关注度越来越高的行人重识别,有哪些热点?


来源 | HyperAI超神经
责编 | Carol
封图 | CSDN付费下载自视觉中国
在茫茫人海中,你能不能一眼就找到想找的那个人?
如今,这个任务对于计算机来说,可能是小菜一碟了。而这得益于近年行人重识别技术的飞速发展。
行人重识别(Person Re-identification),也称行人再识别,简称 ReID,是利用计算机视觉技术,判断图像或者视频序列中,是否存在特定行人的技术。直观点来说,就是能够通过穿着、体态、发型等特征,识别出不同场景中的同一个目标人物,因此它也被称作跨境追踪技术。

行人重识别被称为人脸识别之后的「杀手级应用」
行人重识别已经成为人脸识别之后,计算机视觉领域的一个重点研究方向。
尽管人脸识别技术已经十分成熟,但在很多情况下,比如人群密集、或监控摄像头分辨率低、拍摄角度较偏等,人脸常常无法被有效识别。行人重识别便成为了重要补充。
因此,人脸重识别近年来也得到越来越多的关注,其相关应用也日益广泛。
了解一项技术,我们首先要了解它解决的问题是什么,如何取得突破,发展到什么阶段了,又存在哪些挑战。接下来,我们将进行全面解析。

行人重识别用在哪儿?
首先,上文中已提到,行人重识别是人脸识别技术的一个重要补充。
人脸识别的前提是:清晰的正脸照。但在图像只有背面、或其它看不到人脸的角度时,人脸识别便失效了。这时候,行人重识别便可通过姿态、衣着等特征,继续追踪目标人物。
目前,行人重识别技术在安防领域、自动驾驶等领域都有着广泛的应用。比如:
智能安防:警方办案人员能够借助 ReID 帮助快速筛查可疑人员;
智能寻人系统:在人流量较大的场所如机场、火车站,通过 ReID 寻找走失儿童和老人;
智能商业:ReID 可以根据行人外观的照片,实时动态跟踪用户轨迹,以此了解了解用户在商场的兴趣所在,以便优化用户体验;
自动驾驶系统:通过 ReID,能够更好地识别行人,提升自动驾驶安全性。
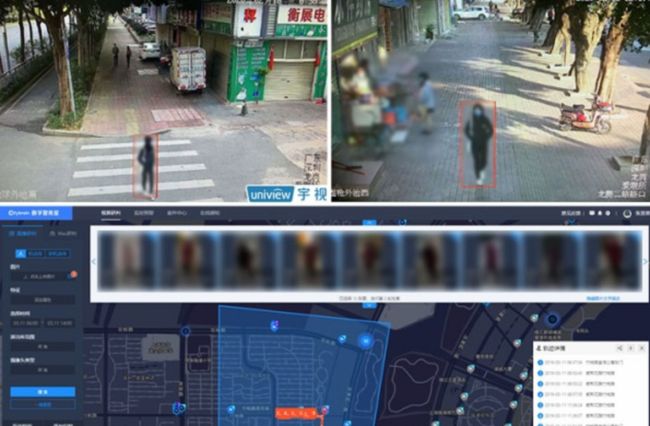
某安防领域解决方案提供商,借助 ReID 快速寻回走失少年

技术突破的关键:大规模数据集
根据相关研究者总结,实现行人重识别技术,一般需要以下五个步骤:
数据收集;
包围框生成;
训练数据标注;
模型训练;
行人检索
其中,数据收集作为第一步,是整个行人重识别研究的基础。近年来,行人重识别之所以取得重大突破,离不开大规模数据集的推动与支撑。
本篇将介绍几个行人检测常用数据集,以供大家研究和训练模型。
INRIA Person Dataset 行人检测数据集
INRIA Person 数据集目前是最流行的、使用最多的静态行人检测数据集之一,由 INRIA(法国国家信息与自动化研究所)于 2005 年发布。该数据集用来对图像和视频中的直立行人进行检测。
该数据集包含两类格式的数据。
第一类:原始图像和相应的直立行人标注;
第二类:标准化为 64x128 像素的直立行人正类和对应图片的负类图像。

数据集中每张图片上只标出身高 > 100cm 的直立的人
该数据集基本信息如下:
INRIA Person Dataset
发布机构: INRIA
包含数量:训练集与测试集共 2573 张图像
数据格式:正样本为 .png 格式,负样本为 .jpg 格式
数据大小:969MB
更新时间:2005 年
下载地址:https://hyper.ai/datasets/5331
相关论文:
https://lear.inrialpes.fr/people/triggs/pubs/Dalal-cvpr05.pdf
UCSD Pedestrian 行人视频数据集
UCSD Pedestrian 行人视频数据由加州大学和香港城市大学收集整理,于 2013 年 2 月发布。
该数据集用于运动分割和人群计数。数据集包含了 UCSD(加州大学圣迭戈分校)人行道上行人的视频,均来自一个固定的摄像机。
其中,所有视频为 8 位灰度,尺寸 238×158,10 帧/秒。原始视频是 740×480,30 帧/秒,如果有需求可以提供。
视频目录包含两个场景的视频(分为 vidf 和 vidd 两个目录)。每个场景都在自己的 vidX 目录中,并被分割成一组 .png 片段。

