Python数据分析实战基础(一):初识Pandas

作者 | 吹牛Z
来源 | 数据不吹牛
据某数据来源统计,学习了Pandas的同学,有超过60%仍然投向了Excel的怀抱,之所以做此下策,多半是因为刚开始用Python处理数据时,选择想要的行和列实在太痛苦,完全没有Excel想要哪里点哪里的快感。
第一篇潘大师(初识Pandas)教程考虑到篇幅问题只讲了最基础的列向索引,但这显然不能满足同志们日益增长的个性化服务(选取)需求。为了舒缓痛感,增加快感,满足需求,第二篇内容我们单独把索引拎出来,结合场景详细介绍两种常用的索引方式:
- 第一种是基于位置(整数)的索引,案例短平快,有个粗略的了解即可,实际中偶有用到,但它的应用范围不如第二种广泛。
- 第二种是基于名称(标签)的索引,这是要敲黑板练的重点,因为它将是我们后面进行数据清洗和分析的重要基石。
首先,简单介绍一下练习的案例数据:
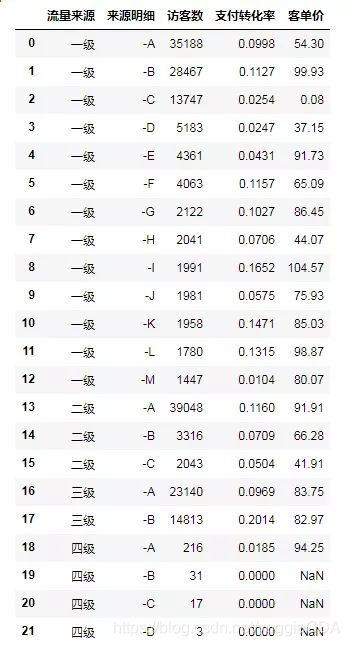
和第一篇数据集一样,记录着不同流量来源下,各渠道来源明细所对应的访客数、支付转化率和客单价。数据集虽然简短(复杂的案例数据集在基础篇完结后会如约而至),但是有足够的代表性,下面开始我们索引的表演。

01 基于位置(数字)的索引
先看一下索引的操作方式:

我们需要根据实际情况,填入对应的行参数和列参数。
场景一(行选取)
目标:选择“流量来源”等于“一级”的所有行。
思路:手指戳屏幕数一数,一级的渠道,是从第1行到第13行,对应行索引是0-12,但Python切片默认是含首不含尾的,要想选取0-12的索引行,我们得输入“0:13”,列想要全部选取,则输入冒号“:”即可。
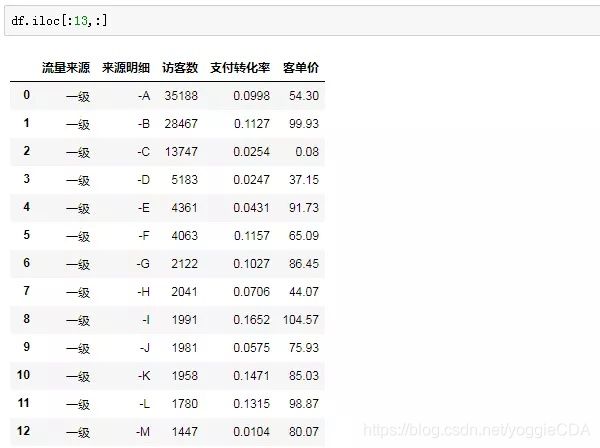
场景二(列选取)
目标:我们想要把所有渠道的流量来源和客单价单拎出来看一看。
思路:所有流量渠道,也就是所有行,在第一个行参数的位置我们输入“:”;再看列,流量来源是第1列,客单价是第5列,对应的列索引分别是0和4:
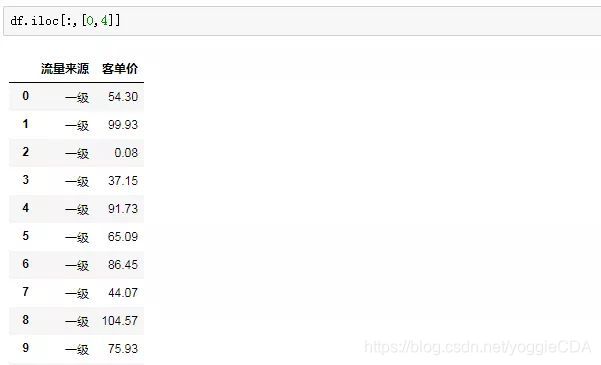
值得注意的是,如果我们要跨列选取,得先把位置参数构造成列表形式,这里就是[0,4],如果是连续选取,则无需构造成列表,直接输入0:5(选取索引为0的列到索引为4的列)就好。
场景三(行列交叉选取)
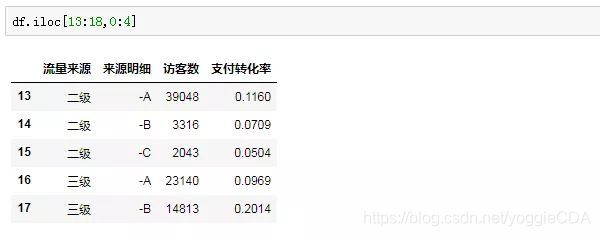
目标:我们想要看一看二级、三级流量来源、来源明细对应的访客和支付转化率
思路:先看行,二级三级渠道对应行索引是13:17,再次强调索引含首不含尾的原则,我们传入的行参数是13:18;列的话我们需要流量来源、来源明细、访客和转化,也就是前4列,传入参数0:4。
02 基于名称(标签)的索引
为了建立起横向对比的体感,我们依然沿用上面三个场景。
场景一:选择一级渠道的所有行。
思路:这次我们不用一个个数位置了,要筛选流量渠道为"一级"的所有行,只需做一个判断,判断流量来源这一列,哪些值等于"一级"。

