大数据实操篇 No.10-Flink Standalone集群HA高可用部署
第1章 简介
Flink高可用集群,有多种模式,本章介绍:Standalone独立集群模式的高可用部署,及其使用。
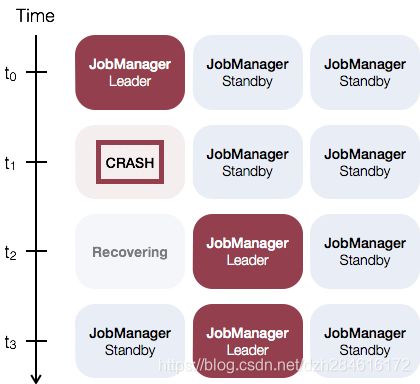
下面先引用一张Flink官网的图:可以看到Standalone集群的高可用其实就是JobManager的高可用。一个Leader JobManager,以及其他多个Standby JobManager,Leader和Standby之间的切换是依赖于zookeeper,所以部署之前必须安装好Zookeeper集群(可以参考笔者的另外一篇文章:大数据实操篇 No.1-Zookeeper集群搭建)。
第2章 集群规划
笔者是在原有的3台机器名为Hadoop10*的机器上安装的Flink,所以这里机器名都是Hadoop100、Hadoop101、Hadoop102。
|
|
Hadoop100(Flink) |
Hadoop101(Flink) |
Hadoop102(Flink) |
| JobManager |
√ |
√ |
√ |
| TaskManager |
√ |
√ |
√ |
第3章 放置Jar包
依赖jar包下载地址:https://flink.apache.org/downloads.html,将hadoop相关的依赖jar包放到flink的lib目录下。
Flink-1.11.0之后已经建议使用配置环境变量的方式(当然首先必须把Hadoop安装好):
export HADOOP_CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath)
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
第4章 修改配置文件
4.1 修改flink-conf.yaml
修改conf目录下flink-conf.yaml文件:
# jobmanager和taskmanager、其他client的RPC通信IP地址,TaskManager用于连接到JobManager/ResourceManager 。HA模式不用配置此项,在master文件中配置,由zookeeper选出leader与standby
jobmanager.rpc.address: localhost
# jobmanager和taskmanager、其他client的RPC通信端口,TaskManager用于连接到JobManager/ResourceManager 。HA模式不用配置此项,在master文件中配置,由zookeeper选出leader与standby
jobmanager.rpc.port: 6123
# jobmanager JVM heap 内存大小
jobmanager.memory.process.size: 1024m
# taskmanager JVM heap 内存大小
taskmanager.memory.process.size: 1024m
# 每个taskmanager提供的任务slots数量
taskmanager.numberOfTaskSlots: 3
# 并行计算个数
parallelism.default: 3
# 高可用模式
high-availability: zookeeper
# JobManager元数据保留在文件系统storageDir中 指向此状态的指针存储在ZooKeeper中
high-availability.storageDir: hdfs://hadoop100:9000/flink/ha/
# Zookeeper集群
high-availability.zookeeper.quorum: zookeeper110:2181,zookeeper111:2181,zookeeper112:2181
# 在zookeeper下的根目录
high-availability.zookeeper.path.root: /flink
# zookeeper节点下的集群ID 该节点下放置了集群所需的所有协调数据 多个flink集群连接同一套zookeeper集群需要配置各自不同的集群ID
high-availability.cluster-id: /default_ns
# 单个flink job重启次数 必须小于等于yarn-site.xml中Application Master配置的尝试次数
#yarn.application-attempts: 10
#==============================================================================
# Fault tolerance and checkpointing
#==============================================================================
# jobmanager (MemoryStateBackend), filesystem (FsStateBackend), rocksdb (RocksDBStateBackend)
state.backend: rocksdb
# 检查点的默认目录。Flink支持的文件系统中存储检查点的数据文件和元数据的默认目录。必须从所有参与的进程/节点(即所有TaskManager和JobManager)访问存储路径。
state.checkpoints.dir: hdfs://hadoop100:9000/flink/checkpoints
# 保存点的默认目录。由状态后端用于将保存点写入文件系统(MemoryStateBackend,FsStateBackend,RocksDBStateBackend)。
state.savepoints.dir: hdfs://hadoop100:9000/flink/savepoints
# 是否应该创建增量检查点。对于增量检查点,只存储前一个检查点的差异,而不存储完整的检查点状态。一些状态后端可能不支持增量检查点并忽略此选项。
state.backend.incremental: false
# jobmanager故障恢复策略,指定作业计算如何从任务失败中恢复 full重新启动所有任务以恢复作业 region重新启动可能受任务失败影响的所有任务
jobmanager.execution.failover-strategy: region
# 全局检查点的保留数量
state.checkpoints.num-retained: 3
# 本地恢复。默认情况下,本地恢复处于禁用状态。本地恢复当前仅涵盖keyed state backends。当前,MemoryStateBackend不支持本地恢复。
state.backend.local-recovery: true
# 存储基于文件的状态以进行本地恢复的根目录。本地恢复当前仅涵盖keyed state backends
taskmanager.state.local.root-dirs: /opt/flink-tm-state4.2 修改masters
修改conf目录下masters文件:
hadoop100:8081
hadoop101:8081
hadoop102:80814.3 修改workers
修改conf目录下workers文件:
hadoop100
hadoop101
hadoop102配置文件修改完后,将文件分发到其他集群。
第5章 启动/停止
5.1 启动Zookeeper
这里略,请参考笔者Zookeeper的文章:大数据实操篇 No.1-Zookeeper集群搭建
5.2 启动HDFS
这里略,请参考笔者的Hadoop的文章:大数据实操篇 No.2-Hadoop集群搭建
5.3 启动Flink集群
$ bin/start-cluster.sh
Starting HA cluster with 3 masters.
