Linux IP代理筛选系统(shell+proxy)
上一篇博客,介绍了Linux 抓取网页的实例,其中在抓取google play国外网页时,需要用到代理服务器
代理的用途
其实,除了抓取国外网页需要用到IP代理外,还有很多场景会用到代理:
- 通过代理访问一些国外网站,绕过被某国防火墙过滤掉的网站
- 使用教育网的代理服务器,可以访问到大学或科研院所的内部网站资源
- 利用设置代理,把请求通过代理服务器下载缓存后,再传回本地,提高访问速度
- 黑客发动攻击时,可以通过使用多重代理来隐藏本机的IP地址,避免被跟踪(当然,魔高一尺,道高一丈,终究会被traced)
代理的原理
代理服务的原理是本地浏览器(Browser)发送请求的数据,不是直接发送给网站服务器(Web Server)
而是通过中间的代理服务器(Proxy)来代替完成,如下图:
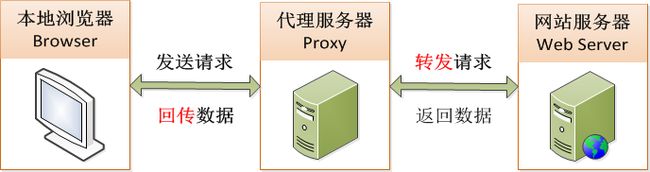
IP代理筛选系统
问题分析
- 因为不可能每天都遍历测试全球2^32数量级的IP地址,来看哪个IP可用,因此首要工作就是寻找待选的代理IP源?
- 初步确定了待选代理IP源,如何确定这里面的每一个IP是真的可用?
- 寻找到的待选代理IP源,是以什么格式保存的?需要进行文本预处理吗?
- 选择并确定了某个代理IP可用,但在下载网页过程中可能会又突然失效了,如何继续抓取剩下的网页?
- 如果重新选择了一个可用的代理IP完成了剩下的网页抓取,为了方便下次使用,需要将它更新到12国抓取脚本中,该如何实现呢?
- 上篇博客中提到过,在抓取游戏排名网页和游戏网页的过程中,都需要使用代理IP来下载网页,如果遇到上面的代理IP突然失效,该如何解决?
- 如果一个代理IP并没有失效,但是它抓取网页的速度很慢或极慢,24小时内无法完成对应国家的网页抓取任务,该怎么办?需要重新筛选一个更快的吗?
- 如果把所有代理IP源筛选一遍后,仍然没有一个可用的代理IP,该怎么办?是继续循环再筛选一次或多次,还是寻找新的代理IP源?
分析解决一个实际问题时,将会遇到各种问题,有些问题甚至是方案设计之初都难以想到的(如代理IP抓取网页速度过慢),我的体会是:动手实践比纯理论更重要!
方案设计
总体思路:寻找并缩小筛选的IP代理源——》检测代理IP是否可用——》IP可用则记录下来抓取网页——》代理IP故障则重新筛选——》继续抓取网页——》完成

