上一篇博客主要聊到了keepalived高可用LVS集群的相关配置,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/13659428.html;keepalived高可用LVS集群是Keepalived的设计之初的功能,所以它高可用LVS集群内置了对LVS的RS的健康状态检测,自动生成IPVS规则;我们知道LVS是Linux内核功能,本质上在用户空间不会监听任何端口,它的主要作用是对用户请求的流量做4层调度,所以对于这种没有进程,没有端口信息的服务我们怎么去判断它是否正常就先得尤为重要;同样的道理对于高可用nginx或haproxy这类在用户空间有监听端口和进程的服务来说,如果用keepalived做高可用,我们需要考虑到我们高可用的服务是否正常可用,从而实现在服务不正常的情况下,把对应的VIP能够迁移到其他节点;为了实现能够检测到高可用的服务是否正常,keepalived提供了调用外部脚本的接口,让我们配置对高可用的服务做可用性检测;根据我们定义的脚本,keepalived会周期性的去执行我们的定义的脚本,根据脚本执行退出码判断服务是否可用,一旦发生服务不可用,或者可用性检测不通过,它就会触发当前keepalived节点的优先级降低,从而实现当前节点在通告优先级时,触发备份节点接管VIP,从而实现VIP转移,服务的高可用;
在keepalived的配置文件中,我们可以用vrrp_script {...} 来定义我们可以执行的脚本相关信息;用track_script {..}在对应vrrp实例中调用vrrp_script定义的脚本;
示例:利用脚本对LVS做可用性检测
1、编写脚本
[root@node01 keepalived]# ls
check_lvs.sh keepalived.conf keepalived.conf.bak notify.sh
[root@node01 keepalived]# chmod a+x check_lvs.sh
[root@node01 keepalived]# ll
total 16
-rwxr-xr-x 1 root root 98 Sep 13 22:26 check_lvs.sh
-rw-r--r-- 1 root root 1611 Sep 13 22:24 keepalived.conf
-rw-r--r-- 1 root root 3598 Sep 8 23:29 keepalived.conf.bak
-rwxr-xr-x 1 root root 472 Sep 10 13:58 notify.sh
[root@node01 keepalived]# cat check_lvs.sh
#!/bin/bash
ping -c 2 192.168.0.1 &> /dev/null
if [ $? -eq 0 ];then
exit 0
else
exit 1
fi
[root@node01 keepalived]#
提示:以上脚本主要是利用ping 192.168.0.1这个地址来判断推出码是0还是1,正常退出时0,非正常退出为1;
2、配置keepalived调用上面的脚本,并在VIP所在实例中引用;

提示:以上配置表示定义了一个脚本,名为check_LVS(这个名称可以任意起,主要起标识作用,后面在实例中引用的一个标识);这个脚本执行时间间隔为每2秒执行一次,超时时长为2秒,如果脚本执行失败(退出码非0)就把对应节点的优先级降低20(通常这个降低的值要大于两节点优先级之差就行,意思就是降低后的优先级要小于备份节点优先级,这样才有意义);脚本执行连续3次检测都为成功状态(脚本推出码都为0),则keepalived就标记该实例为OK状态,并会一直检测下去,如果连续3次检查都为失败状态(退出码非0),则标记对应实例为KO状态;一旦标记对应实例为失败状态就会触发当前节点的优先级降低;从而在通告心跳时,会通告降低后的优先级,从而实现备份节点接管VIP来完成vip转移;
完整的keepalived配置


[root@node01 keepalived]# cat keepalived.conf ! Configuration File for keepalived global_defs { notification_email { root@localhost } notification_email_from node01_keepalived@localhost smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id node01 vrrp_skip_check_adv_addr vrrp_strict vrrp_iptables vrrp_garp_interval 0 vrrp_gna_interval 0 vrrp_mcast_group4 224.0.12.132 } vrrp_script check_LVS { script "/etc/keepalived/check_lvs.sh" interval 2 timeout 2 weight -20 rise 3 fall 3 } vrrp_instance VI_1 { state MASTER interface ens33 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 12345678 } virtual_ipaddress { 192.168.0.111/24 brd 192.168.0.255 dev ens33 label ens33:1 } notify_master "/etc/keepalived/notify.sh master" notify_backup "/etc/keepalived/notify.sh backup" notify_fault "/etc/keepalived/notify.sh fault" track_script { check_LVS } } virtual_server 192.168.0.111 80 { delay_loop 3 lb_algo wrr lb_kind DR protocol TCP sorry_server 127.0.0.1 80 real_server 192.168.0.43 80 { weight 1 nb_get_retry 2 delay_before_retry 2 connect_timeout 30 HTTP_GET { url { path /index.html status_code 200 } } } real_server 192.168.0.44 80 { weight 1 nb_get_retry 2 delay_before_retry 2 connect_timeout 30 HTTP_GET { url { path /index.html status_code 200 } } } } [root@node01 keepalived]#
提示:vrrp_script中的script可以是脚本路径,也可以是一段命令;
验证:重启keepalived,修改脚本中的IP地址,模拟故障,故意让其对指定地址ping不通,看看对应vip是否会从master节点飘逸到备份节点?对应节点的优先级是否有变化?
未修改脚本时,vip在node01上

