PBFT算法研究
PBFT算法研究
真分布式与伪分布式
目前的数据库号称分布式存储,这种分布式存储与区块链有着本质上的区别,这种分布式数据库服务器集群的分布式是为了实现服务的恢复与备份,数据的冗余,然而他们仍然属于某一个企业或机构,所以还是中心化管理的数据库集群。
区块链中的各个节点相当于分布式系统中的数据库,不一样的点在于,没有一个管理员去维持各个数据库之间的数据同步,同时并没有增删改查中的删改查功能。所以是不可篡改。(不是指不可更改,而是指不能无记录的更改)。
拜占庭将军问题(节点作恶)
古罗马首都拜占庭帝国地域辽阔,每个军队的将军达成共识才能决定在战争中的行动,但将军中可能存在叛徒,这些叛徒会干扰忠诚将军的行动从而打乱作战计划。
可以描述为:在已知分布式系统中出现拜占庭节点(主动作恶、硬件错误、网络拥塞的节点等)的情况下,系统各节点间如何达成有效地一致性问题。
先决条件
1、节点之间消息传递不可篡改,也就是说必须用密码学保证消息是传递安全的,消息传递可被篡改的安全问题是不可被解决的。
2、基于状态机副本复制问题解决,所以假设有F个Faulty,总结点为N个,那么该问题在N≥3F+1的情况下有解。
状态机副本复制:最小的复制组是三个节点。一个错误,我们可以通过和另外两个进行对比获悉。而两个副本是不够的,因为没办法确定谁才是错误的那一个。
反过来说,三复制组可以支持最多一个错误节点发生。如果超过一个副本错误,三个节点状态和输出都可能不一样,因此也无法确认哪个是正确的。
一般来说,一个系统支持 F 个容错,那么必须使用 2F+1 个副本。多余的副本是用来确定哪一半是正确的,哪一半是错误的。 特殊的情况下可以提高一些。
那么为什么明明只需要2F+1个就可以判断了,拜占庭容错却需要N≥3F+1呢?
假设总数N个节点, F个故障节点,那么必须接收到N-F个消息应答(没有故障的节点的全部应答),就能够判断出结果(因为故障节点可能不发送应答)。N-f个应答中有f个可能是假的(故障节点发出的)【这句话最为奇妙,但是确实一个假设,因为可能有网络延迟等等,我们可以认为,作假的节点和真正故障的节点的数目是相等的,我们需要把有问题的节点的容忍度最大化 (系统需要稳定,肯定需要对有问题的节点做最大容忍),即就是 故障节点数目 == 作假节点数目,无论真实数目那边大,我们f 就是取了最大的那边的数值】,所以真实的是N-f-f,且 少数服从多数,所以还需要+1。
3、每个节点签名无法被篡改
BFT
传统的BFT有两种解决方案,口头协议算法与书面协议算法,由于是指数级别的运算,用的并不多,所以这里不再赘述,让拜占庭容错算法焕发生机的是实用拜占庭容错(PBFT),他让算法从指数级降到了多项式级,以致于在分布式网络中可以得到应用。
PBFT
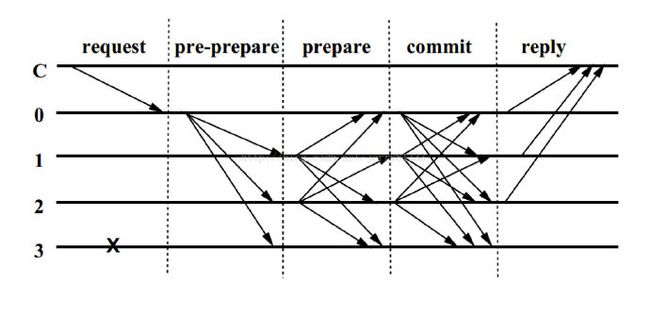
从全网选出主节点,主节点p=v mod R,R为节点个数,v为视图编号。
其中C是客户端,0是主节点,也可以叫做排序节点,1,2,3称为副本节点,从图中可以看出,无论如何给3节点发消息,3节点的表现是没有任何回应的,所以我们可以把它看做故障节点。
该流程的主要阶段是第2,3,4阶段。
先从第一阶段说起,
1、REQUEST
客户端c向主节点p发送
2、PRE-PREPARE:
主节点收到客户端的请求,需要进行以下校验(排序):
(1)客户端请求消息签名是否正确。
非法请求丢弃。正确请求,分配一个编号n,编号n主要用于对客户端的请求进行排序。然后广播一条<
3、PREPARE:
副本节点i收到主节点的PRE-PREPARE消息,需要进行以下交验:
a. 主节点PRE-PREPARE消息签名是否正确。
b. 当前副本节点是否已经收到了一条在同一v下并且编号也是n,但是签名不同的PRE-PREPARE信息。
c. d与m的摘要是否一致。
d. n是否在区间[h, H]内。
非法请求丢弃。正确请求,副本节点i向其他节点包括主节点发送一条
4、COMMIT:
主节点和副本节点收到PREPARE消息,需要进行以下交验:
a. 副本节点PREPARE消息签名是否正确。
