联邦元学习(Federated meta learning)学习笔记
最近在研究联邦学习,又转到个性化领域,研究了联邦元学习,打算把最近学的东西总结一下。感觉元学习对于我这种基础不扎实的萌新来说有点难,到目前也才搞懂了MAML/(ㄒoㄒ)/~~
联邦学习(FL)
联邦学习(federated learning),只需要记住一句话:数据不动模型动,服务器将模型参数发给用户,用户本地训练完后返回更新后的参数,如此重复若干轮次。
元学习
可以看李宏毅老师的视频讲解,本文配图均来自该视频
引用论文MAML中的一句话介绍元学习:
The goal of meta-learning is to train a model on a variety of learning tasks, such that it can solve new learning tasks using only a small number of training samples.
元学习即“学会学习”,一般的机器学习是通过反复训练学会一个模型参数,元学习是学会如何得到模型参数,例如MAML通过一次梯度下降就知道了模型最佳初始参数是什么。元学习大致上可以分类为learning good weight initializations,meta-models that generate the parameters of other models 以及learning transferable optimizers。其中MAML属于第一类。MAML学习一个好的初始化权重,从而在新任务上实现fast adaptation

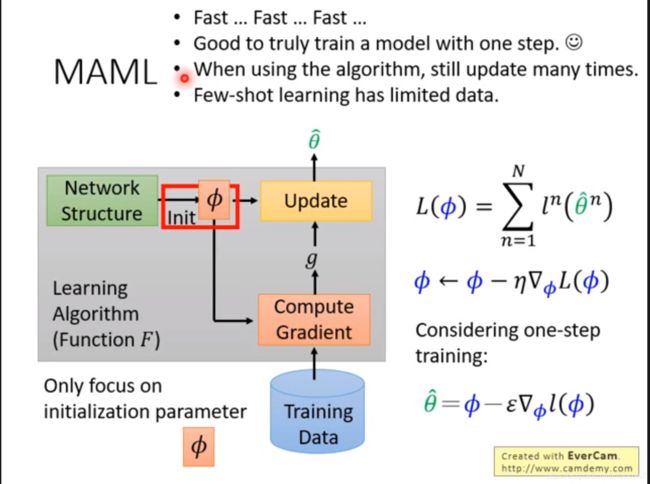
如上图,传统的机器学习中,模型的初始参数、模型结构、优化算法、学习率等等超参数都需要我们提前设置,每次训练模型都要调参。那我们能不能让机器学会自己调参呢,如果机器看一眼数据集就知道最佳的初始参数是多少,将省去很多计算步骤与样本,这就是MAML
MAML
MAML全称 模型无关元学习,Model-Agnostic Meta-Learning,可以用在监督学习、强化学习上,所以称为模型无关。但是我理解到的是,MAML如果用在分类问题上,那么模型结构必须都相同。它的思想是:
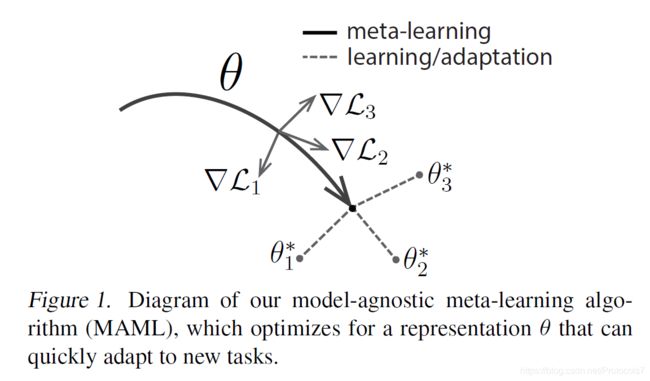
meta-learning过程,我们优化参数θ到某一位置。到了learning/adaption过程,我们的θ对task比较敏感,能很快更新到θ* 。
首先介绍task
一个task由干个train set和test set组成,每个set里都有若干个样本和标签,称为shot。task中的train set也称为support set,test set也称为query set。
很多task会被用在meta-train阶段,剩下的task会被用在meta-test阶段。
然后来看算法:

首先我们有MAML的参数θ,然后采样tasks,比如我们采样到Ti。损失函数定义为

。
第一步,meta-train:对损失函数进行一次梯度下降得到θ-hat,即初始θ在task Ti上得到的最终θ。
第二步,meta-test:我们用得到的θ-hat在testing tasks上测试,看效果如何,损失函数也就是
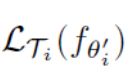
那我们现在需要优化这个函数,就再进行一次梯度下降,即第8步的计算。注意算法中第8步将所有task得到的θhat集中在一起进行梯度下降。
总的来说,总体目标是我有一个初始参数θ,meta-train阶段这个参数在不同的task上滚一遍得到最终参数θ-hat,meta-test阶段θ-hat在其他task上优化一下,使得误差最小。优化θ-hat就是优化θ,最终我们得到一个参数θ,在模型部署后,能很快在其他样本上泛化,得到一个比较好的初始参数θ-hat,只需要在本地结合小样本进行几步梯度下降就完成训练了。
最后强烈推荐这个视频https://www.youtube.com/watch?v=3z997JhL9Oo

如上图,MAML是在task n上做两次梯度下降,Φ0会往第二次的方向移动变为Φ1,接下来在task m上做两次梯度下降,Φ1又移动……而reptile的思路与这个很像,只不过移动的策略不同。
reptile

一张图看懂reptile:首先它会梯度下降多次,比如走到了θhat m,于是Φ0往θhat m的方向走一点,然后又从Φ1梯度下降很多次,走到θhat n,于是Φ1往θhat n的方向走一点,然后……依次循环。

如上图,可以看出reptile和MAML的区别走的方向不同,前者是多个向量的和(可以很多次梯度下降),后者只是g2的方向(MAML只进行两次梯度下降,但实际中可以多进行几次)。
reptile的论文指出,reptile的效果和MAML差不多,但是比pre-train肯定好很多。
联邦元学习(FML)
联邦元学习=联邦学习+元学习?基本可以这里理解。联邦元学习是指众多设备联合在一起,训练同一个meta-learner,这个learner由于见过很多样本了,泛化能力超强,再在设备上进行几步梯度下降即可完成训练。具体点 就是每个设备有自己的meta-learner,但是参数会在服务器聚合,就成为了大的、全局的mata-learner。下面回答两个问题:
- 为什么需要联邦学习
考虑IoT背景,每个设备的数据量非常有限,需要结合群众的力量训练模型,这样设备在遇到其他样本时也能识别的出来(如图像分类任务)。另外还能保护隐私 - 为什么需要元学习
FL训练出的全局模型,在每个设备上都一样,但是每个设备的数据异构性强(我的图片都是风景,你的图片都是动物),需要将模型个性化一下,使得它识别我自己的图片时准确率更高点,识别你的图片时准确率也会提高,而不是都很一般。那怎么做呢?个性化有很多方法,可以看我上一篇博客,元学习就是其中一种方法,大家集中力量学习一个元模型,元模型在本地生成个性化模型,这里我把本地设备看作是小样本学习,每个设备的类少,样本也少。
除了个性化以外,IoT设备算力、存储力弱,而MAML元模型在本地生成个性化模型时只需要几步梯度下降,和少量样本,非常合适。而迁移学习,可能需要在本地重新训练非常多epoch,这是某些IoT设备不能承受的。
我们需要这两把刀来解决问题,整个框架就叫联邦元学习FML。
再介绍联邦元学习:
联邦元学习是meta train 和meta test阶段都在设备本地,从而得到优化了的θ,发给服务器进行平均,如此重复若干轮次,看看华为诺亚方舟实验室的FML算法:

gu这个参数在服务器聚合,与FedAvg一样,本地训练与往常服务器集中训练一样,得到的参数发给服务器就行。可以说,FL是框架,Meta learning是肉体,这个肉体可以换成统计学习、强化学习、无监督学习……我们用ML来实现我们的任务,与用传统的SGD来实现任务没啥区别。
再来看一个MIT的FML算法(Personalized Federated Learning: A Meta-Learning
Approach),有没有发现跟上面的特别像?meta-train更新参数、meta-learning又更新参数,就是在一个设备上进行完整的MAML过程嘛,进行完后聚合参数,完全套用FL的框架~

但《IMPROVING FEDERATED LEARNING PERSONALIZATION
VIA MODEL AGNOSTIC META LEARNING》指出,reptile和FedAvg是一样的,如下图。我还没理解到这一层,先把图贴上来

总结
元学习还有很多种,reptile、FOMAML、metric meta learning,我不太熟,想先把MAML搞清楚。如下,除了以上提到的可以学习初始参数,还可以学习自动生成网络架构、如何更新参数……

FML也有很多算法,特别是MIT的那篇FML文章有超详细的数学公式推导,看了很多遍也没看懂,但总有一天会搞懂,及时更新在这篇博客里。
由于我刚入坑FML(师兄说这个只是表面上好看,实际上没那么厉害,但是我还是想自己试试),代码还没实现,等代码实现后也会一并更新在博客里。