LeetCode 黑名单中随机数(图解)
给定一个包含 [0,n ) 中独特的整数的黑名单 B,写一个函数从 [ 0,n ) 中返回一个不在 B 中的随机整数。
对它进行优化使其尽量少调用系统方法 Math.random() 。
提示:
1 <= N <= 1000000000
0 <= B.length < min(100000, N)
[0, N) 不包含 N,详细参见 interval notation 。
示例 1:
输入:
["Solution","pick","pick","pick"]
[[1,[]],[],[],[]]
输出: [null,0,0,0]
示例 2:
输入:
["Solution","pick","pick","pick"]
[[2,[]],[],[],[]]
输出: [null,1,1,1]
示例 3:
输入:
["Solution","pick","pick","pick"]
[[3,[1]],[],[],[]]
Output: [null,0,0,2]
示例 4:
输入:
["Solution","pick","pick","pick"]
[[4,[2]],[],[],[]]
输出: [null,1,3,1]
输入语法说明:
输入是两个列表:调用成员函数名和调用的参数。Solution的构造函数有两个参数,N 和黑名单 B。pick 没有参数,输入参数是一个列表,即使参数为空,也会输入一个 [] 空列表。
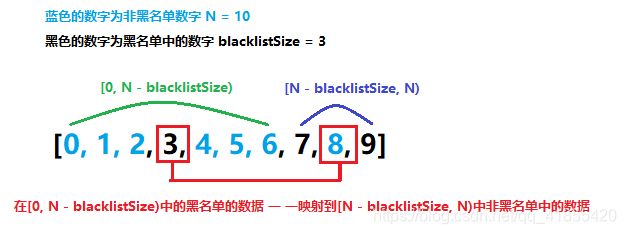
思路分析: 如果我们使用rand产生[0, N)的随机数,需要剔除黑名单中的元素。如果我们使用rand产生[0, N - blacklistSize)中的随机数(blacklistSize为黑名单的大小),如果黑名单中有一部分数据出现在[0, N - blacklistSize)中,则必定会有相同数量的非黑名单数字出现在[N - blacklistSize, N)中,我们只要将在[0, N - blacklistSize)中的黑名单的数据一一映射到[N - blacklistSize, N)中非黑名单中的数据即可。
class Solution {
public:
int nowSize;//修改后的N
unordered_map<int, int> hashMap;//映射hash表
Solution(int N, vector<int>& blacklist) {
int blacklistSize = blacklist.size();
nowSize = N - blacklistSize;
int startNum = nowSize;//扫描在[N - blacklistSize, N)中非黑名单中的数据
set<int> mySet(blacklist.begin(), blacklist.end());
auto it = mySet.begin();//扫描黑名单中在[0, N - blacklistSize)的数据
while (it != mySet.end() && *it < nowSize) {
while (mySet.find(startNum) != mySet.end()) {
++startNum;
}
//将在[0, N - blacklistSize)中的黑名单的数据一一映射到[N - blacklistSize, N)中非黑名单中的数据
hashMap[*(it++)] = startNum++;
}
}
int pick() {
int randNum = rand() % nowSize;//随机生成[0, N - blacklistSize)
if (hashMap.count(randNum)) {
//如果randNum在hash表中,说明它是黑名单中的数据,需要修改为它映射的数据
return hashMap[randNum];
}
else {
//否则直接返回
return randNum;
}
}
};
/**
* Your Solution object will be instantiated and called as such:
* Solution* obj = new Solution(N, blacklist);
* int param_1 = obj->pick();
*/