b. 当前副本节点是否已经收到了同一视图v下的n。
c. n是否在区间[h, H]内。
d. d是否和当前已收到PRE-PPREPARE中的d相同
非法请求丢弃。如果副本节点i收到了2f+1个验证通过的PREPARE消息,则向其他节点包括主节点发送一条
5、REPLY:
主节点和副本节点收到COMMIT消息,需要进行以下交验:
a. 副本节点COMMIT消息签名是否正确。
b. 当前副本节点是否已经收到了同一视图v下的n。
c. d与m的摘要是否一致。
d. n是否在区间[h, H]内。
非法请求丢弃。如果副本节点i收到了2f+1个验证通过的COMMIT消息,说明当前网络中的大部分节点已经达成共识,运行客户端的请求操作o,并返回
PBFT中节点作恶问题
可以看到副本节点作恶的情况下,会直接丢弃非法请求,那么身为排序节点的主节点作恶则成为了重点。
如果主节点作恶,它可能会给不同的请求编上相同的序号,或者不去分配序号,或者让相邻的序号不连续。备份节点应当有职责来主动检查这些序号的合法性。如果主节点掉线或者作恶不广播客户端的请求,客户端设置超时机制,超时的话,向所有副本节点广播请求消息。副本节点检测出主节点作恶或者下线,发起View Change。

从节点认为主节点有问题时,会向其它节点发送 view-change 消息,当前存活的节点编号最小的节点将成为新的主节点。当新的主节点收到 2f 个其它节点的 view-change 消息,则证明有足够多的节点认为主节点有问题,于是就会向其它节点广播 New-view 消息。从节点不会发起 new-view 事件。。对于主节点,发送 new-view 消息后会继续执行上个视图未处理完的请求,从 pre-prepare 阶段开始。其它节点验证 new-view 消息通过后,就会处理主节点发来的 pre-prepare 消息,这时执行的过程就是前面描述的 pbft 过程。这时候View会+1,进入新的视图时代。
前文提到的一些未解决的问题(垃圾回收、高低水位)
checkpoint :
当前节点处理的最新请求序号,之前提到在PRE-PREPARE中,主节点收到请求是会给请求记录编号为n的。比如一个节点正在共识的一个请求编号是101,那么对于这个节点,它的 checkpoint 就是101。
stable checkpoint (稳定检查点):
stable checkpoint 就是大部分节点 (2f+1) 已经共识完成的最大请求序号。比如系统有 4 个节点,三个节点都已经共识完了的请求编号是 213 ,那么这个 213 就是 stable checkpoint 了。
为什么要设置一个stable checkpoint呢?
最大的目的就是减少内存的占用。因为每个节点应该记录下之前曾经共识过什么请求,但如果一直记录下去,数据会越来越大,所以应该有一个机制来实现对数据的删除。那怎么删呢?很简单,比如现在的稳定检查点是 213 ,那么代表 213 号之前的记录已经共识过的了,所以之前的记录就可以删掉了。
高低水位区间[h, H]:
因为每个节点处理速度不同等等原因,我们需要让所有的节点处理的checkpoint处在同一区间内,举个例子,
A节点的checkpoint为1039,B节点的 checkpoint 为1133。当前系统 stable checkpoint 为 1034 。那么1034这个编号就是低水位,而高水位 H=低水位 h+L ,其中L是可以设定的数值。假设我们设置为100,因此系统的高水位为 1034+100=1134。
假设 B 当前的 checkpoint 已经为 1134,而A的 checkpoint 还是 1039 ,假如有新请求给 B 处理时,B会选择等待,等到 A 节点也处理到和 B 差不多的请求编号时,比如 A 也处理到 1112 了,这时会有一个机制更新所有节点的 stabel checkpoint (比如执行完100条Reply消息后进行更新),比如可以把 stabel checkpoint 设置成 1100 ,于是 B 又可以处理新的请求了,如果 L 保持100 不变,这时的高水位就会变成 1100+100=1200 了。
