Spark DAG之SubmitStage
文章目录
- 概要
- 1. 前提
- 2. SubmitStage()
- 2.1 提交流程
- 2.2 提交流程图
- 2.3 提交结果说明
- 3. 提交WaitingStages
- 3.1 第一种提交途径
- 3.2 第二种提交途径
- 3.3 提交WaitingStages的效果
- 总结
- 致谢
- 附录
概要
介绍提交Stage的流程,继续沿用上文Spark DAG之划分Stage中的例子
1. 前提
上篇博客Spark DAG之划分Stage介绍了划分Stage的流程,举的例子最后生成的Stage如下

划分Stage阶段完成后,DAGScheduler的handleJobSubmitted方法提交Stage,如下:
![]()
![]()
查看此SubmitStage()方法:
2. SubmitStage()
2.1 提交流程
/** 提交阶段,但首先递归提交所有丢失的父母。 */
- 根据
JobId,判断Stage所属的Job是否处于Active状态 - 判断
Stage的状态,是否为waiting\running\failed之一 ,都不是,那么说明此Stage是可以提交的:
2.1 获得丢失的父Stage的信息
2.2 如果父Stage都可用,那么直接将当前要提交的Stage转换为Task,并提交
2.3 如果存在不可用的父Stage,提交不可用的父Stage。既然目前还有父Stage不可用,那么就需要将当前Stage加入等待调度的Stage队列
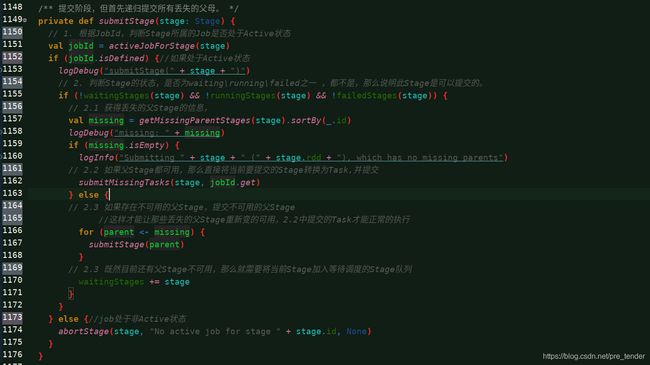
2.1中的获取丢失的父Stage信息用到的getMissingParentStages()方法:
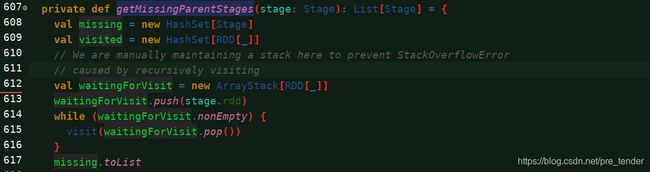
关键的自定义内部方法visit():
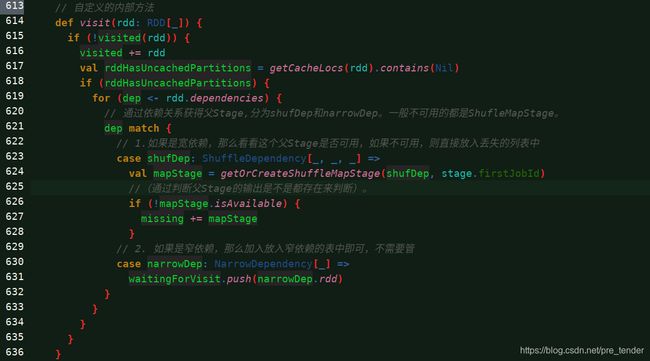
对于宽依赖的ShuffleMapStage,如何判断其可用?
- 如上图,调用ShuffleMapStage的isAvailable方法判断。每当执行完一个Task会对变量_numAvailableOutputs加1,直至所有Task执行完,_numAvailableOutputs等于分区数。
- 也就是上上图中写的,通过判断父Stage的输出是不是都存在来判断

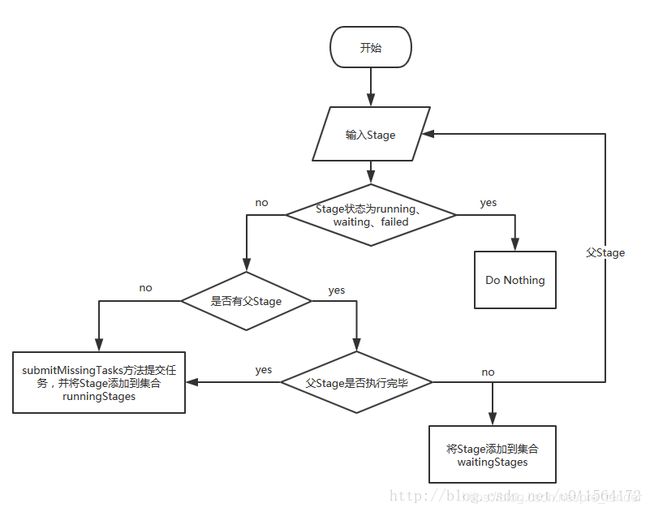
2.2 提交流程图
如下:
(图中说的父Stage是指,被查询出来的丢失的父stage)
2.3 提交结果说明
以前面切分的Stage为例,执行submitStage(finalStage),此时finalStage的值为ResultStage 4(参考第一幅图),submitStage方法执行完状态如下
| 集合 | 包含的Stage | 状态 |
|---|---|---|
runningStages |
ShuffleMapStage 0、ShuffleMapStage 2 | 转为ShuffleMapTask,发送给Executor执行 |
waitingStages |
ShuffleMapStage 1、ShuffleMapStage 3、ResultStage 4 | 等待 |
failedStages |
空 |
3. 提交WaitingStages
在上面的表中,我们看到了,由于各个Stage之间存在依赖关系,而执行速度又各不相同,因此会存在很多WaitingStages。那么他们在何时被提交呢?