Starting standalonesession daemon on host hadoop100.
Starting standalonesession daemon on host hadoop101.
Starting standalonesession daemon on host hadoop102.
Starting taskexecutor daemon on host hadoop100.
Starting taskexecutor daemon on host hadoop101.
Starting taskexecutor daemon on host hadoop102.5.4 停止flink集群
$ bin/stop-cluster.sh
Stopping taskexecutor daemon (pid: 8841) on host hadoop100.
Stopping taskexecutor daemon (pid: 8263) on host hadoop101.
Stopping taskexecutor daemon (pid: 7960) on host hadoop102.
Stopping standalonesession daemon (pid: 8452) on host hadoop100.
Stopping standalonesession daemon (pid: 7903) on host hadoop101.
Stopping standalonesession daemon (pid: 7590) on host hadoop102.5.5 查看运行进程
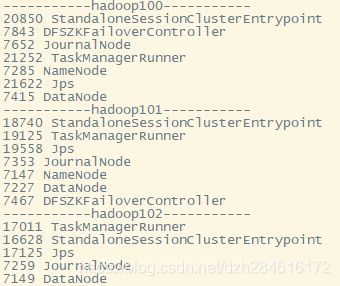
可以查看到三台机器上运行的进程情况:
第6章 主备切换验证
6.1 打开Apache Flink Dashboard
