分布式服务防雪崩熔断器,Hystrix理论+实战。
Hystrix是什么?
hystrix对应的中文名字是“豪猪”,豪猪周身长满了刺,能保护自己不受天敌的伤害,代表了一种防御机制,这与hystrix本身的功能不谋而合,因此Netflix团队将该框架命名为Hystrix,并使用了对应的卡通形象做作为logo。
在一个分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,如何能够保证在一个依赖出问题的情况下,不会导致整体服务失败,这个就是Hystrix需要做的事情。Hystrix提供了熔断、隔离、Fallback、cache、监控等功能,能够在一个、或多个依赖同时出现问题时保证系统依然可用。
为什么需要Hystrix?
在大中型分布式系统中,通常系统很多依赖(HTTP,hession,Netty,Dubbo等),如下图:
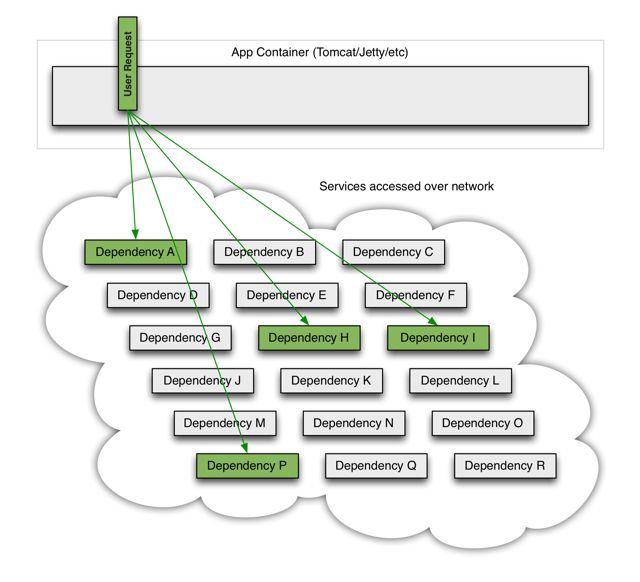
在高并发访问下,这些依赖的稳定性与否对系统的影响非常大,但是依赖有很多不可控问题:如网络连接缓慢,资源繁忙,暂时不可用,服务脱机等。
如下图:QPS为50的依赖 I 出现不可用,但是其他依赖仍然可用。
当依赖I 阻塞时,大多数服务器的线程池就出现阻塞(BLOCK),影响整个线上服务的稳定性.如下图:
在复杂的分布式架构的应用程序有很多的依赖,都会不可避免地在某些时候失败。高并发的依赖失败时如果没有隔离措施,当前应用服务就有被拖垮的风险。
例如:一个依赖30个SOA服务的系统,每个服务99.99%可用。
99.99%的30次方 ≈ 99.7%
0.3% 意味着一亿次请求 会有 3,000,00次失败
换算成时间大约每月有2个小时服务不稳定.
随着服务依赖数量的变多,服务不稳定的概率会成指数性提高.
解决问题方案:对依赖做隔离,Hystrix就是处理依赖隔离的框架,同时也是可以帮我们做依赖服务的治理和监控。
Netflix 公司开发并成功使用Hystrix,使用规模如下:
The Netflix API processes 10+ billion HystrixCommand executions per day using thread isolation.
Each API instance has 40+ thread-pools with 5-20 threads in each (most are set to 10).
Hystrix如何解决依赖隔离?
Hystrix使用命令模式HystrixCommand(Command)包装依赖调用逻辑,每个命令在单独线程中/信号授权下执行。
可配置依赖调用超时时间,超时时间一般设为比99.5%平均时间略高即可.当调用超时时,直接返回或执行fallback逻辑。
为每个依赖提供一个小的线程池(或信号),如果线程池已满调用将被立即拒绝,默认不采用排队.加速失败判定时间。
依赖调用结果分:成功,失败(抛出异常),超时,线程拒绝,短路。 请求失败(异常,拒绝,超时,短路)时执行fallback(降级)逻辑。
提供熔断器组件,可以自动运行或手动调用,停止当前依赖一段时间(10秒),熔断器默认错误率阈值为50%,超过将自动运行。
提供近实时依赖的统计和监控。
Hystrix依赖的隔离架构,如下图:
Hystrix应用实战
Maven:
com.netflix.hystrix
hystrix-core
1.5.13
源码太多,不一一贴上来,这里只展示主要的测试源码。
public static void main(String[] args) {
System.out.println(test("javastack"));
}
private static String test(String name) {
HystrixUtil.HystrixReqConfig hc = HystrixUtil.HystrixReqConfig.withGroupKey("TestGroup").withTimeout(3)
.withUnit(TimeUnit.SECONDS).withPassNum(64);
String result = HystrixUtil.getExcuteResult(new HystrixCallableService() {
@Override
public String execute() {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "success " + name;
}
@Override
public String fallback() {
return "fallback " + name;
}
}, hc);
return result;
}
这里设置了3秒超时进入熔断。
测试程序中休眠5秒,进入熔断器并输出:
fallback javastack
测试程序中休眠2秒,进入正常流程并输出:
success javastack
熔断器测试成功,即使某个服务出问题,也不会影响整个系统的正常运行。
获取全部打包源码可以在下方公众号菜单中回复"微信群"加入微信群,并在对应的群文件中下载。
这是某微信群友个人付费购买的高级教程<<Vue+Node+MongoDB高级全栈开发>>,现在分享出来,获取下方公众号回复:视频
申明:本视频内容与本公众号无任何关系,仅供学习交流使用。
号外:只要从简书过来关注下方微信公众号的,在公众号中回复MM,可以免费送干货:2TB架构师四阶段视频教程里面的资料。
推荐阅读
去BAT面试完的Mysql面试题总结(55道,带完整答案)
阿里高级Java面试题(首发,70道,带详细答案)
2017派卧底去阿里、京东、美团、滴滴带回来的面试题及答案
Spring面试题(70道,史上最全)
通往大神之路,百度Java面试题前200页。
分享Java干货,高并发编程,热门技术教程,微服务及分布式技术,架构设计,区块链技术,人工智能,大数据,Java面试题,以及前沿热门资讯等。