NLP任务之文本对分类
任务
上一篇是句子的情感分类任务(文本分类),这一篇是基于pytorch的文本对分类任务。

链接
提取码:t2ta
流程
第一步:基于中文wikipedia训练中文词向量
预料地址:链接
提取码:ihu4
- 使用gensim库的WikiCorpus,将xml文件转到txt文件
from gensim.corpora import WikiCorpus
input_path = 'zhwiki-latest-pages-articles.xml.bz2'
output_path = 'zhwiki.txt'
print('Chinese Wiki data reading...')
input_file = WikiCorpus(input_path, lemmatize=False, dictionary={
})
print('Chinese Wiki data reading finishes.')
with open(output_path, 'w', encoding='utf-8') as output_file:
print('Transformation begins...')
count = 0
for text in input_file.get_texts():
output_file.write(' '.join(text) + '\n')
count += 1
if count % 10000 == 0:
print(f"#{count} of texts have been processed.")
print('Transformation finished.')
- 用zhconv库将繁体数据转换为简体数据
import zhconv
print('Traditional Chinese to Simplified Chinese.')
input_path = 'zhwiki.txt'
output_path = 'zhwiki.simplify.txt'
with open(input_path, 'r', encoding='utf-8') as input_file:
print('Traditional Chinese file reading...')
lines = input_file.readlines()
print('Traditional Chinese file reading finishes...')
print('Tradition to simplified begins...')
count = 0
with open(output_path, 'w', encoding='utf-8') as output_file:
for line in lines:
output_file.write(zhconv.convert(line, 'zh-hans'))
count += 1
if count % 10000 == 0:
print(f"#{count} of texts have been transformed.")
print('Tradition to simplified finished.')
- 结巴分词
import jieba
input_path = 'zhwiki.simplify.txt'
output_path = 'zhwiki.simplify.tok.txt'
with open(input_path, 'r', encoding='utf-8') as input_file:
print('Simplified Chinese wiki data reading...')
lines = input_file.readlines()
print('Simplified Chinese wiki data reading finishes.')
print('Tokenization begins.')
with open(output_path, 'w', encoding='utf-8') as output_file:
count = 0
for line in lines:
output_file.write(' '.join(jieba.cut(line.split('\n')[0].replace(' ', ''))) + '\n')
count += 1
if count % 10000 == 0:
print(f"#{count} of texts have been tokenized.")
print('Tokenization finished.')
- 去除非中文词
import re
input_path = 'zhwiki.simplify.tok.txt'
output_path = 'zhwiki.data.txt'
with open(input_path, 'r', encoding='utf-8') as input_file:
print('Simplified Chinese wiki data reading...')
lines = input_file.readlines()
print('Simplified Chinese wiki data reading finishes.')
print('Remove Non-zh begins...')
with open(output_path, 'w', encoding='utf-8') as output_file:
count = 0
remove = r'^[\u4e00-\u9fa5]+$'
for line in lines:
line_list = line.split('\n')[0].split(' ')
new_line = []
for word in line_list:
if re.search(remove, word):
new_line.append(word)
output_file.write(' '.join(new_line) + '\n')
count += 1
if count % 10000 == 0:
print(f"#{count} of texts have been processed.")
print('Remove Non-zh finishes.')
- 词向量训练
import multiprocessing
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
input_path = 'zhwiki.data.txt'
output_path = 'zhwiki.model'
print('Word2Vec Generation begin...')
model = Word2Vec(LineSentence(input_path),
size=200,
window=5,
min_count=5,
workers=multiprocessing.cpu_count())
print('Word2Vec Generation finishes.')
print('Model Saving...')
model.save(output_path)
print('Model Saved.')