修改脚本以后
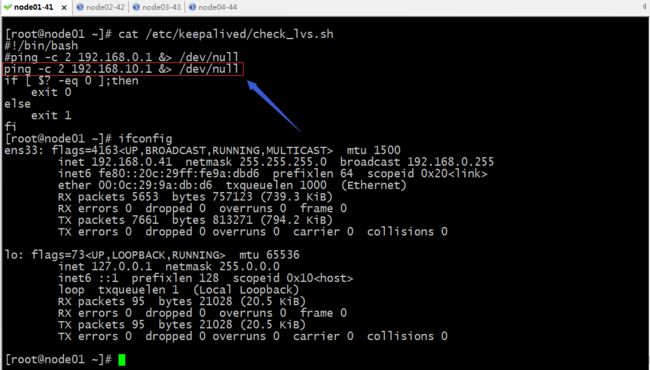
提示:修改脚本以后对应的VIP就没有在node01上了;
查看node01上keepalived的日志信息,看看它是如何故障转移的
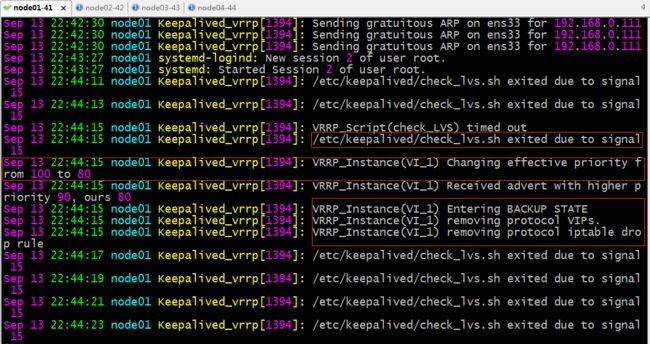
提示:从日志文件可以看到,当keepalived周期性去执行check_lvs.sh脚本时,连续3次都执行失败,就触发了动态调整当前节点所在keepalived的优先级,把原来优先级为100调整至80,然后通告自己的心跳信息时,又触发了备份节点通告自己的优先级信息,对应主节点收到高于它的优先级通告,所以它就自动转换成backup状态,并删除了VIP;然后后续也在每隔2秒检测一次脚本执行否正常;
在node02上查看vip是否存在?

访问VIP看看服务是否可访问?

提示:可以看到对应用户访问还是可以正常访问;
验证:修改脚本为正常可通信地址,看看对应节点是否会重新转换为master角色呢?对应vip是否会漂移回来呢?

提示:可看到修改脚本以后,对应vip就回来了;
查看keepalived的日志

提示:可以看到当脚本执行成功以后,首先会触发当前节点的优先级还原为原有优先级,并通告出去,然后把当前节点从backup角色转换为master角色,接管VIP;
以上示例主要用于对那种高可用服务在用户空间没有监听端口,没有进程,我们需要借助某种机制去判读该服务是否正常,比如上面我们利用ping某个ip地址去判断LVS是否正常,从而来决定对应节点的优先级是否调整,进而来决定vip是否转移;当然对于在用户空间有监听端口,有进程的服务也是同样的套路,我们可以利用脚本去检测端口是否存在,或者对应进程是否正常来决定VIP是否转移;
示例:keepalived利用脚本来检测nginx进程是否正常,从而来实现对nginx的高可用
1、编写脚本

提示:以上脚本利用killall命令对nginx进程发送0号信号,去判断对应的nginx进程是否存在,如果存在该命令会返回0,否则返回非0;利用命令的返回值来确定脚本退出码;
2、在keepalived的配置文件中定义脚本相关参数,并在vrrp实例中引用定义的脚本信息

完整的keepalived配置
[root@node01 ~]# cat /etc/keepalived/keepalived.conf ! Configuration File for keepalived global_defs { notification_email { root@localhost } notification_email_from node01_keepalived@localhost smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id node01 vrrp_skip_check_adv_addr vrrp_strict vrrp_iptables vrrp_garp_interval 0 vrrp_gna_interval 0 vrrp_mcast_group4 224.0.12.132 } vrrp_script check_LVS { script "/etc/keepalived/check_lvs.sh" interval 2 timeout 2 weight -20 rise 3 fall 3 } vrrp_script check_nginx { script "/etc/keepalived/check_nginx.sh" interval 2 timeout 2 weight -20 rise 3 fall 3 } vrrp_instance VI_1 { state MASTER interface ens33 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 12345678 } virtual_ipaddress { 192.168.0.111/24 brd 192.168.0.255 dev ens33 label ens33:1 } notify_master "/etc/keepalived/notify.sh master" notify_backup "/etc/keepalived/notify.sh backup" notify_fault "/etc/keepalived/notify.sh fault" track_script { check_LVS check_nginx } } [root@node01 ~]#
提示:vrrp_script需要定义在实例之外,表示引用一段上下文来定义脚本相关信息;定义了脚本信息,如果不在实例中引用,它是不会周期性的去执行脚本,只有在实例中引用的脚本名称以后(这里的名称是vrrp_script后面的名称)才会使对应的脚本周期性的去执行;
在node01和node02上安装nginx
yum install nginx -y
提供测试页面


重启keepalived 和nginx
systemctl restart nginx keepalived.service


提示:可以看到重启nginx和keepalived以后,在node01上有VIP和80端口,在node02上没有vip,但80端口处于监听状态;如果此时有用户访问vip,就会由node01上的nginx提供响应;
验证:用浏览器访问vip,看看响应的内容是否是我们在node01上提供的测试页面?
验证:把node01上的nginx停掉,看看对应的服务是否还可访问?

提示:可以看到把node01上的nginx停掉以后,对应的vip也就随之被删除;
再次访问vip看看是否会有响应?
提示:可以看到现在访问vip响应的页面内容变成了node02上nginx提供的测试页面;说明现在是由node02上的nginx在提供服务;
到此keepalived高可用nginx的配置就完成了,至于nginx怎么工作,是否为调度器,这里的keepalived并不关心,它只关心nginx进程是否正常;对于keepalived高可用其他服务,思路都是类似的,不同的是对于不同的服务,检测脚本可能有所不同;