数据仓库 — 06_Flume的安装与部署(Flume组成框架、Agent内部原理、安装配置、日志采集配置文件、拦截器的编写、Flume群起脚本、Flume启动报错解决)
文章目录
- 1 概述
-
- 1.1 Flume定义
- 1.2 Flume组成架构
-
- 1.2.1 Agent
- 1.2.2 Source
- 1.2.3 Channel
- 1.2.4 Sink
- 1.2.5 Event
- 1.3 Flume拓扑结构
-
- 1.3.1 Agent连接
- 1.3.2 单source多channel、sink
- 1.3.3 负载均衡
- 1.3.4 Agent聚合
- 1.4 Flume Agent内部原理
- 2 Flume的安装与配置
-
- 2.1 下载地址
- 2.2 安装部署
- 3 项目经验——flume组件
-
- 3.1 source
- 3.2 channel
- 4 日志采集的flume配置
-
- 4.1 配置分析
- 4.2 flume的具体配置文件
- 4.3 拦截器
-
- 4.3.1 pom.xml
- 4.3.2 LogETLInterceptor
- 4.3.3 LogETLInterceptor
- 4.3.4 LogUtils
- 4.4 Flume群起/停止脚本
- 5 注意点
-
- 5.1 ResourceManager无法启动
- 5.2 java.io.EOFException: End of input at line 1 column 1
- 5.3 Flume1.8中文文档(强烈推荐)
欢迎访问笔者个人技术博客: http://rukihuang.xyz/
学习视频来源于尚硅谷,视频链接: 尚硅谷大数据项目数据仓库,电商数仓V1.2新版,Respect!
1 概述
1.1 Flume定义
- Flume 是Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume 基于流式架构,灵活简单。
- Flume最主要的作用:实时读取服务器本地磁盘的数据,将数据写入到HDFS
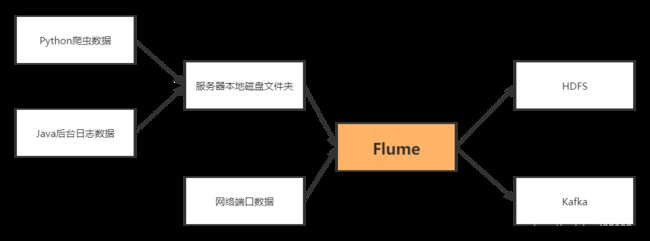
1.2 Flume组成架构

1.2.1 Agent
- Agent 是一个JVM 进程,它以事件的形式将数据从源头送至目的,是Flume 数据传输的基本单元。
- Agent 主要有3 个部分组成,
Source、Channel、Sink。
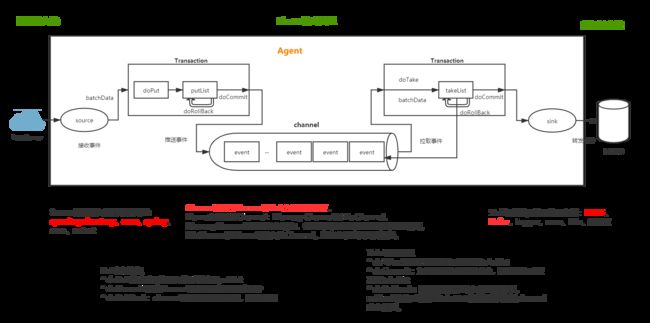
1.2.2 Source
- Source 是负责接收数据到Flume Agent 的组件。Source 组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。
1.2.3 Channel
- Channel 是位于Source 和Sink 之间的缓冲区。因此,Channel 允许Source 和Sink 运作在不同的速率上。Channel 是线程安全的,可以同时处理几个Source 的写入操作和几个Sink的读取操作。
- Flume 自带两种Channel:
Memory Channel和File Channel。 - Memory Channel 是内存中的队列。Memory Channel 在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel 就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
- File Channel 将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
- Flume 自带两种Channel:
1.2.4 Sink
- Sink 不断地轮询Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
- Sink 是完全事务性的。在从Channel 批量删除数据之前,每个Sink 用Channel 启动一个事务。批量事件一旦成功写出到存储系统或下一个Flume Agent,Sink 就利用Channel 提交事务。事务一旦被提交,该Channel 从自己的内部缓冲区删除事件。
- Sink 组件目的地包括hdfs、logger、avro、thrift、ipc、file、null、HBase、solr、自定义。
1.2.5 Event
- 传输单元,Flume 数据传输的基本单元,以事件的形式将数据从源头送至目的地。
1.3 Flume拓扑结构
1.3.1 Agent连接

1.3.2 单source多channel、sink
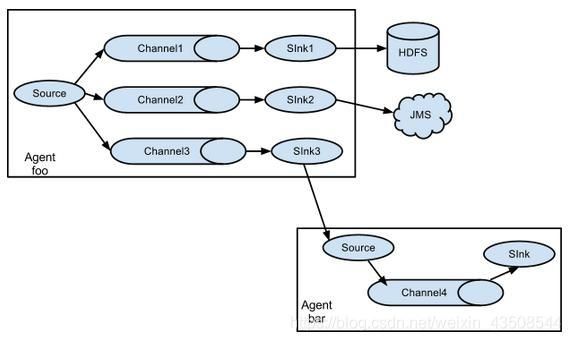
1.3.3 负载均衡
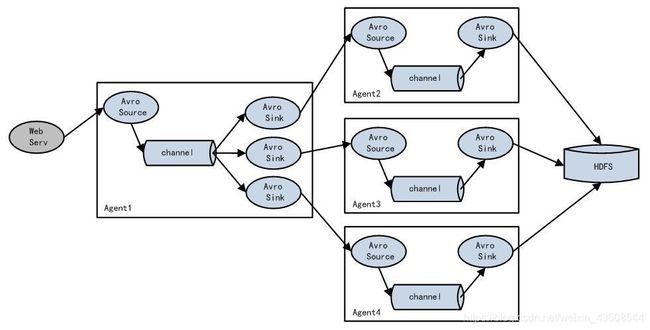
1.3.4 Agent聚合

1.4 Flume Agent内部原理
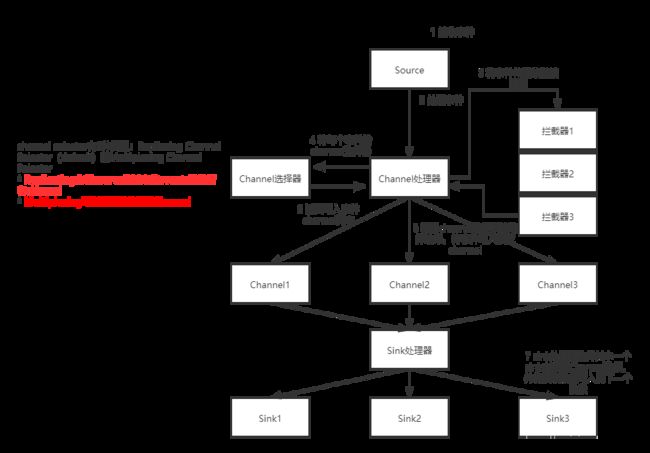
2 Flume的安装与配置
2.1 下载地址
- Flume官网地址:http://flume.apache.org/
- 文档地址:http://flume.apache.org/FlumeUserGuide.html
- 下载地址:http://archive.apache.org/dist/flume/
2.2 安装部署