1、IP代理源
选择有两个原则:可用和免费,经过深入调研和搜索,最后确定两个网站的IP代理比较靠谱:freeproxylists.net和xroxy.com
从国家数、IP代理数量、IP代理可用率、IP代理文本格式等多方面综合考量,IP代理源主要选自前者,后者作为补充,在后来的实践测试表明这种初选方案基本满足需求
2、文本预处理
从freeproxylists.net获取的代理IP,有IP地址、端口、类型、匿名性、国家...等等参数,而我们需要的仅仅是IP+Port,因此需要对初选的IP代理源做文本预处理
文本空格处理命令:
sed -e "s/\s\{2,\}/:/g" $file_input > $file_split
sed -i "s/ /:/g" $file_split
合并代理IP(ip:port)命令:
proxy_ip=$(echo $line | cut -f 1 -d ":")
proxy_port=$(echo $line | cut -f 2 -d ":")
proxy=$proxy_ip":"$proxy_port
3、检测IP代理
文本预处理代理IP为标准格式(ip:port)后,需要进行代理IP筛选测试,看哪些可用哪些不可用(由于获取的IP代理源有一些不能使用或下载过慢,需要过滤掉)
curl抓取网页检测IP代理是否可用命令:
cmd="curl -y 60 -Y 1 -m 300 -x $proxy -o $file_html$index $url_html"
$cmd
4、保存IP代理
检测一个代理IP是否可用,如果可用,则保存下来。
判断一个代理IP是否可用的标准,是通过判断步骤3中下载的网页($file_html$index)是否有内容,具体命令如下:
if [ -e ./$file_html$index ]; then
echo $proxy >> $2
break;
fi
5、IP代理抓取网页
利用步骤4保存的代理IP抓取网页,通过代理IP抓取12国排名网页和游戏网页,具体命令如下:
proxy_cmd="curl -y 60 -Y 1 -m 300 -x $proxy -o $proxy_html $proxy_http"
$proxy_cmd
6、IP代理故障
IP代理故障有多种情况,在上面的问题分析中已经列出了几条,下面将详细分析如下:
a、代理IP在抓取的网页过程中,突然失效,无法继续完成网页抓取
b、代理IP没有失效,但是抓取网页很慢,无法在一天24小时内完成网页抓取,导致无法生成游戏排名每日报表
c、代理IP全部失效,无论是轮询检测一遍或多遍后,都无法完成当天的网页抓取任务
d、由于整个网络路由拥塞,导致代理IP抓取网页很慢或无法抓取,误判为代理IP全部失效,如何恢复和纠正
7、重新检测IP代理
在网页抓取过程中,面对步骤6的IP代理故障,设计一套合理、高效的代理IP抓取恢复机制,是整个IP代理筛选系统的核心和关键
其故障恢复的轮询筛选流程如下:

上图流程中,需要注意几点:
a、首先检测上次IP代理,这是因为上次(昨天)的IP代理完成了所有网页抓取任务,其可用概率相对比较高,所以优先考虑其今天是否也可用。如果不可用,则另选其它
b、如果上次代理IP今天不可用,则重新遍历检测代理IP源,一旦检测到有可用,则不再循环下去,更新可用IP代理并保存其在IP源的位置,方便下次从此处开始遍历
c、如果流程b新选的代理IP突然失效或网速过慢,则在b记录的IP源位置继续筛选后面的代理IP是否可用。如可用,则继续抓取网页;如不可用,则再次遍历整个IP源
d、如果再次遍历了整个代理IP源,仍然没有代理IP可用,则反复轮询遍历整个代理IP源,直到有代理IP可用或今天24时过去(即今日整天都找不到可用代理IP)
e、对流程d中全部代理IP失效且整日找不到可用代理IP,无法完成当日网页抓取这一特殊情况,在次日凌晨重新启动网页抓取总控脚本前,需要先杀死流程d在后台的循环进程,防止今日和次日的两个后台网页抓取程序同时运行(相当于两个异步的后台抓取进程),造成抓取网页排名数据陈旧或错误、占用网速带宽等。其实现杀死当日僵死的后台抓取进程,请见上一篇博客Linux 抓取网页实例 ——》自动化总控脚本 ——》kill_curl.sh脚本,其原理是kill -9 进程号,关键脚本代码如下:
while [ ! -z $(ps -ef | grep curl | grep -v grep | cut -c 9-15) ]
do
ps -ef | grep curl | grep -v grep | cut -c 15-20 | xargs kill -9
ps -ef | grep curl | grep -v grep | cut -c 9-15 | xargs kill -9
done
8、完成网页抓取
通过上述的IP代理筛选系统,筛选出12国可用的免费代理IP,完成每日12国网页排名和游戏网页的抓取任务
之后,就是对网页中游戏属性信息的进行提取、处理,生成每日报表、邮件定时发送和趋势图查询等,详见我的上一篇博客:Linux 抓取网页实例
脚本功能实现
IP代理筛选的基本过程比较简单,其数据格式和实现步骤如下:
首先,到freeproxylists.net 网站,收集可用的代理IP源(以美国为例),其格式如下:

接着,清除上图中的空格,具体实现命令请见上面【方案设计】——》【2、文本预处理】,文本预处理后的格式如下:

然后,测试上图文本预处理后的代理IP是否可用具体命令请见上面【方案设计】——》【3、检测IP代理】,检测代理IP后的格式如下:

下面介绍shell脚本实现文本预处理和网页筛选的详细步骤
1、文本预处理
# file process
log='Top800proxy.log'
dtime=$(date +%Y-%m-%d__%H:%M:%S)
function select_proxy(){
if [ ! -d $dir_split ]; then
mkdir $dir_split
fi
if [ ! -d $dir_output ]; then
mkdir $dir_output
fi
if [ ! -e $log ]; then
touch $log
fi
echo "================== Top800proxy $dtime ==================" >> $log
for file in `ls $dir_input`; do
echo $file >> $log
file_input=$dir_input$file
echo $file_input >> $log
file_split=$dir_split$file"_split"
echo $file_split >> $log
rm -rf $file_split
touch $file_split
sed -e "s/\s\{2,\}/:/g" $file_input > $file_split
sed -i "s/ /:/g" $file_split
file_output=$dir_output$file"_out"
echo $file_output >> $log
proxy_output "$file_split" "$file_output"
echo '' >> $log
done
echo '' >> $log
}
if语句,判断并创建用于保存处理IP源中间结果的文件夹$dir_split 和$dir_output ,前者保存【脚本功能实现】中文本预处理后的文本格式,后者保存检测后可用的代理IP
sed -e语句,把输入文本(脚本功能实现的图1)中的多个空格,修改为一个字符“:”
sed -i语句,进一步把文本中的多余空格,转换为一个字符":"
转换的中间结果,都保存到文件夹$dir_split
后面的file_output三行,以文件参数的形式"$file_split",传给代理IP检测函数(proxy_output),筛选出可用的代理IP
2、代理IP筛选
index=1
file_html=$dir_output"html_"
cmd=''
function proxy_output(){
rm -rf $2
touch $2
rm -rf $file_html*
index=1
while read line
do
proxy_ip=$(echo $line | cut -f 1 -d ":")
proxy_port=$(echo $line | cut -f 2 -d ":")
proxy=$proxy_ip":"$proxy_port
echo $proxy >> $log
cmd="curl -y 60 -Y 1 -m 300 -x $proxy -o $file_html$index $url_html"
echo $cmd >> $log
$cmd
if [ -e ./$file_html$index ]; then
echo $proxy >> $2
break;
fi
index=`expr $index + 1`
done < $1
rm -rf $file_html*
}
代理IP筛选函数proxy_output头三行,清除先前筛选的结果,作用是初始化
while循环,主要是遍历以参数形式传入的文本预处理后的"$file_split",检测代理IP是否可用,其步骤如下:
a、首先拼接出代理IP的(ip:port)格式,其实现是通过cut分割文本行,然后提取出第一个字段(ip)和第二个字段(port),拼接成(ip:port)
b、通过curl构造出抓取网页的命令cmd,执行网页下载命令$cmd
c、通过检测网页下载命令执行后,是否生成了网页下载文件,来判断拼接出的代理IP($proxy)是否有效。若有效,则保存此代理IP到"$file_output"中并退出遍历(break)
d、如果当前代理IP无效,则读取下一行代理IP,继续检测
代理IP抓取网页实例:
利用上面的代理IP系统,筛选出来免费代理IP,抓取游戏排名网页的实例如下(脚本片段):
index=0
while [ $index -le $TOP_NUM ]
do
url=$url_start$index$url_end
url_cmd='curl -y 60 -Y 1 -m 300 -x '$proxy' -o '$url_output$index' '$url
echo $url_cmd
date=$(date "+%Y-%m-%d___%H-%M-%S")
echo $index >> $log
echo $url"___________________$date" >> $log
$url_cmd
# done timeout file
seconds=0
while [ ! -f $url_output$index ]
do
sleep 1
echo $url_output$index"________________no exist" >> $log
$url_cmd
seconds=`expr $seconds + 1`
echo "seconds____________"$seconds >> $log
if [ $seconds -ge 5 ]; then
select_proxy
url_cmd='curl -y 60 -Y 1 -m 300 -x '$proxy' -o '$url_output$index' '$url
seconds=0
fi
done
index=`expr $index + 24`
done上面shell脚本代码片段,是用来抓取网页的,其中最核心的一行是select_proxy
其作用是上述介绍过的,当代理IP突然失效、抓取网页过慢、全部代理IP都无效、或无法完成当天的网页抓取工作,用来重新筛选代理IP,恢复网页抓取的一段核心代码
其设计实现流程,如上述的【方案设计】——》【7、重新检测IP代理】,其实现原理可参照上述的【代理IP筛选】的脚本,在此不再贴出其源脚本代码