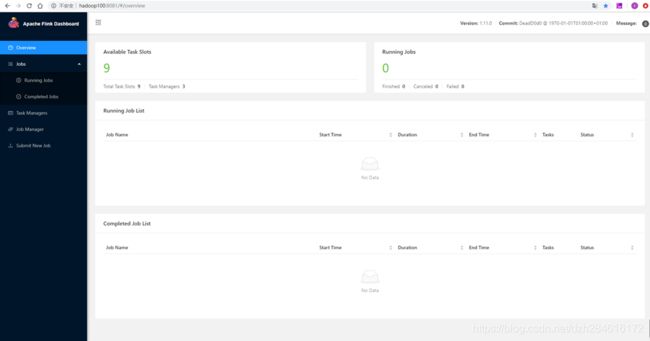
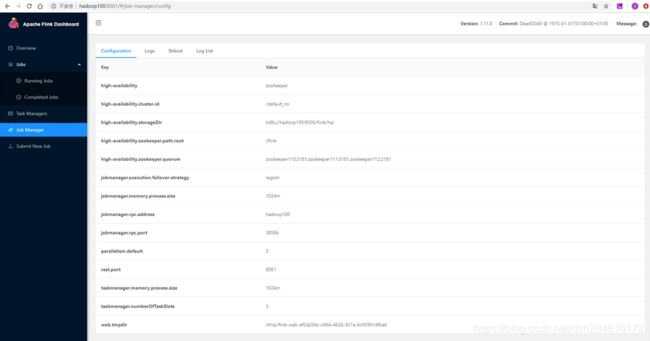
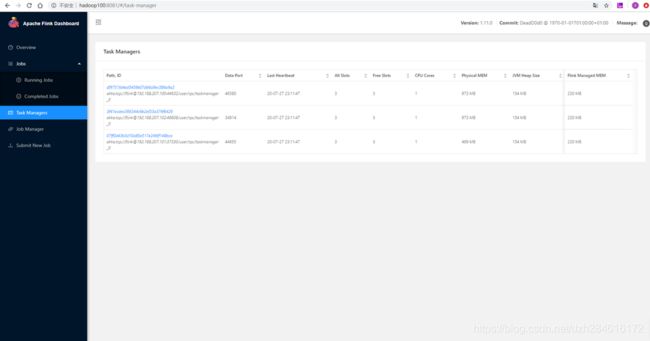
上图可以看到所有的TaskManager都注册到了这个JobManager上;
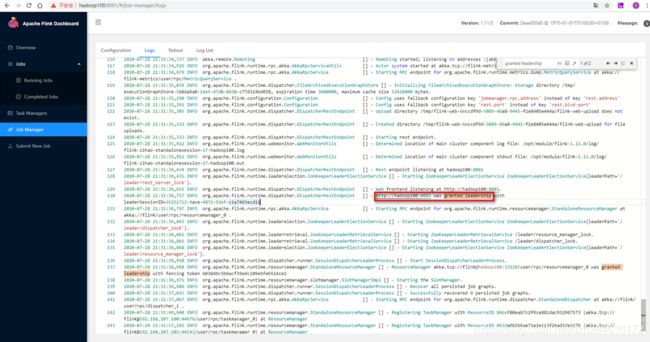
(补充:上图是笔者后续补充的,日志时间与其他图片有差异,都来自同一个集群的standalone模式,可以忽略时间差异。)
6.2 Kill掉Active JobManager
Kill Hadoop100上的StandaloneSessionClusterEntrypoint进程后,查看WEB界面:
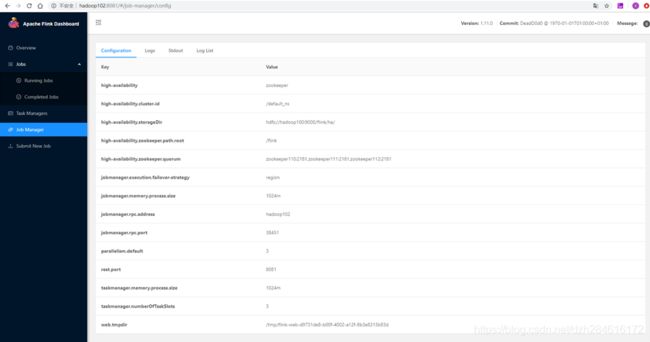
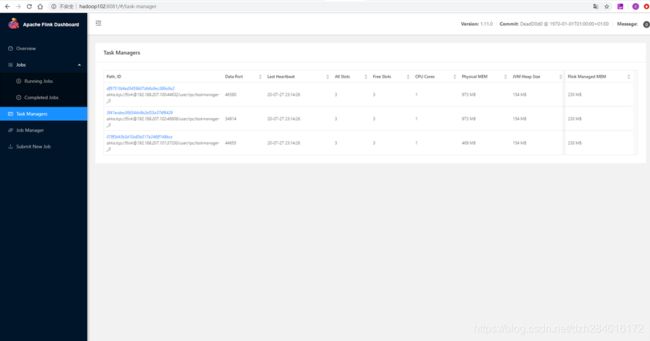
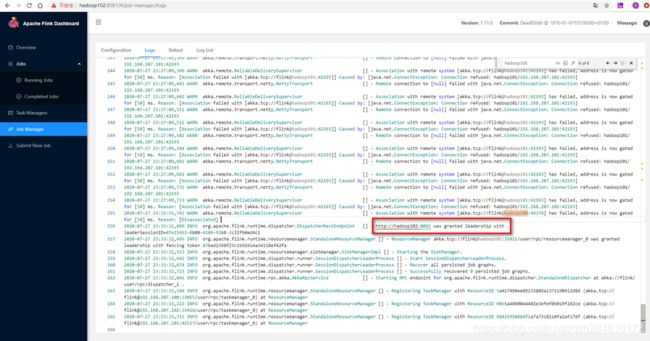
在hadoop102的日志中我们能看到leader选举的日志 ,这个时候Hadoop102上的JobManager被选为了Leader 。
再kill掉hadoop102的Active JobManager进程:StandaloneSessionClusterEntrypoint 。
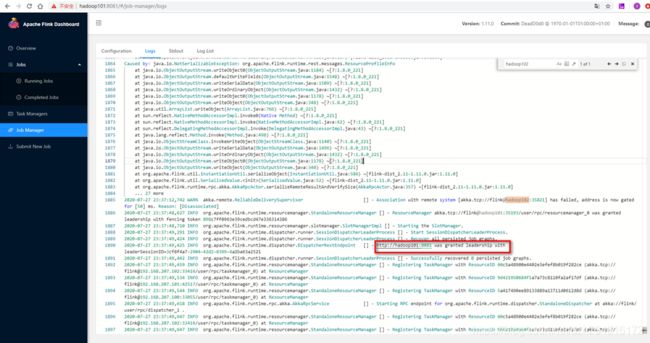
在hadoop101的日志中我们能看到leader选举的日志,这个时候Hadoop101上的JobManager被选为了Leader 。
至此,Flink Standalone集群模式下JobManager的高可用主备切换就实现了,即Standalone集群模式高可用部署就完成了。