模型无关元学习/Model-Agnostic Meta-Learning(MAML)源码解读
最近看了好久的MAML源代码,也学了TF,想写篇文章将MAML源码总结出来,揭开MAML的神秘面纱。
论文

摘要
We propose an algorithm for meta-learning that is model-agnostic, in the sense that it is compatible with any model trained with gradient descent and applicable to a variety of different learning problems, including classification, regression, and reinforcement learning. The goal of meta-learning is to train a model on a variety of learning tasks, such that it can solve new learning tasks using only a small number of training samples. In our approach, the parameters of the model are explicitly trained such that a small number of gradient steps with a small amount of training data from a new task will produce good generalization performance on that task. In effect, our method trains the model to be easy to fine-tune. We demonstrate that this approach leads to state-of-the-art performance on two fewshot image classification benchmarks, produces good results on few-shot regression, and accelerates fine-tuning for policy gradient reinforcement learning with neural network policies.
总结:MAML找到一个好的初始参数,而不是0,极大减少训练时间和样本数。
算法


如图,我们有初始参数θ,有3个task,每个task有最好的参数θ*。此时θ可以有3个梯度下降的方向,但是我们没有选择梯度下降,而是往这3个点共有的方向前进了一步。这样新得到的θ只需要几步就能达到其他任务的 θ*
源码
我找的源码并不是这篇论文给的源码,而是“dragen1860”根据官方源码实现的简易版源码,链接,可以看人家的highlight:
- adopted from cbfin’s official implementation with equivalent performance on mini-imagenet
- clean, tiny code style and very easy-to-follow from comments almost every lines
- faster and trivial improvements, eg. 0.335s per epoch comparing with 0.563s per epoch, saving up to 3.8 hours for total 60,000 training process
文件结构

meta-learn的算法流程
- 从main函数入口进去
- 设定参数
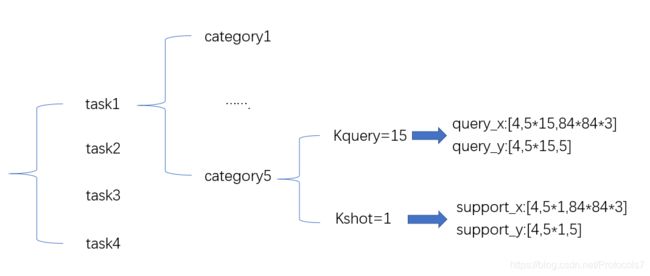
- nway:5,分类数,如猫的、狗的、马的……
- kshot:1,样本数
- kquery:15,?
- meta_batchsz:4,元学习中的batch数,即task的数目
- K:5,为了找到每个task最好的θ*,MAML可以进行K次梯度下降,并不是固定一次
- 生成数据(张量)
这里先回顾下 support set和query set:每个task就是传统机器学习的任务,包含了训练集和测试集,但是容易搞混,我们不这么叫了,叫support set和query set(那这两个set 设置多大比较好?),然后4个task作为meta-train用的,叫做train set,4个task作为meta-test用的,叫做test set
以下就是4个任务在meta-train阶段的support set和query set
# image_tensor: [4, 80, 84*84*3]
support_x = tf.slice(image_tensor, [0, 0, 0], [-1, nway * kshot, -1], name='support_x')
query_x = tf.slice(image_tensor, [0, nway * kshot, 0], [-1, -1, -1], name='query_x')
support_y = tf.slice(label_tensor, [0, 0, 0], [-1, nway * kshot, -1], name='support_y')
query_y = tf.slice(label_tensor, [0, nway * kshot, 0], [-1, -1, -1], name='query_y')
# support_x : [4, 1*5, 84*84*3]
# query_x : [4, 15*5, 84*84*3]
# support_y : [4, 5, 5]
# query_y : [4, 15*5, 5]
同样的方法构建meta-test阶段的两个set
# construct test tensors.
image_tensor, label_tensor = db.make_data_tensor(training=False)
support_x_test = tf.slice(image_tensor, [0, 0, 0], [-1, nway * kshot, -1], name='support_x_test')
query_x_test = tf.slice(image_tensor, [0, nway * kshot, 0], [-1, -1, -1], name='query_x_test')
support_y_test = tf.slice(label_tensor, [0, 0, 0], [-1, nway * kshot, -1], name='support_y_test')
query_y_test = tf.slice(label_tensor, [0, nway * kshot, 0], [-1, -1, -1], name='query_y_test')
最后结果,只画了一个train set 的task的内容,实际support_x中包含了4个task,另外5way中,support set必须和query set相同:

- 构建MAML模型,调用build方法(以下都在build方法里,第8步跳出)
#这里的参数如84用来做tensor的reshape,为什么是这个数我也不知道
model = MAML(84, 3, 5)
model.build(support_x, support_y, query_x, query_y, K, meta_batchsz, mode='train')
- 接下来我们就进入了build方法里:对每个task,调用meta_task算法
result = tf.map_fn(meta_task, elems=(support_xb, support_yb, query_xb, query_yb),dtype=out_dtype, parallel_iterations=meta_batchsz, name='map_fn')
这个meta_task算法对应算法中标红的一段,即找出每个task最佳的参数θi*:

- 再来看看meta_task算法中的细节,其实就是普通的前向推导-反向传播-更新参数的过程:

我们用supportx加上权值计算出梯度,梯度下降得到fast weight,用这个fast weight在query集上测试,得到query loss,然后迭代更新K次fast weight
注意,我图只写了一步梯度下降,实际代码中有K步梯度下降。每次在support set得到fast weight,都会在query set上算损失,得到query loss
- 出循环,进行第二次梯度下降
我们把这么多task在quert集上的loss取平均,针对query loss计算出梯度
# meta-train optim
optimizer = tf.train.AdamOptimizer(self.meta_lr, name='meta_optim')
# meta-train gradients, query_losses[-1] is the accumulated loss across over tasks.
gvs = optimizer.compute_gradients(self.query_losses[-1])
然后进行真正参数θ的梯度更新
# meta-train grads clipping
gvs = [(tf.clip_by_norm(grad, 10), var) for grad, var in gvs]
# update theta
self.meta_op = optimizer.apply_gradients(gvs)
这一步对应算法中标红的一段:

- 从build中跳出
即以上都是一行代码做的事情:
if training:
model.build(support_x, support_y, query_x, query_y, K, meta_batchsz, mode='train')
model.build(support_x_test, support_y_test, query_x_test, query_y_test, K, meta_batchsz, mode='eval')
else:
model.build(support_x_test, support_y_test, query_x_test, query_y_test, K + 5, meta_batchsz, mode='test')
接下来进入train()方法里,即600000个迭代,每个迭代完成如下功能
这里result数组我还没理解
# this is the main op
ops = [model.meta_op]
# add summary and print op
if iteration % 200 == 0:
ops.extend([model.summ_op,
model.query_losses[0], model.query_losses[-1],
model.query_accs[0], model.query_accs[-1]])
# run all ops
result = sess.run(ops)
# summary
if iteration % 200 == 0:
# summ_op
# tb.add_summary(result[1], iteration)
# query_losses[0]
prelosses.append(result[2])
# query_losses[-1]
postlosses.append(result[3])
# query_accs[0]
preaccs.append(result[4])
# query_accs[-1]
postaccs.append(result[5])
print(iteration, '\tloss:', np.mean(prelosses), '=>', np.mean(postlosses),
'\t\tacc:', np.mean(preaccs), '=>', np.mean(postaccs))
prelosses, postlosses, preaccs, postaccs = [], [], [], []
# evaluation
if iteration % 2000 == 0:
# DO NOT write as a = b = [], in that case a=b
# DO NOT use train variable as we have train func already.
acc1s, acc2s = [], []
# sample 20 times to get more accurate statistics.
for _ in range(200):
acc1, acc2 = sess.run([model.test_query_accs[0],
model.test_query_accs[-1]])
acc1s.append(acc1)
acc2s.append(acc2)
acc = np.mean(acc2s)
print('>>>>\t\tValidation accs: ', np.mean(acc1s), acc, 'best:', best_acc, '\t\t<<<<')
if acc - best_acc > 0.05 or acc > 0.4:
saver.save(sess, os.path.join('ckpt', 'mini.mdl'))
best_acc = acc
print('saved into ckpt:', acc)
saver.save(sess, os.path.join('ckpt', 'mini.mdl'))保存了模型参数,即得到了meta-learner,那我们就进入test步骤,看看这个learner是否真如作者摘要所说,能几步梯度下降+少量数据完成模型训练?
meta-test的算法流程
将θ在support上训练K+5次,得到θ*,在query上验证这个θ*好不好,因为support set 和query set中的类都相同。
ops = [model.test_support_acc]
ops.extend(model.test_query_accs)
result = sess.run(ops)
test_accs.append(result)
代码usage
readme中写的很清楚,但是我是在win10系统下的,有点不同,具体usage如下:
- 从作者给的链接中下载imagenet图片集,约几十万张图片,3G
- 修改proc_images.py文件,将其中python linux命令改成windows的
path = 'C:/Users/Administrator/Desktop/MAML-TensorFlow-master/miniimagenet/'
# Put in correct directory
for datatype in ['train', 'val', 'test']:
os.system('mkdir ' + datatype)
with open(datatype + '.csv', 'r') as f:
reader = csv.reader(f, delimiter=',')
last_label = ''
for i, row in enumerate(reader):
if i == 0: # skip the headers
continue
label = row[1]
image_name = row[0]
if label != last_label:
cur_dir = ''+datatype + '/' + label + '/'
if not os.path.exists(path + cur_dir):
os.mkdir(path + cur_dir)
last_label = label
print( path+image_name + ' ' + path+cur_dir)
#os.system('cpoy images/' + image_name + ' ' + cur_dir)
shutil.move(path+'images/'+image_name, path+cur_dir)
- 用aniconda配置环境:python3.6 TF1.15.0,conda activate激活
- 在新环境中,python main.py即可
- 结果:速度特别慢,用自己电脑的cpu几个小时的结果如下:

可以看出准确率逐步提升。
2020.8.27todo:
-
下一步等结果跑完后需要看看论文中实验部分与此结果的对应关系,
-
并且在test set上把图画出来。
-
另外再分析 test val这两个函数的内容。