这里我们就不得不重新提一下Stage提交细节了:
首先我们需要明确的是:
- DAG的生成是在Stage执行之前,也就是说,在第一批的Stage执行之前,其实后面的Stage的数量、依赖关系等等都已经确定好了。不会在Stage的提交、执行过程中修改。因此对那些父Stage还不可用的Stage来说,它就处于WaitingStage的队列中了。
- 处于WaitingStages队列中的Stage需要被提交:当前Stage提交时即提交子Stage、等待当前Stage执行完所有Task再提交子Stage
因此我们可以得到以下两种WaitingStages提交途径:
3.1 第一种提交途径
- 第一批Stage被提交,并形成TaskSet提交到不同的Executor上去执行
- 当这些Tasks都执行完毕之后,也就是在submitMissingTasks()方法的最后,会检查这些Task,如果都执行完成了,那么就会调用
submitWaitingChildStages(stage),去从WaitingStages列表中找出当前Stage的子Stag,使用SubmitStage将他们提交。(SubmitStage中,对于可提交的(有些Stage存在多个父Stage),就会去提交,否则重新加入WaitingStages队列)(见上一节) - 循环第二步。
这里,submitMissingTasks()方法,我们放在另外一篇文章中去讲。下面说说它里面,Task都执行完毕之后,调用的submitWaitingChildStages()方法。
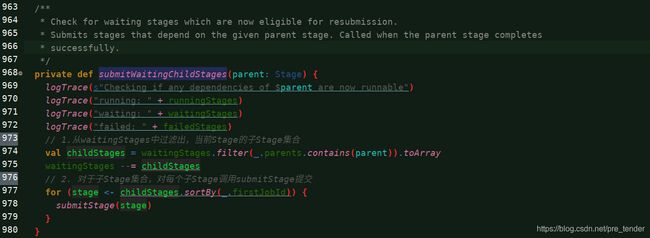
- 从waitingStages中过滤出,当前Stage的子Stage集合
- 对于子Stage集合,对每个子Stage调用submitStage提交
3.2 第二种提交途径
由于Executor会返回消息,因此当DAGScheduler使用doOnReceive接收到了来自Executor的Completion消息后,就会去调用handleTaskCompletion()判断返回消息的Event类型,如果是ShuffleMapTask类型,那么,就通过一系列操作判断等等,最终调用submitWaitingChildStages()方法。
doOnReceive()中:
![]()
handleTaskCompletion()中,判断CompletionEvent.reason(监听到的事件发生的原因):

3.3 提交WaitingStages的效果
对于前面提到的几个Stage,经过第一次submitStage之后,集合中的元素如下:
| 种类 | 内容 |
|---|---|
waitingStages |
ShuffleMapStage 1、ShuffleMapStage 3、ResultStage 4 |
runningStages |
ShuffleMapStage 0、ShuffleMapStage 2 |
submitWaitingStages之后:假设只执行完成了ShuffleMapStage0,ShuffleMapStage2则没有,那么根据父子关系可知,
- ShuffleMapStage 2的子stage–ShuffleMapStage3是依旧处于waitingStages中
- ShuffleMapStage 1 则得益于ShuffleMapStage 0 执行完成了,原本处于waitingStages中,现在可以去提交执行,处于runningStages中
| 种类 | 内容 |
|---|---|
waitingStages |
ShuffleMapStage 3、ResultStage 4 |
runningStages |
ShuffleMapStage 1、ShuffleMapStage 2 |
Completed |
ShuffleMapStage 0 |
总结
介绍了SubmitStage的提交Stage的方式,并介绍了submitWaitingStages的两种方式。
致谢
- Spark DAG之SubmitStage
附录
--------------------DAGScheduler.scala submitStage()------------------------------
/** 提交阶段,但首先递归提交所有丢失的父母。 */
private def submitStage(stage: Stage) {
// 1. 根据JobId,判断Stage所属的Job是否处于Active状态
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {//如果处于Active状态
logDebug("submitStage(" + stage + ")")
// 2. 判断Stage的状态,是否为waiting\running\failed之一 ,都不是,那么说明此Stage是可以提交的。
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
// 2.1 获得丢失的父Stage的信息,
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
// 2.2 如果父Stage都可用,那么直接将当前要提交的Stage转换为Task,并提交
submitMissingTasks(stage, jobId.get)
} else {
// 2.3 如果存在不可用的父Stage,提交不可用的父Stage
//这样才能让那些丢失的父Stage重新变的可用,2.2中提交的Task才能正常的执行
for (parent <- missing) {
submitStage(parent)
}
// 2.3 既然目前还有父Stage不可用,那么就需要将当前Stage加入等待调度的Stage队列
waitingStages += stage
}
}
} else {//job处于非Active状态
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
--------------------getMissingParentStages()-------------------------------
private def getMissingParentStages(stage: Stage): List[Stage] = {
val missing = new HashSet[Stage]
val visited = new HashSet[RDD[_]]
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
val waitingForVisit = new ArrayStack[RDD[_]]
// 自定义的内部方法
def visit(rdd: RDD[_]) {
if (!visited(rdd)) {
visited += rdd
val rddHasUncachedPartitions = getCacheLocs(rdd).contains(Nil)
if (rddHasUncachedPartitions) {
for (dep <- rdd.dependencies) {