最终产生的可用作预训练词向量模型:
![]()
第二步:读数据&数据可视化
- 读数据删除空的样本
def get_data(filename):
filepath = fn_dict[filename]
file1path = filepath + r"\arg0file_seg.txt"
file2path = filepath + r"\arg1file_seg.txt"
labelpath = filepath + r"\relationfile.txt"
with open(file1path,"r",encoding="utf-8", errors="ignore") as f:
f1 = f.read()
f1 = f1.strip().split("\n")
with open(file2path,"r",encoding="utf-8", errors="ignore") as f:
f2 = f.read()
f2 = f2.strip().split("\n")
with open(labelpath,"r",encoding="utf-8", errors="ignore") as f:
l = f.read()
l = l.strip().split("\n")
# 删除空的样例
lenth = len(f1)
for i in range(lenth-1,-1,-1):
if f1[i].strip()=="" or f2[i].strip()=="":
del f1[i]
del f2[i]
del l[i]
return [f1,f2,l]
train,valid,test = get_data("train"),get_data("valid"),get_data("test")
- 数据可视化,其中的word_num_lst是train数据的所有句子的长度统计列表
def word_nums(word_num_lst):
len_dict = dict(Counter(word_num_lst).most_common())
print("least number of words:",min(word_num_lst))
print("most number of words:",max(word_num_lst))
print(word_num_lst.count(0))
y = [0 for i in range(8)]
x = [(i+1) for i in range(8)]
# <10
for key in len_dict:
if key < 100:
y[0] += len_dict[key]
elif 100 <= key < 200:
y[1] += len_dict[key]
elif 200 <= key < 300:
y[2] += len_dict[key]
elif 300 <= key < 400:
y[3] += len_dict[key]
elif 400 <= key < 500:
y[4] += len_dict[key]
elif 500 <= key < 600:
y[5] += len_dict[key]
elif 600 <= key < 700:
y[6] += len_dict[key]
elif key >= 700:
y[7] += len_dict[key]
lenth = len(y)
for idx in range(lenth):
y[idx] /= sum(len_dict.values())
plt.bar(x, y, facecolor="blue", edgecolor="white")
for x1, y1 in zip(x, y):
plt.text(x1, y1, '%.3f' % y1, ha="center", va="bottom", fontsize=7)
# new_xticks = [r"<10", r"10-20", r"20-30", r"30-40", r"40-50", r"50-60", r">=60"]
new_xticks = [r"<100", r"100-200", r"200-300", r"300-400", r"400-500",r"500-600",r"600-700",r">=700"]
plt.xticks(x, new_xticks)
plt.xlabel("单词数")
plt.ylabel("占比")
plt.title("单词数分布图")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.show()

发现基本上都在100个词以内
第三步:预处理
1.使用第一步中训练出来的词向量模型,建立词表,其中的wordvec_path,就是上面的预训练模型地址。
def get_vocab_lst(*args):
print("loading wordvec_model...")
wordvec_model = gensim.models.KeyedVectors.load_word2vec_format(wordvec_path, binary=False)
print("done")
df = {
}
word_num_lst = []
train,valid,test = args
tr1,tr2,trr = train
va1,va2,var = valid
te1,te2,ter = test
sentences = tr1 + tr2 + va1 + va2 + te1 + te2
for sentence in sentences:
sentence = sentence.split()
word_num_lst.append(len(sentence))
for word in sentence:
if word not in df:
df[word] = 0
df[word] += 1
df = sorted([(df[w], w) for w in df], reverse=True)
word2idx = {
}
pretrained_weight_matrix = []
idx2word = []
for score, w in df:
if w in wordvec_model.wv.vocab:
word2idx[w] = len(word2idx)
idx2word.append(w)
pretrained_weight_matrix.append(wordvec_model[w])
word2idx["" ] = len(word2idx)
idx2word.append("" )
word2idx["" ] = len(word2idx)
idx2word.append("" )
pretrained_weight_matrix = torch.tensor(pretrained_weight_matrix)
