K近邻法(KNN)-原理及编码实现
一、KNN算法概述
K近邻算法(k-nearest neighbor,KNN)是一种基本的分类和回归方法,KNN算法对于一个新的样本只需要计算和他最近的K个点,K个点中多数表明他是那个类,他就是那个类。
KNN没有和别的算法一样,要先训练,然后才能预测。这个算法可以直接预测该点的标记。只是在查找最近的K个点的时候,需要遍历整个数据集,消耗的时间会非常大。为了减少查找的时间,才有了K-D树。
KNN模型有三个基本要素,距离度量,K值的选择和分类决策规则。距离度量主要来确定,查找K个点的时候,是用欧式距离,曼哈顿距离还是LP距离。K值的选择主要确定,在查找最近的邻居的时候,到底要查找几个最近的邻居,K值太多,会发生预测错误,K值太小,则会对周围的数据很敏感。分类决策规则主要说,多数表决规则等价于经验最小化。
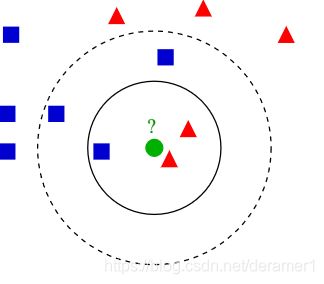
K值对于分类结果的影响如下图(图片摘自维基百科)。当K值选为3的时候,图中绿色的点被分类成红色的三角块,当K值选取为5的时候,图中绿色的点被分为蓝色的正方形。
常见的距离度量如下图所示:

二、KNN编码实现
下面是KNN的实现,数据集采用sklearn-dataset里面的iris数据集
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter对数据进行预处理
iris = load_iris()
df = pd.DataFrame(iris.data,columns = iris.feature_names)
df['label'] = pd.DataFrame(iris.target)
df.columns = ['sepal length','sepal width','petal length','petal width','label']
data = np.array(df.iloc[:100,[0,1,-1]])
X , Y = data[:,:-1],data[:,-1]
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size = 0.2)处理后的数据X_train,Y_train,形式如下,X_train是萼片的长度和宽度,Y_train是标签

class KNN:
#p是用来选择距离度量的参数,p=1为曼哈顿距离,p=2是欧式距离
#n是用来确定最近邻居的个数
def __init__(self,X_train,Y_train,p = 2,n = 3):
self.X = X_train
self.Y = Y_train
self.p = p
self.n = n
def prediction(self,X):
KNN_list = []
#首先计算,x和数据集中前三个元素的距离,并作为最短距离
for i in range(self.n):
distance = np.linalg.norm(abs(X - self.X[i]),ord=self.p)
KNN_list.append((distance,self.Y[i]))
#遍历整个数据集,查找距离最短的三个数据,KNN最浪费时间的地方就在这里,为了解决这个问题,引入了KD树
for i in range(self.n,len(X_train)):
max_index = KNN_list.index(max(KNN_list,key = lambda x:x[0]))
distance = np.linalg.norm(abs(X - self.X[i]),ord=self.p)
if distance < KNN_list[max_index][0]:
KNN_list[max_index] = (distance,self.Y[i])
#将3个最短距离的标签输出
knn = [k[-1] for k in KNN_list]
#统计标签的个数
count_pairs = Counter(knn)
#把标记最多的元素找出来
max_count = sorted(count_pairs,key = lambda x:x)[-1]
return max_count
#测试KNN的准确率
def scores(self,X_test,Y_test):
right_number = 0
for x,y in zip(X_test,Y_test):
label = self.prediction(x)
if(y==label):
right_number+=1
return right_number/len(X_test)
clf = KNN(X_train,Y_train)
#判断6,3点的标签
test_point = [6.0, 3.0]
print('Test Point: {}'.format(clf.prediction(test_point)))
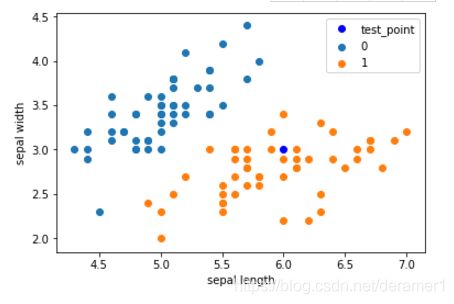
#将数据集合6,3点画再一起
plt.scatter(df[:50]['sepal length'], df[:50]['sepal width'], label='0')
plt.scatter(df[50:100]['sepal length'], df[50:100]['sepal width'], label='1')
plt.plot(test_point[0], test_point[1], 'bo', label='test_point')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()图片如下:
参考资料:
1.李航-统计学习方法