle error(core dumped) if data is too long.
payloadLen=n;
}
else
{
memcpy(masks,buf+2,4);
payloadData=(char *)malloc(payloadLen);
memset(payloadData,0,payloadLen);
memcpy(payloadData,buf+6,payloadLen);
}
for (i = 0; i < payloadLen; i++)
{
payloadData[i] = (char)(payloadData[i] ^ masks[i % 4]);
}
printf("data(%d):%s\n",payloadLen,payloadData);
return payloadData;
}
char * packData(const char * message,unsigned long * len)
{
char * data=NULL;
unsigned long n;
n=strlen(message);
if (n < 126)
{
data=(char *)malloc(n+2);
memset(data,0,n+2);
data[0] = 0x81;
data[1] = n;
memcpy(data+2,message,n);
*len=n+2;
}
else if (n < 0xFFFF)
{
data=(char *)malloc(n+4);
memset(data,0,n+4);
data[0] = 0x81;
data[1] = 126;
data[2] = (n>>8 & 0xFF);
data[3] = (n & 0xFF);
memcpy(data+4,message,n);
*len=n+4;
}
else
{
// 暂不处理超长内容
*len=0;
}
return data;
}
void response(int connfd,const char * message)
{
char * data;
unsigned long n=0;
int i;
if(!connfd)
{
return;
}
if(!data)
{
return;
}
data=packData(message,&n);
if(!data||n<=0)
{
printf("data is empty!\n");
return;
}
write(connfd,data,n);
}注意:
1.对于超过0xFFFF长度的数据在分析数据部分虽然作了处理,但是在memcpy时会报core dumped的错误,没有解决,请过路的大牛帮忙指点。在packData部分也未对这一部分作处理。
2.在这里碰到了一个郁闷的问题,在命名函数时,将函数名写的过长了(fetchSecWebSocketAcceptkey),结果导致编译通过,但在运行时却莫名其妙的报core dumped的错误,试了很多方法才发现是这个原因,后将名字改短后就OK了。
3.在回复数据时,只要按websocket的协议进行回应就可以了。
附上sha1、base64和intLib的代码(sha1和base64是从网上摘来的)
sha1.h
//sha1.h:对字符串进行sha1加密
#ifndef _SHA1_H_
#define _SHA1_H_
#include
#include
#include
typedef struct SHA1Context{
unsigned Message_Digest[5];
unsigned Length_Low;
unsigned Length_High;
unsigned char Message_Block[64];
int Message_Block_Index;
int Computed;
int Corrupted;
} SHA1Context;
void SHA1Reset(SHA1Context *);
int SHA1Result(SHA1Context *);
void SHA1Input( SHA1Context *,const char *,unsigned);
#endif
#define SHA1CircularShift(bits,word) ((((word) << (bits)) & 0xFFFFFFFF) | ((word) >> (32-(bits))))
void SHA1ProcessMessageBlock(SHA1Context *);
void SHA1PadMessage(SHA1Context *);
void SHA1Reset(SHA1Context *context){// 初始化动作
context->Length_Low = 0;
context->Length_High = 0;
context->Message_Block_Index = 0;
context->Message_Digest[0] = 0x67452301;
context->Message_Digest[1] = 0xEFCDAB89;
context->Message_Digest[2] = 0x98BADCFE;
context->Message_Digest[3] = 0x10325476;
context->Message_Digest[4] = 0xC3D2E1F0;
context->Computed = 0;
context->Corrupted = 0;
}
int SHA1Result(SHA1Context *context){// 成功返回1,失败返回0
if (context->Corrupted) {
return 0;
}
if (!context->Computed) {
SHA1PadMessage(context);
context->Computed = 1;
}
return 1;
}
void SHA1Input(SHA1Context *context,const char *message_array,unsigned length){
if (!length) return;
if (context->Computed || context->Corrupted){
context->Corrupted = 1;
return;
}
while(length-- && !context->Corrupted){
context->Message_Block[context->Message_Block_Index++] = (*message_array & 0xFF);
context->Length_Low += 8;
context->Length_Low &= 0xFFFFFFFF;
if (context->Length_Low == 0){
context->Length_High++;
context->Length_High &= 0xFFFFFFFF;
if (context->Length_High == 0) context->Corrupted = 1;
}
if (context->Message_Block_Index == 64){
SHA1ProcessMessageBlock(context);
}
message_array++;
}
}
void SHA1ProcessMessageBlock(SHA1Context *context){
const unsigned K[] = {0x5A827999, 0x6ED9EBA1, 0x8F1BBCDC, 0xCA62C1D6 };
int t;
unsigned temp;
unsigned W[80];
unsigned A, B, C, D, E;
for(t = 0; t < 16; t++) {
W[t] = ((unsigned) context->Message_Block[t * 4]) << 24;