pad_vec = torch.nn.init.uniform_(torch.empty(1, len(pretrained_weight_matrix[0])))
unk_vec = torch.nn.init.uniform_(torch.empty(1, len(pretrained_weight_matrix[0])))
pretrained_weight_matrix = torch.cat((pretrained_weight_matrix,pad_vec, unk_vec), dim=0)
print("total word:{:d}".format(len(word2idx)))
word_nums(word_num_lst)
return word2idx, idx2word, pretrained_weight_matrix,word_num_lst
word2idx, idx2word, pretrained_weight_matrix ,word_num_lst = get_vocab_lst(train,valid,test) # 200
- 预处理数据(规格化)
def format_data(data,word2idx,relation_dict,max_len):
f1,f2,relation = data
lenth = len(f1)
X = []
Y = []
for idx in range(lenth):
x1 = []
x2 = []
relationidx = relation_dict[relation[idx]]
f1_sent = f1[idx].split()
for word in f1_sent:
if word in word2idx:
x1.append(word2idx[word])
else:
x1.append(word2idx["" ])
f2_sent = f2[idx].split()
for word in f2_sent:
if word in word2idx:
x2.append(word2idx[word])
else:
x2.append(word2idx["" ])
# padding
x1 = padding(x1,max_len)
x2 = padding(x2,max_len)
X.append([x1,x2])
Y.append(relationidx)
return X,Y
def padding(idxlst,max_len):
for i in range(max_len - len(idxlst)):
idxlst.append(0)
return idxlst[:max_len]
idx2relation = enumerate(set(train[2])) # train[0]是第一句话的集合、train[2]是关系的集合
relation2idx = dict([value,key] for key,value in idx2relation)
idx2relation = dict(enumerate(set(train[2])))
train_x,train_y = format_data(train,word2idx,relation2idx,max_len)
valid_x,valid_y = format_data(valid,word2idx,relation2idx,max_len)
valid_x = valid_x[200:]
valid_y = valid_y[200:]
test_x,test_y = format_data(test,word2idx,relation2idx,max_len)
- 用torchtext与torch库,将数据封装成dataloader
from torchtext.data import Dataset
class DS(Dataset):
def __init__(self, x, y):
self.x = torch.tensor(x)
self.y = torch.tensor(y)
def __len__(self):
return len(self.x)
def __getitem__(self,idx):
return self.x[idx], self.y[idx]
from torch.utils.data import DataLoader as DL
train_dl = DL(DS(train_x,train_y),shuffle=True,batch_size=bs)
valid_x,test_x = map(torch.tensor,(valid_x,test_x))
valid_y,test_y = map(torch.LongTensor,(valid_y,test_y))
第四步:定义模型&loss&optim
使用的模型是ESIM
论文地址:Enhanced LSTM for Natural Language Inference
模型框架图(只需要看左半边):
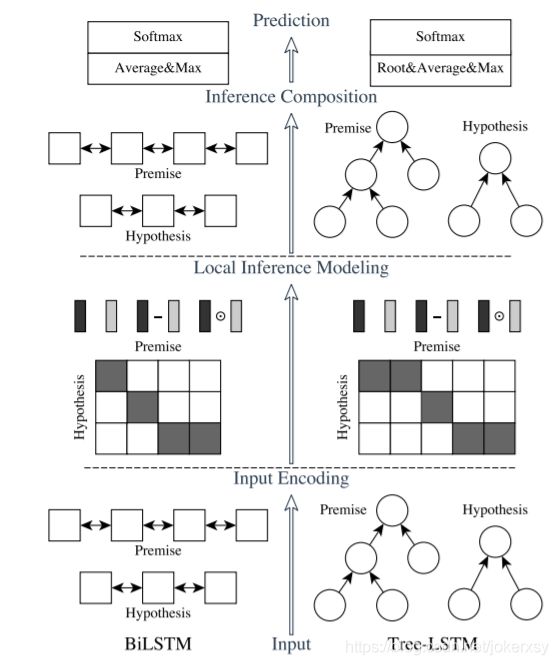
代码:
- attention
import torch
import torch.nn as nn
# utils
def masked_softmax(similarity_matrix, mask):
"""
输入:
similarity_matrix: [batch_size, seq_a, seq_b]
mask: [batch_size, seq_b]
输出:
被mask掩盖后经过softmax运算的similarity matrix
"""
batch_size, seq_len_a, seq_len_b = similarity_matrix.shape
reshape_sim = similarity_matrix.view(-1, seq_len_b) # [batch_size * seq_a, seq_b]
mask = mask.unsqueeze(1) # [batch_size, 1, seq_b]
mask = mask.expand_as(similarity_matrix).contiguous().float() # [batch_size, seq_a, seq_b]
reshape_mask = mask.view(-1, seq_len_b) # [batch_size * seq_a, seq_b]
reshape_sim.masked_fill_(reshape_mask == 0, -1e7)
result = torch.softmax(reshape_sim, dim=-1)
result = result * reshape_mask # [batch_size * seq_a, seq_b]