-
将
apache-flume-1.7.0-bin.tar.gz上传到102机器 的/opt/software目录下 -
解压安装至
/opt/module目录下
tar -zxvf apache-flume-1.7.0-bin.tar.gz -C /opt/module/
- 将
/opt/module/apache-flume-1.7.0-bin/conf中的flume-env.sh.template文件修改为flume-env.sh, 并配置flume-env.sh文件
export JAVA_HOME=/opt/module/jdk1.8.0_144
3 项目经验——flume组件
3.1 source
Taildir Source相比Exec Source、Spooling Directory Source的优势TailDir Source:断点续传、多目录。Flume1.6 以前需要自己自定义Source 记录每次读取文件位置,实现断点续传。Exec Source:可以实时搜集数据,但是在Flume 不运行或者Shell 命令出错的情况下,数
据将会丢失。Spooling Directory Source:监控目录,不支持断点续传。
3.2 channel
- 采用Kafka Channel,省去了Sink,提高了效率。KafkaChannel 数据存储在Kafka 里面,所以数据是存储在磁盘中。
- 注意在Flume1.7 以前,Kafka Channel 很少有人使用,因为发现parseAsFlumeEvent 这个配置起不了作用。也就是无论parseAsFlumeEvent 配置为true 还是false,都会转为Flume Event。这样的话,造成的结果是,会始终都把Flume 的headers 中的信息混合着内容一起写入Kafka的消息中,这显然不是我所需要的,我只是需要把内容写入即可。
4 日志采集的flume配置
4.1 配置分析

4.2 flume的具体配置文件
- 由于flume要与kafka整合,因此在
/opt/module/flume/conf目录下创建file-flume-kafka.conf文件(由于使用flume1.7,在启动flume时出现报错,经查证是源码的问题,详见下文注意点5.2,笔者最后使用了flume1.8,因此目录更改为/opt/module/flume1.8/conf)
a1.sources=r1
a1.channels=c1 c2
# configure source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /opt/module/flume1.8/test/log_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /tmp/logs/app.+
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1 c2
#interceptor
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.LogETLInterceptor$Builder
a1.sources.r1.interceptors.i2.type = com.atguigu.flume.interceptor.LogTypeInterceptor$Builder
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = topic
a1.sources.r1.selector.mapping.topic_start = c1
a1.sources.r1.selector.mapping.topic_event = c2
# configure channel
a1.channels.c1.type =org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.channels.c1.kafka.topic = topic_start
a1.channels.c1.parseAsFlumeEvent = false
a1.channels.c1.kafka.consumer.group.id = flume-consumer
a1.channels.c2.type =org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c2.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.channels.c2.kafka.topic = topic_event
a1.channels.c2.parseAsFlumeEvent = false
a1.channels.c2.kafka.consumer.group.id = flume-consumer

4.3 拦截器
- 创建Maven工程
flume-interceptor - 创建包名:
com.atguigu.flume.interceptor
4.3.1 pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.atguigugroupId>
<artifactId>flume-interceptorartifactId>
<version>1.0-SNAPSHOTversion>
<dependencies>
