伯禹公益AI《动手学深度学习PyTorch版》Task 04 学习笔记
伯禹公益AI《动手学深度学习PyTorch版》Task 04 学习笔记
Task 04:机器翻译及相关技术;注意力机制与Seq2seq模型;Transformer
微信昵称:WarmIce
PS: 所有使用的图片均来自《动手学深度学习PyTorch版》项目。
机器翻译及相关技术
机器翻译不能用普通的循环神经网络来实现。想想咱们之前的循环神经网络,在机器翻译中,有个最直观的问题,就是输入序列和输出序列长度很有可能不同;再一个,之前咱们用循环神经网络,归根到底,一次不过是预测一个单词(或者汉字)而已,而进行机器翻译时则需要输出一整个不同的单词序列。另外一点,讲者没有提,但是是我个人的直觉,就是说在机器翻译中,存在一个语义的转换问题,使用简单的循环神经网络相当捉襟见肘。
话不多说,对于数据集,上来就是个清洗。这里就有个Tips啦,关于空格的。
字符在计算机里是以编码的形式存在,我们通常所用的空格是 \x20 ,是在标准ASCII可见字符 0x20~0x7e 范围内。
而 \xa0 属于 latin1 (ISO/IEC_8859-1)中的扩展字符集字符,代表不间断空白符nbsp(non-breaking space),超出gbk编码范围,是需要去除的特殊字符。在数据预处理的过程中,我们首先需要对数据进行清洗。
然后同样地,建立字典,只不过现在需要两个字典,一个是src_vocab,另一个是tgt_vocab。
在机器翻译中,我们输入的是一个句子,每次输入的句子长度肯定不可能长度完全相同,因此我们通过pad函数,对于每一条句子,长则割之、短则补之。
接下来就要建立数据集了,这就用到了build_array函数。要注意,对于tgt_vocab,我们需要在每个句子前面补上
接着使用torch.utils.data.TensorDataset和torch.utils.data.DataLoader分别装入数据并载入数据得到迭代器。
现在数据集已经准备好啦,接着就可以开心地学习模型啦。
有请大名鼎鼎的Encoder-Decoder结构登场!
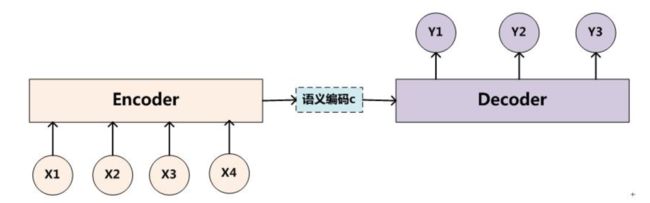
Encoder负责由输入得到隐藏状态,我理解其为高维特征向量,Decoder负责由该隐藏状态得到输出。
当然了,这个所谓的Encoder-Decoder只是一种模型的模式,所以说给出的代码就是一个框架,就是说Encoder的输入是被翻译的句子,由Encoder得到语义编码信息H,Decoder给定输入的这个编码信息H得到输出,即翻译出来的句子。这里有两点要说明,第一,对于Encoder而言,我们一点都不关心它的输出是什么,我们只关系由它得到的语义编码信息,对于Decoder,我们一点也不关心由它得到的语义编码信息,我们只管它的输出。第二,Decoder在训练的时候,第一个给的输入是
训练
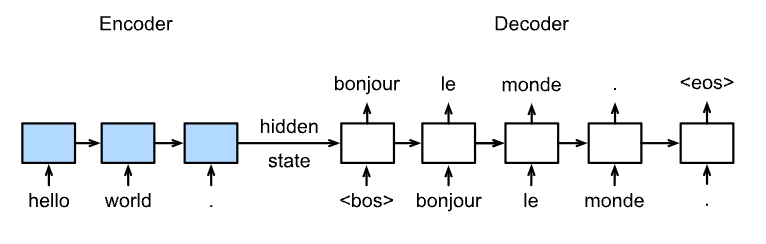
预测
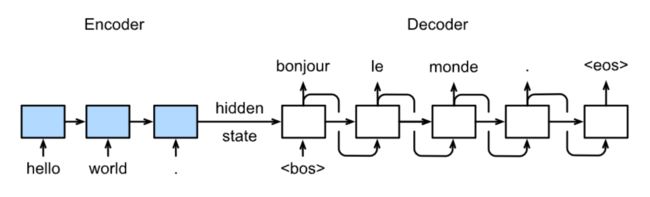
下面就是所谓的机器翻译模型登场了:Seq2seq。
有人就要问了,这特么Encoder-Decoder和Seq2seq到底有啥关系啊?
Seq2Seq(强调目的)不特指具体方法,满足「输入序列、输出序列」的目的,都可以统称为 Seq2Seq 模型。