W[t] |= ((unsigned) context->Message_Block[t * 4 + 1]) << 16;
W[t] |= ((unsigned) context->Message_Block[t * 4 + 2]) << 8;
W[t] |= ((unsigned) context->Message_Block[t * 4 + 3]);
}
for(t = 16; t < 80; t++) W[t] = SHA1CircularShift(1,W[t-3] ^ W[t-8] ^ W[t-14] ^ W[t-16]);
A = context->Message_Digest[0];
B = context->Message_Digest[1];
C = context->Message_Digest[2];
D = context->Message_Digest[3];
E = context->Message_Digest[4];
for(t = 0; t < 20; t++) {
temp = SHA1CircularShift(5,A) + ((B & C) | ((~B) & D)) + E + W[t] + K[0];
temp &= 0xFFFFFFFF;
E = D;
D = C;
C = SHA1CircularShift(30,B);
B = A;
A = temp;
}
for(t = 20; t < 40; t++) {
temp = SHA1CircularShift(5,A) + (B ^ C ^ D) + E + W[t] + K[1];
temp &= 0xFFFFFFFF;
E = D;
D = C;
C = SHA1CircularShift(30,B);
B = A;
A = temp;
}
for(t = 40; t < 60; t++) {
temp = SHA1CircularShift(5,A) + ((B & C) | (B & D) | (C & D)) + E + W[t] + K[2];
temp &= 0xFFFFFFFF;
E = D;
D = C;
C = SHA1CircularShift(30,B);
B = A;
A = temp;
}
for(t = 60; t < 80; t++) {
temp = SHA1CircularShift(5,A) + (B ^ C ^ D) + E + W[t] + K[3];
temp &= 0xFFFFFFFF;
E = D;
D = C;
C = SHA1CircularShift(30,B);
B = A;
A = temp;
}
context->Message_Digest[0] = (context->Message_Digest[0] + A) & 0xFFFFFFFF;
context->Message_Digest[1] = (context->Message_Digest[1] + B) & 0xFFFFFFFF;
context->Message_Digest[2] = (context->Message_Digest[2] + C) & 0xFFFFFFFF;
context->Message_Digest[3] = (context->Message_Digest[3] + D) & 0xFFFFFFFF;
context->Message_Digest[4] = (context->Message_Digest[4] + E) & 0xFFFFFFFF;
context->Message_Block_Index = 0;
}
void SHA1PadMessage(SHA1Context *context){
if (context->Message_Block_Index > 55) {
context->Message_Block[context->Message_Block_Index++] = 0x80;
while(context->Message_Block_Index < 64) context->Message_Block[context->Message_Block_Index++] = 0;
SHA1ProcessMessageBlock(context);
while(context->Message_Block_Index < 56) context->Message_Block[context->Message_Block_Index++] = 0;
} else {
context->Message_Block[context->Message_Block_Index++] = 0x80;
while(context->Message_Block_Index < 56) context->Message_Block[context->Message_Block_Index++] = 0;
}
context->Message_Block[56] = (context->Length_High >> 24 ) & 0xFF;
context->Message_Block[57] = (context->Length_High >> 16 ) & 0xFF;
context->Message_Block[58] = (context->Length_High >> 8 ) & 0xFF;
context->Message_Block[59] = (context->Length_High) & 0xFF;
context->Message_Block[60] = (context->Length_Low >> 24 ) & 0xFF;
context->Message_Block[61] = (context->Length_Low >> 16 ) & 0xFF;
context->Message_Block[62] = (context->Length_Low >> 8 ) & 0xFF;
context->Message_Block[63] = (context->Length_Low) & 0xFF;
SHA1ProcessMessageBlock(context);
}
/*
int sha1_hash(const char *source, char *lrvar){// Main
SHA1Context sha;
char buf[128];
SHA1Reset(&sha);
SHA1Input(&sha, source, strlen(source));
if (!SHA1Result(&sha)){
printf("SHA1 ERROR: Could not compute message digest");
return -1;
} else {
memset(buf,0,sizeof(buf));
sprintf(buf, "%08X%08X%08X%08X%08X", sha.Message_Digest[0],sha.Message_Digest[1],
sha.Message_Digest[2],sha.Message_Digest[3],sha.Message_Digest[4]);
//lr_save_string(buf, lrvar);
return strlen(buf);
}
}
*/
char * sha1_hash(const char *source){// Main
SHA1Context sha;
char *buf;//[128];
SHA1Reset(&sha);
SHA1Input(&sha, source, strlen(source));
if (!SHA1Result(&sha)){
printf("SHA1 ERROR: Could not compute message digest");
return NULL;
} else {
buf=(char *)malloc(128);