return result.view(batch_size, seq_len_a, seq_len_b)
def weighted_sum(tensor, weights, mask):
"""
输入:
tensor: [batch_size, seq_b, vec_dim]
weights: [batch_size, seq_a, seq_b]
mask: [batch_size, seq_a]
"""
weighted_sum = torch.matmul(weights, tensor) # [batch_size, seq_a, vec_dim]
mask = mask.unsqueeze(2) # [batch_size, seq_a, 1]
mask = mask.expand_as(weighted_sum).contiguous().float() # [batch_size, seq_a, vec_dim]
return weighted_sum * mask
class SoftmaxAttention(nn.Module):
def forward(self, sent_a, sent_a_mask, sent_b, sent_b_mask):
"""
输入:
sent_a: [batch_size, seq_a_len, vec_dim]
sent_a_mask: [batch_size, seq_a_len]
sent_b: [batch_size, seq_b_len, vec_dim]
sent_b_mask: [batch_size, seq_b_len]
输出:
sent_a_att: [batch_size, seq_a_len, seq_b_len]
sent_b_att: [batch_size, seq_b_len, seq_a_len]
"""
# similarity matrix
similarity_matrix = torch.matmul(sent_a, sent_b.transpose(1, 2).contiguous()) # [batch_size, seq_a, seq_b]
sent_a_b_attn = masked_softmax(similarity_matrix, sent_b_mask) # [batch_size, seq_a, seq_b]
sent_b_a_attn = masked_softmax(similarity_matrix.transpose(1, 2).contiguous(), sent_a_mask) # [batch_size, seq_b, seq_a]
sent_a_att = weighted_sum(sent_b, sent_a_b_attn, sent_a_mask) # [batch_size, seq_a, vec_dim]
sent_b_att = weighted_sum(sent_a, sent_b_a_attn, sent_b_mask) # [batch_size, seq_b, vec_dim]
return sent_a_att, sent_b_att
- encoder
def sort_by_seq_lens(batch, sequences_lengths, descending=True):
sorted_seq_lens, sorting_index = sequences_lengths.sort(0, descending=descending)
sorted_batch = batch.index_select(0, sorting_index)
idx_range = torch.arange(0, len(sequences_lengths)).type_as(sequences_lengths)
_, reverse_mapping = sorting_index.sort(0, descending=False)
restoration_index = idx_range.index_select(0, reverse_mapping)
return sorted_batch, sorted_seq_lens, sorting_index, restoration_index
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size, dropout_rate):
super(Encoder, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.encoder = nn.GRU(input_size=input_size, hidden_size=hidden_size,
num_layers=2, dropout=dropout_rate, bidirectional=True,
batch_first=True)
def forward(self, sequence_batch, sequence_lengths):
sorted_batch, sorted_seq_lens, _, restoration_index = sort_by_seq_lens(sequence_batch, sequence_lengths)
packed_batch = nn.utils.rnn.pack_padded_sequence(sorted_batch, sorted_seq_lens,
batch_first=True)
output, _ = self.encoder(packed_batch)
output, _ = nn.utils.rnn.pad_packed_sequence(output, total_length = max_len,batch_first=True)
return output.index_select(0, restoration_index)
- ESIM
import torch.nn.functional as F
def replace_masked(tensor, mask, value):
"""
用value替换tensor中被mask的位置
输入:
tensor: [batch_size, seq_len, vec_dim]
mask: [batch_size, seq_len]
value: float
"""
mask = mask.unsqueeze(2) # [batch_size, seq_len, 1]
reverse_mask = 1.0 - mask
values_to_add = value * reverse_mask
return tensor * mask + values_to_add
class ESIM(nn.Module):