而 Seq2Seq 使用的具体方法基本都属于Encoder-Decoder 模型(强调方法)的范畴。
总结一下的话:
Seq2Seq 属于 Encoder-Decoder 的大范畴
Seq2Seq 更强调目的,Encoder-Decoder 更强调方法
所以说Encoder-Decoder可以干更多别的事情,比如音频-文本、图片-文本,本质上是信息的压缩和解压,这也就导致Encoder-Decoder天生有个缺陷,就是当输入信心过长时,必然会丢失信息。
重点来了,这个丫的讲者又没有仔细讲解!
我们仔细一看,靠,这个Embedding是什么?作为一个外行人,我真的不太懂啊。后来一查,才发现大有名堂,首先,联想一下,我们之前送到循环神经网络之前,都需要将每个单词(或者汉字)映射成一个one-hot向量,那大家想象,一旦单词量大了,这个向量的大小就无可避免地会变得非常大,且是离散的,而Embedding这一步,让我们能够远离one-hot, 使用Embedding ,直接由不同的id映射成不同的词向量(嘿嘿,word2vec)。这个词向量两个好处 , 一、不会那么长;二、连续的,可随训练过程调优的。pytorch中的nn.Embedding帮我们做了这一步。不过呢,给出的这个例子里面,好像还是先把输入映射成one-hot,然后再走Embedding,很是蹊跷,我们等高人答疑。
我又研究了一下,感觉应该还是先映射成one-hot向量后,才进行Embedding的,dense输出的时候,直接输出vocab_size大小的向量。
接着就是损失函数了。
这里我们需要一个mask,因为输出的地方虽然说是变长,但是特么还是固定的一张计算图啊,该有几个输出就是几个输出,只是有的不用去管而已。
训练的时候要注意,Y的valid length是要减去1的,因为输入会少
同时,今天再一次加深对于这个狗屁CrossEntropyLoss()的理解:
import torch
l=torch.nn.CrossEntropyLoss()
a = torch.randn((2, 10, 2))
print(l(a, torch.Tensor([[0, 2], [2, 0]]).long()))
这也就是例子里面:
output=super(MaskedSoftmaxCELoss, self).forward(pred.transpose(1,2), label)
之所以要进行transpose的原因。
也就是说,使用这个函数的时候,你的pred的形状是[batchsize, vocab_size, seq_len],你的target的形状得是[batchsize, seq_len]。
测试的时候,就直接将需要翻译的句子先处理一下(若长度不足则补全并转化为token),然后得到输入与valid length。送入Encoder网络,得到隐藏状态变量。Decoder网络初始化隐藏状态变量,第一个输入设为
这里注意,翻译输出的时候,我们是根据每次的输出向量的最值对应ID的单词做的输出。这也就导致了一个问题。
也就是说这是个局部最优解,每次只考虑了单个单词的最佳选项,并没有考虑输出的单词前后之间的关系。这时候就轮到我们最后一位主角登场了:Beam Search。
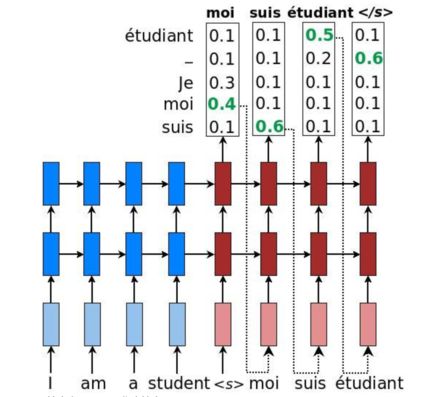