memset(buf,0,sizeof(buf));
sprintf(buf, "%08X%08X%08X%08X%08X", sha.Message_Digest[0],sha.Message_Digest[1],
sha.Message_Digest[2],sha.Message_Digest[3],sha.Message_Digest[4]);
//lr_save_string(buf, lrvar);
//return strlen(buf);
return buf;
}
}
base64.h
#ifndef _BASE64_H_
#define _BASE64_H_
#include
#include
#include
const char base[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";
char* base64_encode(const char* data, int data_len);
char *base64_decode(const char* data, int data_len);
static char find_pos(char ch);
/* */
char *base64_encode(const char* data, int data_len)
{
//int data_len = strlen(data);
int prepare = 0;
int ret_len;
int temp = 0;
char *ret = NULL;
char *f = NULL;
int tmp = 0;
char changed[4];
int i = 0;
ret_len = data_len / 3;
temp = data_len % 3;
if (temp > 0)
{
ret_len += 1;
}
ret_len = ret_len*4 + 1;
ret = (char *)malloc(ret_len);
if ( ret == NULL)
{
printf("No enough memory.\n");
exit(0);
}
memset(ret, 0, ret_len);
f = ret;
while (tmp < data_len)
{
temp = 0;
prepare = 0;
memset(changed, '\0', 4);
while (temp < 3)
{
//printf("tmp = %d\n", tmp);
if (tmp >= data_len)
{
break;
}
prepare = ((prepare << 8) | (data[tmp] & 0xFF));
tmp++;
temp++;
}
prepare = (prepare<<((3-temp)*8));
//printf("before for : temp = %d, prepare = %d\n", temp, prepare);
for (i = 0; i < 4 ;i++ )
{
if (temp < i)
{
changed[i] = 0x40;
}
else
{
changed[i] = (prepare>>((3-i)*6)) & 0x3F;
}
*f = base[changed[i]];
//printf("%.2X", changed[i]);
f++;
}
}
*f = '\0';
return ret;
}
/* */
static char find_pos(char ch)
{
char *ptr = (char*)strrchr(base, ch);//the last position (the only) in base[]
return (ptr - base);
}
/* */
char *base64_decode(const char *data, int data_len)
{
int ret_len = (data_len / 4) * 3;
int equal_count = 0;
char *ret = NULL;
char *f = NULL;
int tmp = 0;
int temp = 0;
char need[3];
int prepare = 0;
int i = 0;
if (*(data + data_len - 1) == '=')
{
equal_count += 1;
}
if (*(data + data_len - 2) == '=')
{
equal_count += 1;
}
if (*(data + data_len - 3) == '=')
{//seems impossible
equal_count += 1;
}
switch (equal_count)
{
case 0:
ret_len += 4;//3 + 1 [1 for NULL]
break;
case 1:
ret_len += 4;//Ceil((6*3)/8)+1
break;
case 2:
ret_len += 3;//Ceil((6*2)/8)+1
break;
case 3:
ret_len += 2;//Ceil((6*1)/8)+1
break;
}
ret = (char *)malloc(ret_len);
if (ret == NULL)
{
printf("No enough memory.\n");
exit(0);
}
memset(ret, 0, ret_len);
f = ret;
while (tmp < (data_len - equal_count))
{
temp = 0;
prepare = 0;
memset(need, 0, 4);
while (temp < 4)
{
if (tmp >= (data_len - equal_count))
{
break;
}
prepare = (prepare << 6) | (find_pos(data[tmp]));
temp++;
tmp++;
}
prepare = prepare << ((4-temp) * 6);
for (i=0; i<3 ;i++ )
{
if (i == temp)
{
break;
}
*f = (char)((prepare>>((2-i)*8)) & 0xFF);
f++;
}
}
*f = '\0';
return ret;
}
#endif
intLib.h
#ifndef _INT_LIB_H_
#define _INT_LIB_H_
int tolower(int c)
{
if (c >= 'A' && c <= 'Z')
{
return c + 'a' - 'A';
}
else
{
return c;
}
}
int htoi(const char s[],int start,int len)
{
int i,j;
int n = 0;
if (s[0] == '0' && (s[1]=='x' || s[1]=='X')) //判断是否有前导0x或者0X
{
i = 2;
}
else
{
i = 0;
}
i+=start;
j=0;
for (; (s[i] >= '0' && s[i] <= '9')
|| (s[i] >= 'a' && s[i] <= 'f') || (s[i] >='A' && s[i] <= 'F');++i)
{
if(j>=len)
{
break;
}
if (tolower(s[i]) > '9')
{
n = 16 * n + (10 + tolower(s[i]) - 'a');
}
else
{
n = 16 * n + (tolower(s[i]) - '0');
}
j++;
}
return n;
}
#endif
转载请注明出处 http://blog.csdn.net/xxdddail/article/details/19070149