Spark源码系列之Spark内核——Job提交
在介绍Job提交之前,我们先看下Job提交的过程:
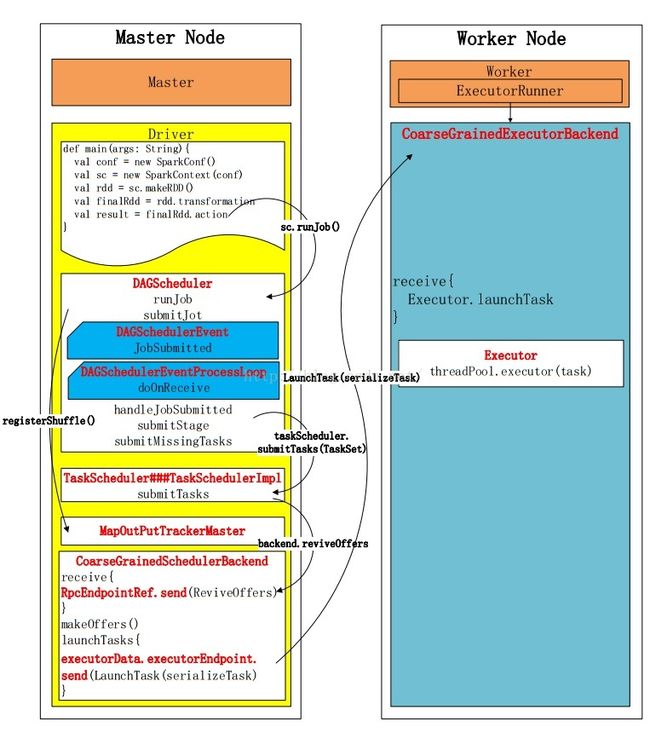
看完上图之后,大家应该会有一个比较直观的了解,同时也便于对整个流程的把握。
DAGScheduler
在RDD触发Action算子时,会调用sc.runJob(),以count算子为例:
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum在SparkContext的runJob()中,会调用DAGScheduler.runJob()(由于源代码比较多,我多会有省略的形式,只贴出关键部分的代码):
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
…………
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()
}
DAGScheduler在SparkContext中被创建,并通过调用runJob()函数启动。然后runJob()函数,调用submitJob()对Job的执行进行判断。
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
val start = System.nanoTime
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
…………
}
submitJob()会对Job的执行情况用模式匹配进行判断,Job的执行情况放在DAGSchedulerEvent中。然后,会用DAGSchedulerEventProcessLoop根据Job执行情况进行选择性处理。
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
}
DAGSchedulerEventProcessLoop根据接收的event进行选择处理,当event是JobSubmitted时,调用DAGScheduler的handleJobSubmitted()函数。
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
…………
}
在DAGScheduler的handleJobSubmitted()函数中,根据finalRDD计算出finalStage,并把finalStage交给submitStage()函数处理。
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
if (finalStage != null) {
val job = new ActiveJob(jobId, finalStage, func, partitions, callSite, listener, properties)
…………
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.resultOfJob = Some(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
submitStage(finalStage)
}
submitWaitingStages()
}
DAGScheduler的submitStage()函数会根据finalStage,进行回溯解析DAG图。但是,第一次迭代地提交一些missing parent stage。
/** Submits stage, but first recursively submits any missing parents. */
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
为了得到missing parent stage,submitStage()函数会调用submitMissingTasks()函数。在submitMissingTasks()函数中,会把解析得到的tasks包装成TaskSet,提交给TaskScheduler。
private def submitMissingTasks(stage: Stage, jobId: Int) {
…………
if (tasks.size > 0) {
stage.pendingTasks ++= tasks
logDebug("New pending tasks: " + stage.pendingTasks)
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, stage.firstJobId, properties))
stage.latestInfo.submissionTime = Some(clock.getTimeMillis())
} else {
markStageAsFinished(stage, None)
val debugString = stage match {
case stage: ShuffleMapStage =>
s"Stage ${stage} is actually done; " +
s"(available: ${stage.isAvailable}," +
s"available outputs: ${stage.numAvailableOutputs}," +
s"partitions: ${stage.numPartitions})"
case stage : ResultStage =>
s"Stage ${stage} is actually done; (partitions: ${stage.numPartitions})"
}
logDebug(debugString)
}
}
TaskScheduler
TaskScheduler的实现类TaskSchedulerImple的submitTasks()函数,会把接收到的TaskSet集合发到Worker节点上。
override def submitTasks(taskSet: TaskSet) {
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
this.synchronized {
val manager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
stageTaskSets(taskSet.stageAttemptId) = manager
val conflictingTaskSet = stageTaskSets.exists { case (_, ts) =>
ts.taskSet != taskSet && !ts.isZombie
}
if (conflictingTaskSet) {
throw new IllegalStateException(s"more than one active taskSet for stage $stage:" +