我觉得挺好理解的,就不做赘述了。集束搜索是可以设置集束的个数的,像上面这张图,就是把搜索的集束设为了2。从而达到一个全局优解的效果。
注意力机制和Seq2seq模型
半天了,终于请求到计算资源了。上午有一阵子,我还用着好好的,直接给我掐断kernel,有点过分啊。
其实之前吧,我就想说,你看这个Encoder,它输出的隐藏状态变量有那么香吗,就像之前提到的,句子一旦长了,很难寄希望于将输入的序列转化为定长的向量而保存所有的有效信息,所以随着所需翻译句子的长度的增加,RNN这种结构的效果会显著下降。翻译的时候吧,很多时候又是单词之间的一一对应关系,但是你看咱们之前的结构哈,那直接就是用Encoder输出的隐藏状态变量,隐式地抽取其中与应当翻译的词之间的关系,这就很不好。
注意力机制有效地改善了这一状况。
这个机制里面有三个名词,说起来也听简单,想象一个数据库,里面有键值对,就是说,有很多键(key),也有很多值(value),此时,我么有一个查询(query),那么这个数据库面对这个查询,如何操作呢?

首先假设有一个函数 α \alpha α 用于计算query和key的相似性,然后就可以计算所有的 attention scores a 1 , … , a n a_1, \ldots, a_n a1,…,an :
a i = α ( q , k i ) . a_i = \alpha(\mathbf q, \mathbf k_i). ai=α(q,ki).
接着使用softmax函数获得注意力权重,softmax有效地归一化了这些score,你可以把这个理解成数据库面对这个query,每个键(key)的归一化了的响应,因此也可以将上面的函数 α \alpha α看成一个响应函数:
b 1 , … , b n = softmax ( a 1 , … , a n ) . b_1, \ldots, b_n = \textrm{softmax}(a_1, \ldots, a_n). b1,…,bn=softmax(a1,…,an).
最终的输出就是value的加权求和:
o = ∑ i = 1 n b i v i . \mathbf o = \sum_{i=1}^n b_i \mathbf v_i. o=i=1∑nbivi.

不同的attetion layer的区别就在于计算score函数的选择,也就是我们理解的响应函数。
一般来说有两种函数选择,第一种是点积注意力。

attention里面还可以设置dropout,来随机删除一些注意力权重,增加网络的鲁棒性。
所以说,上面的这张图具有一定的误导含义,因为value和key的长度不一定相等,但是,这个狗币却画成了一样长的,你说狗不狗?
然后吧,讲的人也讲得很差,乱七八糟的,那个notebook中英文混杂,什么意思?不想做就别做,要是做了,请问能不能好好做一做?搞成这个样子。。。。。
那么一般来说,我们送进去的query的大小,其 m = 1 m=1 m=1,也就是说是只有一条query扔进去进行计算的,那么上面那样计算的过程就是多个query利用矩阵进行计算。你可以注意到其中给的测试的那个例子,那个例子里面 m = 1 m=1 m=1。
另一种选择就是多层感知注意力。
想一想,要是key和query长度不同,上面的那一套就没法运算下去,对吧?因此,这个多层感知注意力,就是用了(2+1)个全连接层,包治百病。
管你什么长度的key和什么长度的query呢,2个全连接直接把你们都变成长度 h h h,这还不得劲,你俩得激活一下啊对不对,那就走一个 t a n h tanh tanh,行吧,不行?还不够,我要的是这个query与这个key的相似度啊,这是一个值啊,不是一个向量,因此还要走1个全连接,输出一个值,就是我们梦寐以求的score。

