并查集的应用
并查集的初级应用及进阶
一、精华
精华提炼1:
内容:并查集就是树的孩子表示法的应用。
解释:对于下图所示树,它的孩子表示法为:
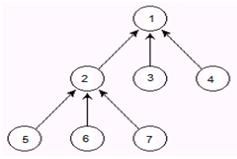
belg[5]=2, belg[6]=2, belg[7]=2;
belg[2]=1, belg[3]=1, belg[4]=1;
belg[1]=1(也可以=-1,只要能够识别它是根就可以)
精华提炼2:
内容:并查集的孩子父亲表示法中,每个节点与其父亲节点可以添加一个关系属性(必须具有可传递性)。
解释:比如,节点表示一个人,关系属性为一个人的性别。我们先用上图来解释这个关系属性的应用,在后文具体展开。我们可以这样定义,如果节点i和其父节点j性别相同(belg[i]=j),则kind[i]=false, 反之,kind[i]=true,那么如果我们知道kind[5]=true,kind[2]=false,那么5和2的父节点1的关系为kind[5]^kind[2]=true,即他们性别不同。
二、基础
基础1:集合表示
根据精华提炼1,我们把一颗树的节点集合看成以根节点命名的集合,那么上面的集合我们可以认为是集合1。
下图共有两个集合,分别为集合1,集合2。
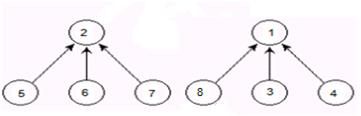
基础2:元素关系
如何判断元素关系呢?其实,我们只需找出元素对应的集合名称,然后判断名称是否相同即可。寻找集合名称代码如下:
int Find(int x)
{
while ( belg[x]!=x )
{
x = belg[x];
}
return x;
}
例如:对于基础1中左图,有belg[5]=2,belg[2]=2。那么5属于集合2。
现在我们已经解决了元素关系问题。
基础3:集合合并
集合如何合并呢?基础2中,我们已经可以找到元素对应集合的名称(即根节点标号),如果元素u、v(u、v不在同一集合)对应的集合名称为_u、_v,那么语句belg[_u]=_v什么意思呢?想到了吧?就是把集合_u与集合_v合并,并且以_v命名。
至此,通过基础部分我们知道了什么是并查集,通过精华提炼部分,我们知道了并查集的高级应用(精华提炼2)。
三、优化
虽然我们已经知道了基础的并查集,但是大家有没有想过简单用上面介绍的集合合并可能造成集合(树)的退化。比如对只有一个元素的集合1到集合n进行下述操作:把集合1合并到集合2,把集合2合并到集合3,…… 把集合n-1合并到集合n,那么生成一个含有n各元素的集合n,它的结构如下:
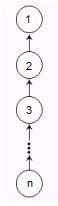
那么,每次判断n所属集合都要n次操作,即复杂度为O(n),这个耗费是不是必须的呢?其实不然。
优化1:路径压缩
对于上图退化的集合,它的表示是这样的:belg[n]=n-1, belg[n-1]=n-2, …… belg[2]=1, belg[1]=1;
既然上面元素都属于集合1,那么我们是不是可以这样做呢?belg[n]=1,belg[n-1]=1,……belg[2]=1,belg[1]=1;即把查找n所属集合时形成的路径上的点直接连到根节点上。可以的,因为这样操作只改变集合树的结构,并没有改变这个集合的元素。
关于路径压缩,可以在查找过程中实现,那么对于上述退化树,查找n第一次要n次操作,以后就只需一次操作。实现如下:
版本一:(递归)
int Find(int x)
{
return x==belg[x]?x:(belg[x]=Find(belg[x]));
}
代码很短,递归次数多时,不建议使用。
版本二:(迭代)
int Find(int x)
{
int _b, _x = x;
while ( belg[_x]!=_x )
{
_x = belg[_x];
}
while ( belg[x]!=x )
{
_b = belg[x];
belg[x] = _x;
x = _b;
}
return _x;
}
代码长点,但是少了递归过程,效率高点。
优化2:优化合并
合理的安排合并方式,可以防止退化,例如对于上述退化的例子,我们把元素少的集合合并到元素多的集合上。即集合2合并到集合1,集合3合并到集合1,……集合n合并到集合1,那么产生的树结构为:
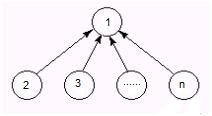
不过这个优化代价也很大的,因为要对开一个整型数组来记录集合元素个数,然后,再集合i和集合j合并时,通过判断集合中元素个数来实现合并:
int Union(int i,int j)
{
if ( sum[i]>sum[j] )
{
belg[j] = i;
}
else
{
belg[i] = j;
}
}
细心的读者,可能想到这个优化并不能完全避免集合退化,是的,所以我认为不必开辟数组浪费空间进行这个优化,完全可以随机法来由优化,比如:
int Union(int i,int j)
{
if ( rand()&1 )
{
belg[j] = i;
}
else
{
belg[i] = j;
}
}
通过随机值的奇偶性来决定怎么合并,平均效果是很好的。
上面详细讲了这么多理论性的东西,下面开始介绍应用:
四、应用
基础应用:
题目:
有n个人(1..n),如果i和j是亲戚,j和k是亲戚,那么j和k也是亲戚,题目给定n各人的m对亲戚关系,然后提出q各问题,问你某两个人是不是亲戚。
解答:
并查集简单应用,代码如下:
#include
usingnamespace std;
constint MAXN = 1010;
int belg[MAXN];
int main()
{
int i, u, v, n, m, q;
scanf("%d", &n);
for ( i=1; i<=n; belg[i]=i,++i );
scanf("%d", &m);
for ( i=1; i<=m; ++i )
{
scanf("%d%d", &u, &v);
u = Find(u); v = Find(v);
if ( u!=v ) { Union(u,v); }
}
scanf("%d", &q);
for ( i=1; i<=q; ++i )
{
scanf("%d%d", &u, &v);
u = Find(u); v = Find(v);
printf("%s/n", (u==v?"YES":"NO"));
}
return 0;
}
其中Find函数和Union函数参见上面的介绍。
高级应用:
题目:(HDU1829)
有n各小动物,它们只有异性之间才配对,同性之间不会配对。给定m对配对关系,问你是否能通过分配性别给n各小动物,使这m各配对关系成立,即不会出现同性之间配对。
解答:
这里我们使用在精华提炼二中提到的思路。
首先,我们必须明确两点:1.这里的属于同一个集合的元素表示他们的关系已经确定,比如元素i和元素j属于同一个集合,那么他们要么同性,要么异性,关系时确定的。2.同一个集合的树表示中,节点i和它的父亲节点j关系存储在kind[i]中。
同时,我们约定,如果节点i和节点j性别相同,则关系为false,否则关系为true。根节点root满足kind[root]=false,因为自己跟自己性别肯定相同(当然不包括人妖了哈^-^)。
关系的运算我们可以通过异或(提示1)来实现,如果i和j关系为r1,i和k关系为r2,那么j和k关系为r1^r2。
上面的分析已经足够我们处理这个题目了。下面给出代码:
#include
usingnamespace std;
constint MAXN = 2010;
int belg[MAXN];
bool kind[MAXN];
int Find(int x,bool &s);
int main()
{
int i, k, n, m;
int u, v, _u, _v, cas;
bool flag, su, sv;
scanf("%d", &cas);
for ( k=1; k<=cas; ++k )
{
scanf("%d%d", &n, &m);
for ( i=1; i<=n; ++i )
{
belg[i] = i;
kind[i] =false;
}
for ( i=1,flag=true; i<=m; ++i )
{
scanf("%d%d", &u, &v);
if ( flag )
{
_u = Find(u,su=false);
_v = Find(v,sv=false);
if ( _u==_v )
{
flag = su^sv;
}
else
{
belg[_u] = _v;
kind[_u] = !(su^sv);
}
}
}
printf("Scenario #%d:/n", k);
if ( flag )
{
printf("No suspicious bugs found!/n/n");
}
else
{
printf("Suspicious bugs found!/n/n");
}
}
return 0;
}
int Find(int x,bool &s)
{
int h;
if ( belg[x]==x )
{
h = x; s = false;
}
else
{
h = Find(belg[x],s);
belg[x] = h;
s = kind[x]^s;
kind[x] = s;
}
return h;
}
由于上述Find函数使用了递归所以比较耗时(1609毫秒,132KB),可以改为如下的迭代形式(671毫秒,0KB):
int Find(int x,bool &s)
{
int _x, h = x;
bool s1, s2;
while ( belg[h]!=h )
{
s = s^kind[h];
h = belg[h];
}
s1 = s;
while ( belg[x]!=x )
{
_x = belg[x];
belg[x] = h;
s2 = kind[x];
kind[x] = s1;
s1 = s1^s2;
x = _x;
}
return h;
}
提示1 . 异或:i和j异或就是:如果i和j相同则为false,否则为true,比如i=true,j=false,则i异或j为true。i=false,j=false,则i异或j为false。