// 通过依赖关系获得父Stage,分为shufDep和narrowDep。一般不可用的都是ShufleMapStage。
dep match {
// 1.如果是宽依赖,那么看看这个父Stage是否可用,如果不可用,则直接放入丢失的列表中
case shufDep: ShuffleDependency[_, _, _] =>
val mapStage = getOrCreateShuffleMapStage(shufDep, stage.firstJobId)
//(通过判断父Stage的输出是不是都存在来判断)。
if (!mapStage.isAvailable) {
missing += mapStage
}
// 2. 如果是窄依赖,那么加入放入窄依赖的表中即可,不需要管
case narrowDep: NarrowDependency[_] =>
waitingForVisit.push(narrowDep.rdd)
}
}
}
}
}
waitingForVisit.push(stage.rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
missing.toList
}
-------------------------doOnReceive()----------------------
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case completion: CompletionEvent =>
dagScheduler.handleTaskCompletion(completion)
}
------------------------------handleTaskCompletion()-------------------
case smt: ShuffleMapTask =>
val shuffleStage = stage.asInstanceOf[ShuffleMapStage]
shuffleStage.pendingPartitions -= task.partitionId
val status = event.result.asInstanceOf[MapStatus]
val execId = status.location.executorId
logDebug("ShuffleMapTask finished on " + execId)
if (failedEpoch.contains(execId) && smt.epoch <= failedEpoch(execId)) {
logInfo(s"Ignoring possibly bogus $smt completion from executor $execId")
} else {
// The epoch of the task is acceptable (i.e., the task was launched after the most
// recent failure we're aware of for the executor), so mark the task's output as
// available.
mapOutputTracker.registerMapOutput(
shuffleStage.shuffleDep.shuffleId, smt.partitionId, status)
}
if (runningStages.contains(shuffleStage) && shuffleStage.pendingPartitions.isEmpty) {
markStageAsFinished(shuffleStage)
logInfo("looking for newly runnable stages")
logInfo("running: " + runningStages)
logInfo("waiting: " + waitingStages)
logInfo("failed: " + failedStages)
// This call to increment the epoch may not be strictly necessary, but it is retained
// for now in order to minimize the changes in behavior from an earlier version of the
// code. This existing behavior of always incrementing the epoch following any
// successful shuffle map stage completion may have benefits by causing unneeded
// cached map outputs to be cleaned up earlier on executors. In the future we can
// consider removing this call, but this will require some extra investigation.
// See https://github.com/apache/spark/pull/17955/files#r117385673 for more details.
mapOutputTracker.incrementEpoch()
clearCacheLocs()
if (!shuffleStage.isAvailable) {//如果shuffleStage没输出,那么说明失败了,重新提交任务
// Some tasks had failed; let's resubmit this shuffleStage.
// TODO: Lower-level scheduler should also deal with this
logInfo("Resubmitting " + shuffleStage + " (" + shuffleStage.name +
") because some of its tasks had failed: " +
shuffleStage.findMissingPartitions().mkString(", "))
submitStage(shuffleStage)
} else {//如果没有,那么结束此Stage,并启动子Stage的提交
markMapStageJobsAsFinished(shuffleStage)
submitWaitingChildStages(shuffleStage)
}
}
}
--------------ShuffleMapStage.scala isAvailable()-----------------
/**
* 返回ShufleMapStage是否执行完毕
* 当全部partitions的shuffle outputs存在(即==numPartitions)则表示执行完毕
*/
def isAvailable: Boolean = numAvailableOutputs == numPartitions