def __init__(self, embed_size, hidden_size, dropout_rate, out_dim, pretrained_weight,padding_idx,fix_embedding = False):
super(ESIM, self).__init__()
self.embed = nn.Embedding.from_pretrained(pretrained_weight,
freeze=fix_embedding,
padding_idx=padding_idx)
self.input_encode = Encoder(input_size=embed_size,
hidden_size=hidden_size,
dropout_rate=dropout_rate)
self.proj = nn.Sequential(nn.Linear(8 * hidden_size, hidden_size), nn.ReLU())
self.attention = SoftmaxAttention()
self.inference_comp = Encoder(input_size=2 * hidden_size,
hidden_size=hidden_size,
dropout_rate=dropout_rate)
self.classify = nn.Sequential(nn.Linear(8 * hidden_size, hidden_size),
nn.ReLU(),
nn.Dropout(p=dropout_rate),
nn.Linear(hidden_size,out_dim),
# nn.Softmax()
nn.LogSoftmax()
# nn.Linear(hidden_size, hidden_size // 2),
# nn.ReLU(),
# nn.Dropout(p=dropout_rate),
# nn.Linear(hidden_size // 2, out_dim))
)
self.padding_idx = padding_idx
def forward(self, sent_a, sent_b):
"""
sent_a: [batch_size, max_len_a]
sent_b: [batch_size, max_len_b]
"""
batch_size, max_len_a = sent_a.shape
sent_a_mask = (sent_a != self.padding_idx).float()
len_a = torch.sum(sent_a != self.padding_idx, dim=-1)
_, max_len_b = sent_b.shape
sent_b_mask = (sent_b != self.padding_idx).float()
len_b = torch.sum(sent_b != self.padding_idx, dim=-1)
# Embedding
embed_a = self.embed(sent_a).float() # [batch_size, max_len_a, embed_size]
embed_b = self.embed(sent_b).float() # [batch_size, max_len_b, embed_size]
# Input encoding
output_a = self.input_encode(embed_a, len_a) # [batch_size, max_len_a, 2 * hidden_size]
output_b = self.input_encode(embed_b, len_b) # [batch_size, max_len_b, 2 * hidden_size]
# Local inference modeling
infer_a, infer_b = self.attention(output_a, sent_a_mask, output_b, sent_b_mask)
ma = torch.cat([output_a, infer_a, output_a - infer_a, output_a * infer_a], dim=-1) # [batch_size, max_len_a, 8 * hidden_size]
ma = self.proj(ma) # [batch_size, max_len_a, hidden_size]
mb = torch.cat([output_b, infer_b, output_b - infer_b, output_b * infer_b], dim=-1) # [batch_size, max_len_b, 8 * hidden_size]
mb = self.proj(mb) # [batch_size, max_len_b, hidden_size]
# Inference Composition
va = self.inference_comp(output_a, len_a) # [batch_size, max_len_a, 2 * hidden_size]
vb = self.inference_comp(output_b, len_b) # [batch_size, max_len_b, 2 * hidden_size]
vaave = torch.sum(va * sent_a_mask.unsqueeze(2), dim=1) / torch.sum(sent_a_mask, dim=1, keepdim=True) # [batch_size, 2 * hidden_size]
vamax = replace_masked(va, sent_a_mask, -1e7).max(dim=1)[0] # [batch_size, 2 * hidden_size]
vbave = torch.sum(vb * sent_b_mask.unsqueeze(2), dim=1) / torch.sum(sent_b_mask, dim=1, keepdim=True) # [batch_size, 2 * hidden_size]
vbmax = replace_masked(vb, sent_b_mask, -1e7).max(dim=1)[0] # [batch_size, 2 * hidden_size]
v = torch.cat([vaave, vamax, vbave, vbmax], dim=-1) # [batch_size, 8 * hidden_size]
# FNN
return self.classify(v)
model = ESIM(
embed_size = embed_size, # 300
hidden_size = hidden_size, # 64
dropout_rate = dropout_rate, # 0.5
