pyspark学习(一)—pyspark的安装与基础语法
pyspark学习(一)
原创 Starry ChallengeHub 公众号

一 Pysaprk的安装
最近想学pyspark,于是想起了要更这个系列,由于本人也是不是特别熟悉,如果有什么错误的地方希望大家多多见谅,要是指正的话那就更好了。条件简陋,只有一台笔记本,于是该系列应该全部都是在本地运行了。首先,pyspark的安装,单机版的Pyspark安装起来也十分简单。
1pip install pyspark
如果出现错误可能是pip版本原因,可以输入以下命令升级pip。
1python -m pip install --upgrade pip
如果还是不可以安装的话,可以从官网下载源文件。然后从文件地址下面进入命令行:

然后运行:

至此Pyspark就安装好了,检查是否成功可以进入python后import pyspark

二:pyspark的简单语法
1:用pyspark建立一个DataFrame
下面就开始让我们来运行一个Pyspark程序吧,pyspark的基础语法与Pandas十分相似,熟悉pandas的话学习起来会很快,废话不多说,让我们开始吧。
1from pyspark.sql import SparkSession
2spark=SparkSession.builder.appName('data_processing').getOrCreate()
3import pyspark.sql.functions as F
4from pyspark.sql.types import *
首先建立一个SparkSession Object,然后建立DataFra me,包含integer和string等5个字段。
1schema=StructType().add("user_id","string")
2.add("country","string").add("browser","string")
3.add("OS",'string').add("age", "integer")
4
5df=spark.createDataFrame([("A203",'India',"Chrome","WIN",33),
6 ("A201",'China',"Safari","MacOS",35),
7 ("A205",'UK',"Mozilla","Linux",25)],
8 schema=schema)
然后我们可以看一下df的数据结构和数据结构:

2:DataFrame的简单操作
- 2.1 关于Null值的处理与操作
首先建立一个含有Null值的df。pyspark中同样是采用fillna填充Null值
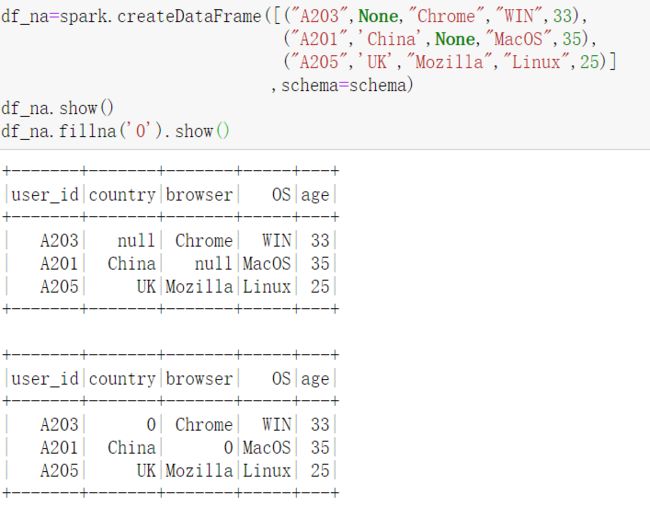
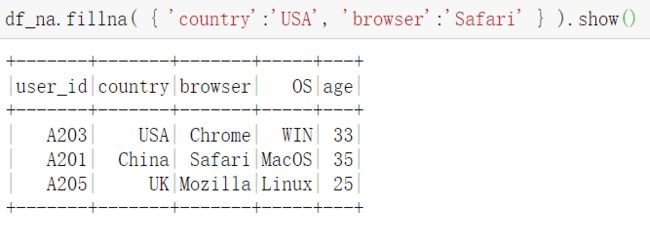
fillna同样支持对特定字段的填充。采用特定的值填充特定的字段。
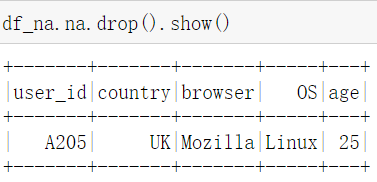
pyspark中同样支持drop操作,直接用na.drop操作的话,只要某个数据中任何一个字段有Null,那么就去除。
如果只需要删除某列为空的数据同样是可行的。

同样drop操作可以删除某个字段。

- 2.2 Select,Filter,Where字段。
Select,Filter,Where三个字段的功能是选择df的子集。介绍三个字段之前,首先来介绍下pyspark的数据读取。
pyspark同样是采用read读取本地文件。

Select字段是选择需要的列。

Filter是选择需要的行。顾名思义,过滤的意思。

Filter还支持连续的Filter。

采用where同样可以实现相同的效果。

本次的介绍就到这里了,主要介绍了本地版pyspark的安装和简单的操作。更多的内容之后在详细介绍。
END
-
欢迎扫码关注ChallengeHub学习交流群,关注公众号:ChallengeHub

- 或者添加以下成员的微信,进入微信群:

