pytorch对植物病虫害迁移学习分类
一、 项目描述
针对在大规模农业种植中传统人工农作物病虫害预防和治理上存在的问题同,应用深度学习算法来进行农作物病虫害的检测,对农作物荧光图片进行病害识别检测,包含多个农作物物种。采用目前流行的深度网络结构,如深度神经网络图像进行特征抽取,采用交叉熵和正则化项组成损失函数进行反向传播调整,对数据集进行不同情况的划分;并且使用迁移训练训练方式,最终达到根据摄像头采集的荧光照片能够分析出该植物可能有的病症。
二、 识别系统设计
如下图所示:
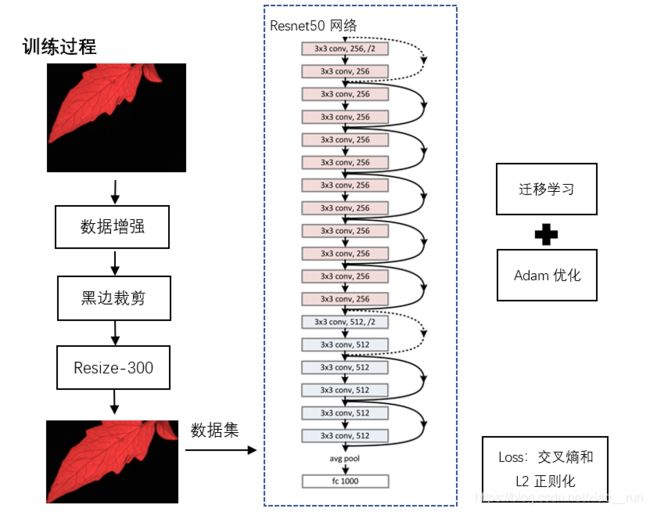

三 实验步骤
实验采用python编程语言,版本为3.7,以及深度学习开源框架pytorch,另外采用开源库numpy、pyqt5等
1.预处理
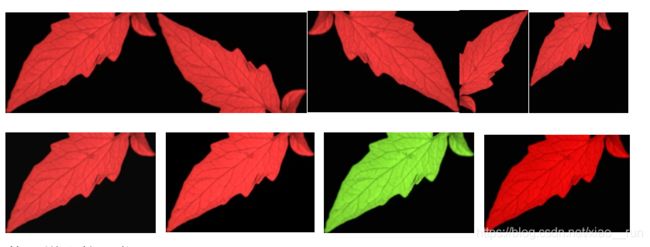
训练之前,首先对三个类别所有的原图进行数据增强,分别进行了水平、垂直、旋转180度、随机改变亮度、随机改变对比度、随机改变色度以及饱和度,每张图片可获得8张增强图片,下图为其中一张举例。
原始数据为1503,每个类别150张,增强后的数据数据集为12003,每个类别1200张,总计3600张。随机分配10%作为测试集,10%作为交叉验证集,剩下全部作为训练集。输入网络之前,还需要对图片进行黑边裁剪操作以及resize到300*300大小。
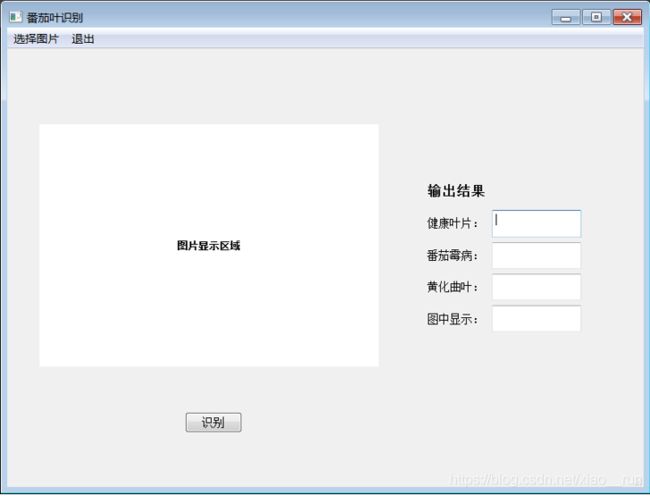
四、界面设计
为了方便使用,设计了如下建议简易界面:
五、核心代码整合
以下为vgg19与resnet18训练与测试代码
1、首先数据增强代码:
import PIL.Image as Image
import os
from torchvision import transforms as transforms
outfile = './samples'
im = Image.open('./test.jpg')
im.save(os.path.join(outfile, 'test.jpg'))
new_im = transforms.Resize((100, 200))(im)
print(f'{im.size}---->{new_im.size}')
new_im.save(os.path.join(outfile, '1.jpg'))
new_im = transforms.RandomCrop(100)(im) # 裁剪出100x100的区域
new_im.save(os.path.join(outfile, '2_1.jpg'))
new_im = transforms.CenterCrop(100)(im)
new_im.save(os.path.join(outfile, '2_2.jpg'))
new_im = transforms.RandomHorizontalFlip(p=1)(im) # p表示概率
new_im.save(os.path.join(outfile, '3_1.jpg'))
new_im = transforms.RandomVerticalFlip(p=1)(im)
new_im.save(os.path.join(outfile, '3_2.jpg'))
new_im = transforms.RandomRotation(45)(im) #随机旋转45度
new_im.save(os.path.join(outfile, '4.jpg'))
new_im = transforms.ColorJitter(brightness=1)(im)
new_im = transforms.ColorJitter(contrast=1)(im)
new_im = transforms.ColorJitter(saturation=0.5)(im)
new_im = transforms.ColorJitter(hue=0.5)(im)
new_im.save(os.path.join(outfile, '5_1.jpg'))
new_im = transforms.RandomGrayscale(p=0.5)(im) # 以0.5的概率进行灰度化
new_im.save(os.path.join(outfile, '6_2.jpg'))
搭建神经网络vgg19或者resnet18训练代码:
from __future__ import print_function,division
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
from torch.autograd import Variable
from torchvision import datasets,models,transforms
import matplotlib.pyplot as plt
import time
import os
import copy
import cv2
plt.ion()
#load data
data_transforms=\
{
'train': transforms.Compose([
transforms.RandomResizedCrop(300),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(300),
transforms.CenterCrop(300),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir="/home/nebula/Desktop/classfication/image"
image_datasets = {
x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {
x: torch.utils.data.DataLoader(image_datasets[x], batch_size=32,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
dataset_sizes = {
x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#load test data
def loadtestdata():
path="/home/nebula/Desktop/classfication/image"
test_test=torchvision.datasets.ImageFolder(path,transform=transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor()]))
testloader = torch.utils.data.DataLoader(test_test, batch_size=25,shuffle=True, num_workers=4)
return testloader
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# Get a batch of training data
inputs, classes = next(iter(dataloaders['train']))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
#imshow(out, title=[class_names[x] for x in classes])
#trainning a model
def train_model(model, criterion, optimizer, scheduler, num_epochs=100):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
print('Finished Training')
torch.save(model, 'net_721.pkl')
torch.save(model.state_dict(), 'net_params_721.pkl')
# load best model weights
model.load_state_dict(best_model_wts)
return model
def reload_net():
trainednet = torch.load('net.pkl')
return trainednet
#Visualizing the model predictions
def test():
testloader = loadtestdata()
net = reload_net()
dataiter = iter(testloader)
images, labels = dataiter.next() #
imshow(torchvision.utils.make_grid(images, nrow=5))
def visualize_model(model, num_images=6):
was_training = model.training
model.eval()
images_so_far = 0
fig = plt.figure()
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders['val']):
print(inputs,labels)
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images//2, 2, images_so_far)
ax.axis('off')
ax.set_title('predicted: {}'.format(class_names[preds[j]]))
imshow(inputs.cpu().data[j])
plt.pause(10)
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
#Finetuning the convnet
model_ft=models.vgg19(pretrained=True)
#model_ft=models.resnet18(pretrained=True)
#若采用resnet18请取消这行注释,改为注释上面vgg19
for param in model_ft.parameters():
param.requires_grad = False
'''
若是resnet18,打开以下两行注释
#num_ftrs = model_ft.fc.in_features
#model_ft.fc = nn.Linear(num_ftrs, 3)
'''
# Here the size of each output sample is set to 2.
# Alternatively, it can be generalized to nn.Linear(num_ftrs,
model_ft.classifier = torch.nn.Sequential(torch.nn.Linear(25088, 4096),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(4096, 4096),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(4096, 3))
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=10, gamma=0.1)
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,
num_epochs=25)
#test_data=loadtestdata()
#net=reload_net()
#visualize_model(net)
#data_iter=iter(test_data)
#images,labels=data_iter.next()
#imshow(torchvision.utils.make_grid(images,nrow=5))
#print('GroundTruth: ', " ".join('%5s' % classes[labels[j]] for j in range(2)))
#outputs = net(Variable(images))
#_, predicted = torch.max(outputs.data, 1)
#print('Predicted: ', " ".join('%5s' % classes[predicted[j]] for j in range(2)))
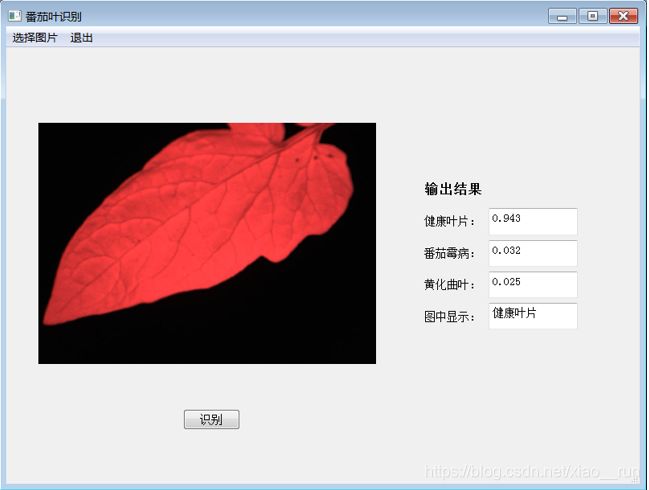
训练完之后效果图如下:
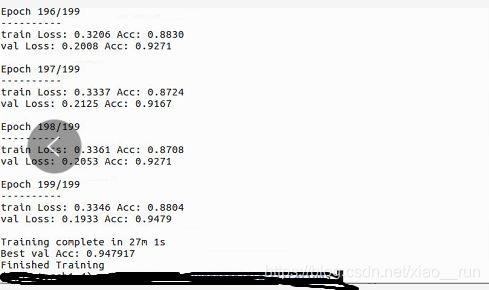
我们可以看到测试的精度在94%左右
最终的测试代码如下:
from __future__ import print_function,division
import torch
import torch.nn.functional as F
import os
from torch.autograd import Variable
import numpy as np
from torchvision import datasets,models,transforms
import matplotlib.pyplot as plt
import cv2
data_dir="/home/nebula/Xiao_run/data"
classess=("0","1","2")
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
data_transforms=\
{
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
image_datasets = {
x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {
x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
dataset_sizes = {
x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def visualize_model(model, num_images=6):
was_training = model.training
model.eval()
images_so_far = 0
fig = plt.figure()
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders['val']):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images//2, 2, images_so_far)
ax.axis('off')
ax.set_title('predicted: {}'.format(class_names[preds[j]]))
imshow(inputs.cpu().data[j])
plt.pause(10)
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
def reload_net():
trainednet = torch.load('net.pkl')
return trainednet
#Visualizing the model predictions
net=reload_net()
net.eval()
#visualize_model(net)
path="/home/nebula/Desktop/classfication/test"
img_path=os.listdir(path)
for img in img_path:
frame_=cv2.imread(os.path.join(path,img))
#frame=img[500:1000,400:1500]
cv2.imshow("test", frame_)
frame=cv2.resize(frame_,(224,224))
tensor_cv = torch.from_numpy(np.transpose(frame, (2, 0, 1))).float()/255.0
tensor_cv=tensor_cv[np.newaxis,:,:,:]
tensor_cv=Variable(tensor_cv)
torch.no_grad()
tensor_cv=tensor_cv.cuda()
outputs=net(tensor_cv)
preds=F.softmax(outputs)
_, preds = torch.max(preds, 1)
print("imagge {} is...".format(img), classess[preds])
key=cv2.waitKey(100)
if key==ord("q"):
break
最终效果还是vgg19稍微好一些,大家学习即可