out_dim = out_dim, # 15
pretrained_weight = pretrained_weight_matrix,
padding_idx = padding_idx, # 0
fix_embedding = True
)
loss_fn = nn.NLLLoss()
optim = torch.optim.Adam(params = model.parameters(),lr = lr,weight_decay=w_decay)
第五步:训练
(loss_fn 和 optim)
import time
def Train(model,train_dl,valid_x,valid_y,epochs,loss_fn,optim,monitor):
total = sum(para.numel() for para in model.parameters())
trainable = sum(para.numel() for para in model.parameters() if para.requires_grad)
print("total parameters:{} , trainable:{}".format(total,trainable))
best_acc = 0
best_loss = 0
t_batch = len(train_dl)
train_loss = []
train_acc = []
valid_loss = []
valid_acc = []
# last_loss = 0 # 记录上一轮验证集的loss,用于学习率的动态调整
total_time = 0.0
for epoch in range(epochs):
all_loss = 0
all_acc = 0
model.train()
b = -1
t1 = time.time()
for xb,yb in train_dl:
b += 1
sent_a = xb[:,0,:]
sent_b = xb[:,1,:]
out= model(sent_a,sent_b)
loss = loss_fn(out,yb)
optim.zero_grad()
loss.backward()
optim.step()
acc = evaluation(out,yb) / len(yb)
all_loss += loss.item()
all_acc += acc
if b % 1 == 0:
print('[ Epoch{}/{} Batch{}/{} ] Loss:{:.3f} acc:{:.3f} '.format(epoch + 1,epochs, b+1,t_batch,loss.item(),acc*100), end='\n')
print('Train | Loss:{:.5f} Acc: {:.3f}'.format(all_loss / t_batch, all_acc / t_batch * 100))
train_loss.append(all_loss/t_batch)
train_acc.append(all_acc/t_batch*100)
t2 = time.time()
t = t2 - t1
total_time += t
model.eval()
model.dropout = 0.0
sent_a = valid_x[:,0,:]
sent_b = valid_x[:,1,:]
out= model(sent_a,sent_b)
loss = loss_fn(out,valid_y).item()
acc = evaluation(out,valid_y) / len(valid_y)
if monitor == "loss" and loss <= best_loss: best_loss = loss,save_model(monitor,loss,model)
if monitor == "acc" and acc >= best_acc:
best_acc = acc
save_model(monitor,acc,model)
print("\n")
valid_loss.append(loss)
valid_acc.append(acc * 100)
return train_loss,train_acc,valid_loss,valid_acc,total_time
train_loss,train_acc,valid_loss,valid_acc,total_time = Train(model = model,
train_dl = train_dl,
valid_x = valid_x,
valid_y = valid_y,
epochs = epoch,
loss_fn = loss_fn,
optim = optim,
monitor = "acc",
) # or loss
结果:
total parameters:5880471 , trainable:430671
[ Epoch1/10 Batch1/19 ] Loss:1.874 acc:32.422
[ Epoch1/10 Batch2/19 ] Loss:1.937 acc:27.344
[ Epoch1/10 Batch3/19 ] Loss:1.906 acc:28.906
[ Epoch1/10 Batch4/19 ] Loss:1.875 acc:31.641
[ Epoch1/10 Batch5/19 ] Loss:1.813 acc:30.859
[ Epoch1/10 Batch6/19 ] Loss:1.916 acc:31.641
[ Epoch1/10 Batch7/19 ] Loss:1.809 acc:31.250
[ Epoch1/10 Batch8/19 ] Loss:1.757 acc:32.812
参考
语义匹配模型
http://www.cnblogs.com/guoyaohua/p/9229190.html
https://blog.csdn.net/pengmingpengming/article/details/88534968?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
https://www.6aiq.com/article/1589798723495 (***)
https://www.6aiq.com/article/1589474365961 (***)
语义匹配的应用
https://blog.csdn.net/abc50319/article/details/106048021
https://blog.csdn.net/m0_37586850/article/details/103982504
https://blog.csdn.net/m0_37586850/article/details/105154321