<dependency>
<groupId>org.apache.flumegroupId>
<artifactId>flume-ng-coreartifactId>
<version>1.7.0version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-pluginartifactId>
<version>2.3.2version>
<configuration>
<source>1.8source>
<target>1.8target>
configuration>
plugin>
<plugin>
<artifactId>maven-assembly-pluginartifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
project>
4.3.2 LogETLInterceptor
package com.atguigu.flume.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
public class LogETLInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
// 1 获取数据
byte[] body = event.getBody();
String log = new String(body, Charset.forName("UTF-8"));
// 2 判断数据类型并向Header中赋值
if (log.contains("start")) {
if (LogUtils.validateStart(log)){
return event;
}
}else {
if (LogUtils.validateEvent(log)){
return event;
}
}
// 3 返回校验结果
return null;
}
@Override
public List<Event> intercept(List<Event> events) {
ArrayList<Event> interceptors = new ArrayList<>();
for (Event event : events) {
Event intercept1 = intercept(event);
if (intercept1 != null){
interceptors.add(intercept1);
}
}
return interceptors;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new LogETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
4.3.3 LogETLInterceptor
package com.atguigu.flume.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class LogTypeInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
// 区分日志类型: body header
// 1 获取body数据
byte[] body = event.getBody();
String log = new String(body, Charset.forName("UTF-8"));
// 2 获取header
Map<String, String> headers = event.getHeaders();
// 3 判断数据类型并向Header中赋值
if (log.contains("start")) {
headers.put("topic","topic_start");
}else {
headers.put("topic","topic_event");
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
ArrayList<Event> interceptors = new ArrayList<>();
for (Event event : events) {
Event intercept1 = intercept(event);
interceptors.add(intercept1);
}
return interceptors;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new LogTypeInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
4.3.4 LogUtils
package com.atguigu.flume.interceptor;
import org.apache.commons.lang.math.NumberUtils;
public class LogUtils {
public static boolean validateEvent(String log) {
// 服务器时间 | json