由上面这些,最终得到 1 × n 1 \times n 1×n维的score矩阵,再和values矩阵相乘,就又变成了 1 × v 1 \times v 1×v的大小。(这里, 1 = m 1=m 1=m)
没毛病吧,如果老铁感觉没毛病,就请老铁双击666。
上面这些,都还只是基础,理论而已,纸上谈兵,要让我们用在seq2seq里面,到底怎么用,换句话说,seq2seq里面,谁是key?谁是value?谁是query?
相信,所有看了这一部分notebook的童鞋,都能感受到,做这个notebook的人,你特么是什么意思?!那些中文您是认真的吗?狗屁不通。
好的,那让我们来好好捋一捋。
首先,开宗明义,Encoder不用变,是输出就是输出(output),是状态变量就是状态变量(state),啥也没变。但是,我们要想到,在之前的seq2seq模型中,我们根本就没有理会Encoder的输出(output),在Decoder中,我们init_state的时候,直接用了state变量,output变量根本就没正眼看过,对不对?
大人,时代变了。现在,我们要用上这个output量了。
好的,我们之前已经得到,
encoder输出的output的size是[seq_len, batchsize, num_hiddens],输出的state的size是[num_states, num_layers, batchsize, num_hiddens]。
Decoder在init_state之后的输出是(outputs.permute(1,0,-1), hidden_state, enc_valid_len),其又被Decoder的forward函数直接使用,并对应重新命名为enc_outputs, hidden_state, enc_valid_len。
那么,enc_outputs的size就是[batchsize, seq_len, num_hiddens],hidden_state的size就是[num_states, num_layers, batchsize, num_hiddens]。
接着,对于所有时间步的X,都这样做:
query = hidden_state[0][-1].unsqueeze(1) 这一步使得query的形状为[batchsize, 1, num_hiddens]
相信看到之后的代码,您就能回答上面的三个问题了。
enc_outputs既是key,也是value,而hidden_state在经过Decoder的rnn网络后刷新,从而构成新的query。
得到query后,送入attention模块得到context,然后,最奇葩的地方来了。
竟然,要将这个context和要输入decoder的x级联起来,然后送入Decoder里面,你们应该注意到,LSTM在初始化的时候为:
self.rnn = nn.LSTM(embed_size + num_hiddens,num_hiddens, num_layers, dropout=dropout)
看到那个亮眼的加号了吗?
好的,到此为止,带attention的seq2seq模型就很清楚了。

Transformer
终于,我们来到了这个NB哄哄的Transformer。高山仰止也要上高山。Let’s do it!
事物都是发展的,对于机器翻译这件事情呢,CNN做不了,RNN又做不好,加上Attention的RNN呢也就那样,都不够硬。时代需要英雄的时候总是会出现英雄,那就是Transformer。

整个Transformer是由一些部件构成的,可以从图中看到,名字都挺吓人:Multi-head attention(多头注意力,跟个怪物似的),Position-wise Feed-Forward Network(基于位置的前馈网络,丫的又想起了被自控原理支配的恐惧),Add and Norm(不知道取什么中文名,看起来很矩阵理论)。
那咱么就先从多头注意力开始讲起,多图怪物长啥样呢,就下面这损样:

看着就来气有木有,官方给的例程里面的代码注释您看了会更生气(终于明白为什么课程免费了),注释里面的变量和代码里面的变量同名不同义,搁谁受得了?谁要是真交了钱来上这课,那不得气死。
官方给的代码其实实现这个还是实现得非常漂亮的,奈何注释sb。总之,官方的实现宗旨就是,不用for循环来走不同的attentiont头,那咋整呢?还是得用祖传瑰宝“矩阵运算”大法。就拿其中一个输入Queries举例,既然在这个 h h h个头都要走全连接,那索性一起走完事儿了!Happy!您说后面走不同的attention模块咋办?Ahhhh,敢问阁下用的什么attention模块啊?哦,点积注意力模块啊,那好啊,那不就还是矩阵相乘嘛!索性attention也一起矩阵运算走完算了!只不过这样子涉及矩阵的变形,变来变去,没有官方大佬那般的修炼底气,别随便这么写。
抬走!下一位!
Position-wise Feed-Forward Network(基于位置的前馈网络)。名字听着挺复杂,其实就俩全连接层,至于为啥叫这个名字,咱们现在是“只在此山中,云深不知处”,到后面纵观全局才可能有答案。但是很明显的一个作用在于,可以使用这个结构调整输入tensor的最后一维的长度。
抬走吧…
Add and Norm。
self.norm(self.dropout(Y) + X)
就这么一句话的意思,对Y进行一定程度的裁剪,防止过拟合。这里多说一句啊,上面的多头注意力,同样有防止过拟合的功效,居家必备。
位置编码。
与循环神经网络不同,无论是多头注意力网络还是前馈神经网络都是独立地对每个位置的元素进行更新,这种特性帮助我们实现了高效的并行,却丢失了重要的序列顺序的信息。为了更好的捕捉序列信息,Transformer模型引入了位置编码去保持输入序列元素的位置。
假设输入序列的嵌入表示 X ∈ R l × d X\in \mathbb{R}^{l\times d} X∈Rl×d, 序列长度为 l l l嵌入向量维度为 d d d,则其位置编码为 P ∈ R l × d P \in \mathbb{R}^{l\times d} P∈Rl×d ,输出的向量就是二者相加 X + P X + P X+P。
位置编码是一个二维的矩阵,i对应着序列中的顺序,j对应其embedding vector内部的维度索引。我们可以通过以下等式计算位置编码:
P i , 2 j = s i n ( i / 1000 0 2 j / d ) P_{i,2j} = sin(i/10000^{2j/d}) Pi,2j=sin(i/100002j/d)
P i , 2 j + 1 = c o s ( i / 1000 0 2 j / d ) P_{i,2j+1} = cos(i/10000^{2j/d}) Pi,2j+1=cos(i/100002j/d)
f o r i = 0 , … , l − 1 a n d j = 0 , … , ⌊ ( d − 1 ) / 2 ⌋ for\ i=0,\ldots, l-1\ and\ j=0,\ldots,\lfloor (d-1)/2 \rfloor for i=0,…,l−1 and j=0,…,⌊(d−1)/2⌋

之前在组会上有老师提到过这个东西,不过当时他并没有说清楚为什么要用这个。很显然,这个Transformer有了并行运算的优点,但是对于sequence而言最重要的序列顺序信息却丢失了,或者说没有被加强。那么这个位置编码就很有用了。有个问题哈,为什么公式里面是10000?其实这个就是这么取的,您取99999也行,就是说要求大一点,只要保证比输入的那个要区分顺序的序列的长度大就可以了,这样就能够区分这个序列的前后顺序了,就是这么个意思。
好了,有了上面这些组件,咱们来看,究竟怎么整这个模型,首先啊,这个Transformer模型呢,整体也就是个Encoder-Decoder的架构。
咱们先说Encoder,注意到,这里有个自注意机制的应用,您要是仔细看了代码的话,就会发现,这个attention的query、key和value都特娘的是X,这就叫自注意力,懂了吧?一个EncoderBlock呢,您就按照图上画的那个去搭建就行了:
class EncoderBlock(nn.Module):
def __init__(self, embedding_size, ffn_hidden_size, num_heads,
dropout, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention = MultiHeadAttention(embedding_size, embedding_size, num_heads, dropout)
self.addnorm_1 = AddNorm(embedding_size, dropout)
self.ffn = PositionWiseFFN(embedding_size, ffn_hidden_size, embedding_size)
self.addnorm_2 = AddNorm(embedding_size, dropout)
def forward(self, X, valid_length):
Y = self.addnorm_1(X, self.attention(X, X, X, valid_length))
return self.addnorm_2(Y, self.ffn(Y))
整个TransformerEncoder呢,就是堆叠上面这样的结构多次,不过这个结构的输入X怎么构建呢,还有上面提到的位置编码在模块里没有用到啊?很简单,对于整个Encoder的输入,我们由one-hot向量经Embedding后乘以 d \sqrt{d} d 以防止其值过小,然后再进行位置编码,然后就开开心心送到后面一个接一个的EncoderBlock里面就可以啦。比如输入的size是[seq_len, vocab_size],则得到的Encoder输出size就是[seq_len, vocab_size, embedding_size]。
接着咱们就可以说一说Decoder了。还是按照图片里面给出的样子堆叠。说到Decoder,您必须情不自禁地要想到预测的时候咋整。训练的时候当然原本一整个翻译好的句子当仁不让送进去直接训练啦,但是测试的时候呢?要注意的是,在第t个时间步,当前输入 x t x_t xt是query,那么self attention接受了第t步以及前t-1步的所有输入 x 1 , … , x t − 1 x_1,\ldots, x_{t-1} x1,…,xt−1。在训练时,由于第t位置的输入可以观测到全部的序列,这与预测阶段的情形项矛盾,所以我们要通过将第t个时间步所对应的可观测长度设置为t,以消除不需要看到的未来的信息。
以上。
(真的很难,看了一天,最后这个Transformer的Decoder部分还有一些疑问,明天不看了,后天补。头疼,抑郁。)