数据集示例
该数据集基本信息如下:
UCSD Pedestrian Dataset
发布机构: UCSD,香港城市大学
包含数量:长度约 10 小时的视频
数据格式:.png
数据大小:vidf:787MB;vidd:672MB
更新时间:2013 年 2 月
下载地址:https://hyper.ai/datasets/9370
相关论文:
http://visal.cs.cityu.edu.hk/static/downloads/crowddoc/README-vids.pdf
Caltech Pedestrian Detection Benchmark
Caltech Pedestrian Detection Benchmark 数据库,由加州理工学院于 2009 年发布,并且每年都持续更新。
该数据库是目前规模较大的行人数据库,包含约 10 个小时的视频,主要由行驶在城市中正常交通环境的车辆的车载摄像头拍摄,视频的分辨率为 640x480,30 帧/秒。
视频中标注了共计约 250000 帧(约 137 分钟),350000 个矩形框,2300 个行人,另外还对矩形框之间的时间对应关系及其遮挡的情况进行标注。

该数据集基本信息如下:
Caltech Pedestrian Dataset
发布机构: 加州理工学院
包含数量:训练集与测试集共2573 张图像
数据格式:.jpg
数据大小:11.12GB
更新时间:2019 年 7 月
下载地址:https://hyper.ai/datasets/5334
相关论文:
http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/files/CVPR09pedestrians.pdf

先进方法有哪些?
行人重识别领域的研究已有近三十年,近年来,该技术得益于数据集的大规模化、深度学习的发展,取得了长足的发展。
我们在此例举两个最新提出的方法,以供大家学习与参考。
消除不同摄像机的风格差异问题
在计算机视觉国际顶会 CVPR 2020 中,中科院发表的论文《Unity Style Transfer for Person Re-Identification》(《行人重识别的一致风格转移》)中,提出了一种 UnityStyle 自适应方法,该方法可以统一不同摄像机之间的风格差异。

论文地址:http://r6a.cn/dbWQ
无论是同一摄像头还是不同摄像头,在拍摄画面时,受时间,光照,天气等影响,都会产生较大的差异,为目标查询带来困难。
为了解决这个问题,研究团队首先创建了 UnityGAN 来学习相机之间的风格变化,为每个相机生成形状稳定的 styleunity 图像,将其称之为 UnityStyle 图像。
同时,他们使用 UnityStyle 图像来消除不同图像之间的风格差异,使得 query(查询目标)和 gallery(图像库)之间更好地匹配。
然后,他们将所提出的方法应用于重新识别模型,期望获得更具有风格鲁棒性的深度特征用于查询。

团队在广泛使用的基准数据集上进行了大量的实验来评估所提框架的性能,实验结果证实了所提模型的优越性。
解决行人遮挡问题
旷视研究院在 CVPR 2020 中发表的论文《High-Order Information Matters: Learning Relation and Topology for Occluded Person Re-Identification》中,解决了该领域中,经常出现也最具挑战性的问题——行人遮挡问题。

论文地址:https://arxiv.org/pdf/2003.08177.pdf
该论文中,旷视研究院提出的框架,包括:
一个一阶语义模块(S),它可以取人体关键点区域的语义特征;
一个高阶关系模块(R),它能对不同语义局部特征之间的关系信息进行建模;
一个高阶人类拓扑模块(T),它可以学习到鲁棒的对齐能力,并预测两幅图像之间的相似性。
这三个模块以端到端的方式进行联合训练。

论文中对高阶信息和拓扑关系的说明
此前,我们还曾在史上最火 ECCV 已开幕,这些论文都太有意思了中介绍了,由华中科技大学,中山大学,腾讯优图实验室发表的论文《请别打扰我:在其他行人干扰下的行人重识别》,该论文提出的方法,解决了拥挤场景中、背景行人干扰或人体遮挡造成的错误检索结果问题。感兴趣的同学,可以再次回顾。

热点技术,尚存难点
目前,行人重识别仍然面临不小的挑战,包括数据、效率、性能等方面。
拿数据方面来说,不同场景(如室内和室外)、不同季节风格的变换、不同时间(如白天和晚上)光线差异等,获取的视频数据都会有很大差异,这些都是行人重识别的干扰因素。这些干扰因素不仅影响模型识别准确度,也会影响识别效率。

非可控环境下行人识别存在的难点
因此,尽管在现有应有案例中,我们看到行人重识别甚至已经超过了人类的分辨能力,但仍然有很多问题需要解决。


更多精彩推荐
微信群总有人发广告?用Python写一个自动化机器人消灭他
Cognitive Inference:认知推理下的常识知识库资源、常识推理测试评估与中文实践项目索引
滴滴AI Labs负责人叶杰平离职!CTO 张博接任
一年翻 3 倍,装机量 6 亿台的物联网操作系统又放大招!
谷歌软件工程师薪资百万,大厂薪资有多高?