// 1549696569054 | {"cm":{"ln":"-89.2","sv":"V2.0.4","os":"8.2.0","g":"[email protected]","nw":"4G","l":"en","vc":"18","hw":"1080*1920","ar":"MX","uid":"u8678","t":"1549679122062","la":"-27.4","md":"sumsung-12","vn":"1.1.3","ba":"Sumsung","sr":"Y"},"ap":"weather","et":[]}
// 1 切割
String[] logContents = log.split("\\|");
// 2 校验
if(logContents.length != 2){
return false;
}
//3 校验服务器时间
if (logContents[0].length()!=13 || !NumberUtils.isDigits(logContents[0])){
return false;
}
// 4 校验json
if (!logContents[1].trim().startsWith("{") || !logContents[1].trim().endsWith("}")){
return false;
}
return true;
}
public static boolean validateStart(String log) {
// {"action":"1","ar":"MX","ba":"HTC","detail":"542","en":"start","entry":"2","extend1":"","g":"[email protected]","hw":"640*960","l":"en","la":"-43.4","ln":"-98.3","loading_time":"10","md":"HTC-5","mid":"993","nw":"WIFI","open_ad_type":"1","os":"8.2.1","sr":"D","sv":"V2.9.0","t":"1559551922019","uid":"993","vc":"0","vn":"1.1.5"}
if (log == null){
return false;
}
// 校验json
if (!log.trim().startsWith("{") || !log.trim().endsWith("}")){
return false;
}
return true;
}
}
- 利用maven将项目打包,并将
target文件夹下的flume-interceptor-1.0-SNAPSHOT.jar上传到/opt/module/flume1.8/lib目录下,这样flume才能使用自定义拦截器 - 将自定义拦截器分发到hadoop103、hadoop104机器上
xsync flume/
4.4 Flume群起/停止脚本
- 在
~/bin目录下创建脚本f1.sh
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103
do
echo " --------开始$i 采集flume-------"
ssh $i "nohup /opt/module/flume1.8/bin/flume-ng agent --name a1 --conf-file /opt/module/flume1.8/conf/file-flume-kafka.conf -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume1.8/flume.log 2>&1 &"
done
};;
"stop"){
for i in hadoop102 hadoop103
do
echo " --------停止$i 采集flume-------"
ssh $i "ps -ef | grep file-flume-kafka | grep -v grep|awk '{print \$2}' | xargs kill"
done
};;
esac
说明:
nohup,该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。nohup就是不挂起的意思,不挂断地运行命令。awk默认分隔符为空格xargs表示取出前面命令运行的结果,作为后面命令的输入参数。
- 增加脚本执行权限
chmod 777 f1.sh
- 启动(
~/bin/)
f1.sh start
- 停止
f1.sh stop
5 注意点
5.1 ResourceManager无法启动
- 在部署
ResourceManager节点上使用群起命令。参考文章:java.net.BindException: Problem binding to [hadoop21:8031] java.net.BindException: 无法指定被请求的地址
5.2 java.io.EOFException: End of input at line 1 column 1
- 有时候启动flume会报这个错误,是因为读取了空的
log_position.json文件(这个文件是记录flume读取日志文件位置,详见4.2配置文件)。这个错误偶尔会遇到,是源码的问题,2种方式解决:- 删除这个位置记录文件后,再启动flume
- flume1.8修复了这个问题,使用flume1.8(笔者采取了这个方式解决)
- 参考文章:求问使用flume 1.7 taildir时出现如下错误怎么办?
5.3 Flume1.8中文文档(强烈推荐)
- Flume1.8中文文档:flume.liyifeng.org