返回的结果由True和False(布尔型)构成,在这个例子中分别代表结果等于一级和非一级。在loc方法中,我们可以把这一列判断得到的值传入行参数位置,Pandas会默认返回结果为True的行(这里是索引从0到12的行),而丢掉结果为False的行,直接上例子:

场景二:我们想要把所有渠道的流量来源和客单价单拎出来看一看。
思路:所有渠道等于所有行,我们在行参数位置直接输入“:”,要提取流量来源和客单价列,直接输入名称到列参数位置,由于这里涉及到两列,所以得用列表包起来:

场景三:我们想要提取二级、三级流量来源、来源明细对应的访客和支付转化率。
思路:行提取用判断,列提取输入具体名称参数。
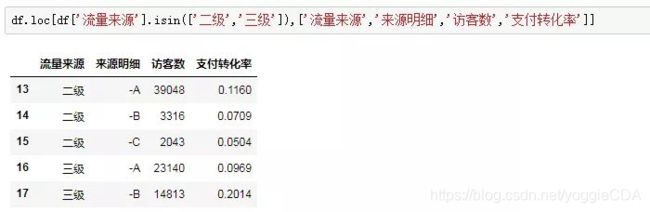
此处插播一条isin函数的广告,这个函数能够帮助我们快速判断源数据中某一列(Series)的值是否等于列表中的值。拿案例来说,df[‘流量来源’].isin([‘二级’,‘三级’]),判断的是流量来源这一列的值,是否等于“二级”或者“三级”,如果等于(等于任意一个)就返回True,否则返回False。我们再把这个布尔型判断结果传入行参数,就能够很容易的得到流量来源等于二级或者三级的渠道。
既然loc的应用场景更加广泛,应该给他加个鸡腿,再来个接地气的场景练练手。
插入场景之前,我们先花30秒的时间捋一捋Pandas中列(Series)向求值的用法,具体操作如下:

只需要加个尾巴,均值、标准差等统计数值就出来了,了解完这个,下面正式进入场景四。
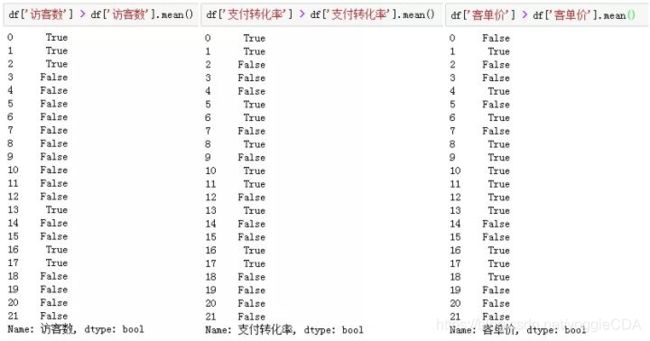
场景四:对于流量渠道数据,我们真正应该关注的是优质渠道,假如这里我们定义访客数、转化率、客单价都高于平均值渠道是优质渠道,那怎么找到这些渠道呢?
思路:优质渠道,得同时满足访客、转化、客单高于平均值这三个条件,这是解题的关键。
先看看均值各是多少:

再判断各指标列是否大于均值:
要三个条件同时满足,他们之间是一个“且”的关系(同时满足),在pandas中,要表示同时满足,各条件之间要用"&"符号连接,条件内部最好用括号区分;如果是“或”的关系(满足一个即可),则用“|”符号连接:

这样连接之后,返回True则表示该渠道同时满足访客、转化率、客单价都高于均值的条件,接下来我们只需要把这些值传入到行参数的位置。
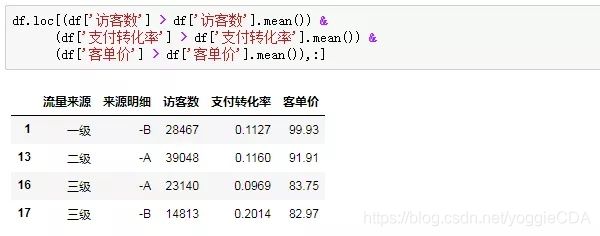
到这一步,我们直接筛选出了4条关键指标都高于均值的优质渠道。
这两种索引方式,分别是基于位置(数字)的索引和基于名称(标签)的索引,关键在于把脑海中想要选取的行和列,映射到对应的行参数与列参数中去。
只要稍加练习,我们就能够随心所欲的用pandas处理和分析数据,迈过了这一步之后,你会发现和Excel相比,Python是如此的美艳动人。
这是Python数据分析实战基础的第一篇内容,主要是和Pandas来个简单的邂逅。已经熟练掌握Pandas的同学,可以加快手速滑动浏览或者直接略过本文。
搜索···进入···解锁···更多专业内容和优质资讯,不要错过哟!
