EF大批量插入数据的性能调优思路
最近碰到一个需求:需要从XML格式的文本中解析数据,并写入数据库表中。遇到这种情况自然是EF+WinForm开干,写完程序之后跑了一下,发现速度有点慢,因为数据急着要,所以就这么拿去用了。最后实际运行的速度大概是2W条数据10分钟左右。
后面仔细想了想,性能不应该这么低才对。首先想到会不会是多线程的问题,于是看了下资源监视器,所有核心都是在跑的。
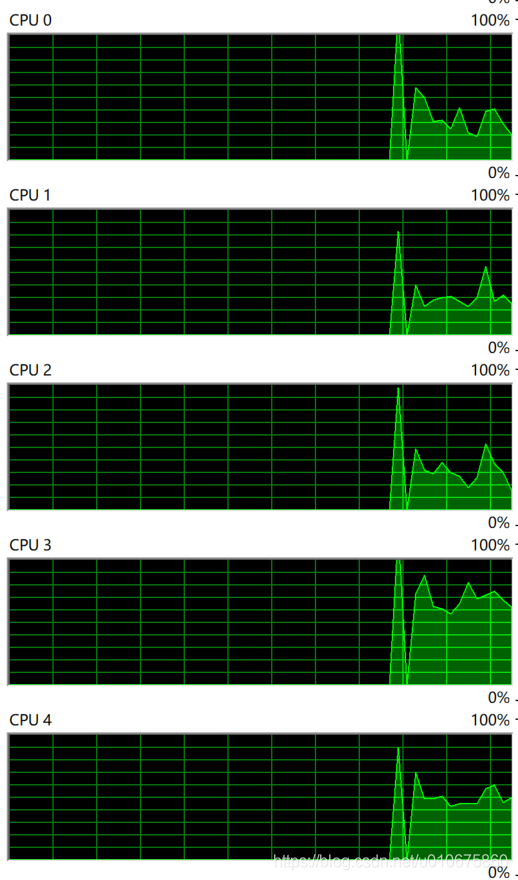
(程序运行时的CPU占用)
然后在代码里加Stopwatch,分析代码运行时间发现解析(并写入)1000条数据的时间是25秒,并且程序运行到后面速度会越来越慢。
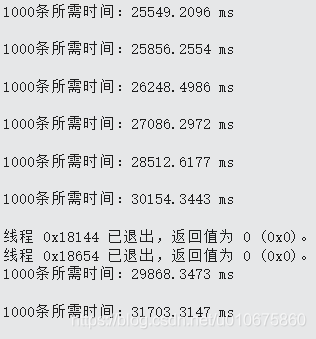
(每1000条数据执行时间,到最后时间翻了一倍多)
此时的主要代码如下,可以看到性能瓶颈无非就是XML解析和数据保存。但是加断点执行两次感觉XML解析没什么问题,于是打算从数据保存部分下刀,把DbContext改成直接执行SQL。
foreach(XmlNode p in nodes)
{
JTCY j = new JTCY
{
ID = Guid.Parse(p.Attributes["ID"].InnerText),
XZQHMC = a.LandLocated.Replace("xxx", ""),
HZZJHM = a.Number,
HZXM = a.Name,
XM = p.Attributes["Name"].InnerText,
XB = p.Attributes["Gender"].InnerText == "Male" ? "男" : "女",
YHZGX = p.Attributes["Relationship"].InnerText,
CSRQ = p.Attributes["Birthday"].InnerText,
SFZH = p.Attributes["ICN"].InnerText,
};
DB.JTCY.Add(j);
i++;
if(i%1000==0)
{
System.Diagnostics.Debug.WriteLine("1000条所需时间:{0} ms\n", Runtime.Elapsed.TotalMilliseconds);
Runtime.Restart();
DB.SaveChanges();
}
label1.Text = i.ToString();
Application.DoEvents();
}改完的代码如下。
foreach(XmlNode p in nodes)
{
sql += string.Format(insert,
p.Attributes["ID"].InnerText, a.LandLocated.Replace("xxx", ""), a.Number, a.Name, p.Attributes["Name"].InnerText,
p.Attributes["Gender"].InnerText == "Male" ? "男" : "女", p.Attributes["Relationship"].InnerText, p.Attributes["Birthday"].InnerText,
p.Attributes["ICN"].InnerText
);
i++;
if(i%1000==0)
{
DB.Database.ExecuteSqlCommand(sql);
sql = "";
System.Diagnostics.Debug.WriteLine("1000条所需时间:{0} ms\n", Runtime.Elapsed.TotalMilliseconds);
Runtime.Restart();
}
label1.Text = i.ToString();
Application.DoEvents();
}
执行结果如下。
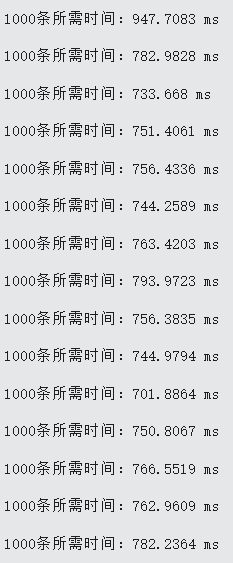
可以看到运行速度提高了约4倍(由于不存在程序效率下降的问题,实际大概提高了6-7倍,如果把每1000条保存一次的逻辑去掉还会更快)
从这次事件中学到几件事:
1:大批量操作数据时尽量避免使用重量级ORM(安利一发Dapper)
2:代码之间的差距比看起来大得多