s" ${stageTaskSets.toSeq.map{_._2.taskSet.id}.mkString(",")}")
}
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
if (!isLocal && !hasReceivedTask) {
starvationTimer.scheduleAtFixedRate(new TimerTask() {
override def run() {
if (!hasLaunchedTask) {
logWarning("Initial job has not accepted any resources; " +
"check your cluster UI to ensure that workers are registered " +
"and have sufficient resources")
} else {
this.cancel()
}
}
}, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS)
}
hasReceivedTask = true
}
backend.reviveOffers()
}
Worker Node
CoarseGrainedSchedulerBackend的receive()函数,会根据接收的信息类别选择处理,信息类别都放在CoarseGrainedClusterMessage里。当接收信息类别是ReviveOffers时,调用makeOffers()函数。
override def receive: PartialFunction[Any, Unit] = {
…………
case ReviveOffers =>
makeOffers()
…………
}
CoarseGrainedSchedulerBackend的makeOffers()会在所有的Executor上,制造fake resource offers。然后启动Tasks。
// Make fake resource offers on all executors
private def makeOffers() {
// Filter out executors under killing
val activeExecutors = executorDataMap.filterKeys(!executorsPendingToRemove.contains(_))
val workOffers = activeExecutors.map { case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toSeq
launchTasks(scheduler.resourceOffers(workOffers))
}
CoarseGrainedSchedulerBackend的launchTasks()启动所有的Tasks。
// Launch tasks returned by a set of resource offers
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
val serializedTask = ser.serialize(task)
if (serializedTask.limit >= akkaFrameSize - AkkaUtils.reservedSizeBytes) {
scheduler.taskIdToTaskSetManager.get(task.taskId).foreach { taskSetMgr =>
try {
var msg = "Serialized task %s:%d was %d bytes, which exceeds max allowed: " +
"spark.akka.frameSize (%d bytes) - reserved (%d bytes). Consider increasing " +
"spark.akka.frameSize or using broadcast variables for large values."
msg = msg.format(task.taskId, task.index, serializedTask.limit, akkaFrameSize,
AkkaUtils.reservedSizeBytes)
taskSetMgr.abort(msg)
} catch {
case e: Exception => logError("Exception in error callback", e)
}
}
}
else {
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}
当CoarseGrainedExecutorBackend收到Task执行情况时,会选择性处理。当Task执行情况是LaunchTasks时,调用Executor.launchTask()开始启动Task。
override def receive: PartialFunction[Any, Unit] = {
…………
case LaunchTask(data) =>
if (executor == null) {
logError("Received LaunchTask command but executor was null")
System.exit(1)
} else {
val taskDesc = ser.deserialize[TaskDescription](data.value)
logInfo("Got assigned task " + taskDesc.taskId)
executor.launchTask(this, taskId = taskDesc.taskId, attemptNumber = taskDesc.attemptNumber,
taskDesc.name, taskDesc.serializedTask)
}
…………
}
Executor将Task包装成TaskRunner,并从线程池中抽取一个空闲线程运行Task。一个CoarseGrainedExecutorBackend进行有且仅有一个Executor对象。
def launchTask(
context: ExecutorBackend,
taskId: Long,
attemptNumber: Int,
taskName: String,
serializedTask: ByteBuffer): Unit = {
val tr = new TaskRunner(context, taskId = taskId, attemptNumber = attemptNumber, taskName,
serializedTask)
runningTasks.put(taskId, tr)
threadPool.execute(tr)
}
PS:欢迎大家指出其中落下的部分,因为我觉得有些细节,我还没考虑全面。