【综述】对抗样本生成及攻防技术综述
作者是电子科技大学的刘小垒等,2019年发表在计算机应用研究
主要内容:
以机器学习的安全性问题为出发点,介绍了当前机器学习面临的隐私攻击、完整性攻击等安全问题,归纳了目前常见对抗样本生成方法的发展过程及各自的特点,总结了目前已有的针对对抗样本攻击的防御技术,最后对提高机器学习算法鲁棒性的方法做了进一步的展望。
一、机器学习模型的攻击方式
1.1一般说来,对机器学习模型的攻击方式包括破坏模型的机密性 (confidentiality) 、完整性 integrity) 和 可 用 性 (availability)。同时,这三个性质也构成了 CIA 安全模型:
a)机密性是指机器学习模型在训练过程中必须保证已有数据集中的信息不被泄露,比如医疗系统中病人的病例或诊断结果;
b)完整性是指机器学习模型必须保证同类别样本被归类到相同的类中,反馈结果不会因某些原因而偏离,比如垃圾邮件通过伪装造成分类器的误识别;
c)可用性是保证所有的数据集可持续的供机器学习模型来使用。
1.2另一方面,安全研究人员将常见的针对机器学习模型的攻击分为三类:隐私攻击、针对训练数据的攻击以及针对算法模型的攻击。
1)隐私攻击,这类攻击者通过观察模型来预测某些敏感信息,或者通过已有的部分数据来恢复数据集中的敏感数据。
2)针对训练数据的攻击,攻击者通过修改现有数据或注入精心制作的恶意数据来对系统的完整性造成影响(在实际应用中,算法模型的训练者会很注重数据的隐私性,所以一般在前期训练过程中,数据不会被攻击者轻易修改。然而很多系统为了适应环境的变化,会不断迭代更新模型,这时就可能遭到攻击)
3)针对算法模型的攻击,通过在机器学习模型推理阶段中对输入数据做轻微修改,就能够让模型得出错误的结果。这些被轻微修改后的数据称为对抗样本。这种针对算法模型的攻击方法能够较为轻易地找到让模型作出错误判断的对抗样本。
二、对抗样本生成方法
只补充上篇综述没有提到的部分
1.L-BFGS
Szegedy等人使用有约束L-BFGS 算法来求解,将问题进行了如下转换:
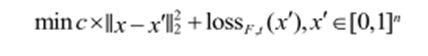
其中 loss 为一个与模型和标签有关的损失函数。由于神经网络一般是非凸的,上述损失函数最终得到一个近似值。对于每一个常量 c>0,重复优化求解这个最小化问题,每一个c 值 都能找到一个满足问题的可行解,通过执行全局的线性搜索,最终找到满足 L2距离最小的对抗样本。
2.FGSM
通常使用反向传播来高效率地计算待求梯度。该方法通过损失函数的梯度来决定像素的变化方向,最终所有的像素都会等比例地增大或减小。对于各种各样的模型,这种方法能有效地产生所需的对抗样本。
快速梯度符号法与 L-BFGS 方法有两个主要的区别:
a)快速梯度符号法基于 L∞距离求解;
b)每次求解不需要迭代,生成对抗样本速度快,但相似度并不是最高。
3 JSMA 雅可比显著图生成对抗样本
简单来说,想要使得样本被模型错误分类为目标标签 t,必须增加模型输出的目标标签 t 的概率,同时减少其他标签的概率,直到目标标签的概率大于其他标签。这可以通过使用显著性矩阵,有选择地改变图像的某些像素来实现。在求解出显著性矩阵后,通过算法选择显著性最大的像素,并对其进行修改,以增加分类为目标标签 t 的概率。重复这一过程,直到目标标签的概率大于其他标签,或达到了最大次数。

6.MalGAN
Hu等人提出了基于 MalGAN 的恶意软件对抗样本生成方法。恶意软件检测算法通常集成到防病毒软件中或托管在云端,因此对攻击者来说是一个黑盒模型,很难知道恶意软件检测使用的分类器以及分类器的参数。 Hu等人通过给黑盒模型输入各种特征的样本,利用原始样本和黑盒模型所产生的输出来训练一个辨别器SD,再用辨别器SD指导生成器来产生对抗样本

本文中说:实际上,MalGAN 算法强调整个样本集的正确率,而不关心单个样本的相似度,这意味着每个样本所需的扰动可能很大,产生的对抗样本的相似度可能很低。这就导致该算法在实际应用中具有较大局限性,具体到单个样本的修改,可能已经大到不能接受。
(这篇论文我也看过,但是没有想到这一点…)
三、对抗样本的防御方法(只记录针对上篇综述的补充)
1.蒸馏防御:
1.1蒸馏训练最初是用于将较复杂(教师)模型精简为较简单(学生)模型,具体来说,首先以常规方法用硬标签在训练集上训练出教师模型,然后,利用教师模型预测训练集得到对应的软标签(训练集的真实标签为硬标签,教师模型预测标签为软标签),接着用软标签代替硬标签在训练集上训练出学生模型。
1.2蒸馏防御使用蒸馏训练来提高神经网络的健壮性,但有两点区别。首先,教师模型和学生模型的结构完全相同,其次,蒸馏防御通过设置蒸馏温度迫使学生模型的预测结果变得更加可信。也就是说,蒸馏防御可以降低模型对输入扰动的敏感程度。
1.3蒸馏防御在正常训练模型的损失函数 softmax 中引入了温度常数 T:

训练过程中增加温度常数T会使得模型产生标签分布更加均匀的预测输出。当温度系数接近无穷大时,softmax(x)接近均匀分布。
在训练过程中引入蒸馏防御,总共分三步进行:
a)将 softmax 的温度常数设置为 T,以常规方法用硬标签在训练集上训练出教师模型;
b)利用教师模型预测训练集得到对应的软标签;
c)将 softmax 的温度常数设置为 T,用软标签代替硬标签在训练集上训练出学生模型(与教师模型的结构相同);
在测试过程中,对于测试集中的输入数据,使用学生模型的输出进行预测。然而这种防御方法只能抵御有限的对抗样本攻击。