hive主流的数据存储格式与压缩_对比实验
1.准备工作
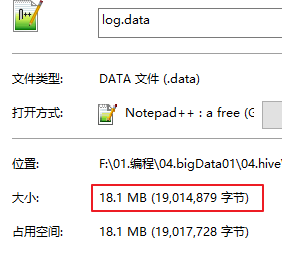
找一个测试文件 log.data 大小为18.1M
2.存储格式对比
2.1 默认的 TextFile
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
创建表,存储数据格式为TEXTFILE
create table log_text1 (
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE ;
向表中加载数据
load data local inpath '/waq/log.data' into table log_text1 ;
查看表中数据大小

hadoop fs -du -h /user/hive/warehouse/testgmall.db/log_text1;

2.2 ORC
一个orc文件可以分为若干个Stripe
一个stripe可以分为三个部分
indexData:某些列的索引数据
rowData :真正的数据存储
StripFooter:stripe的元数据信息
- Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引只是记录某行的各字段在Row Data中的offset。
- Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。
- Stripe Footer:存的是各个stripe的元数据信息
每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
创建表,存储数据格式为ORC
create table log_orc(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc ;
向表中加载数据
insert into table log_orc select * from log_text1;
查看表中数据大小

hadoop fs -du -h /user/hive/warehouse/testgmall.db/log_orc;
![]()
2.3 Parquet
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。
创建表,存储数据格式为parquet
create table log_parquet(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS PARQUET ;
向表中加载数据
insert into table log_parquet select * from log_text1;
查看表中数据大小

hadoop fs -du -h /user/hive/warehouse/testgmall.db/log_parquet;
![]()
2.4 存储文件的压缩比总结:
ORC > Parquet > textFile
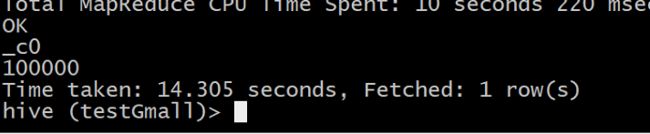
2.5 存储文件的查询速度测试第一遍:
TextFile
select count(*) from log_text1;

ORC
select count(*) from log_orc;

Parquet
select count(*) from log_parquet;
2.5 存储文件的查询速度测试第二遍:
TextFile
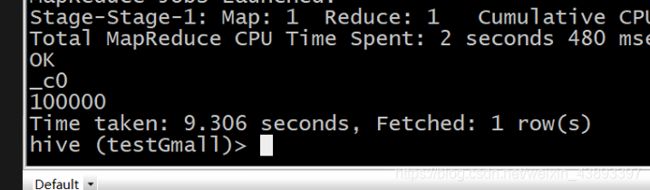
select count(*) from log_text1;
ORC

select count(*) from log_orc;
Parquet

select count(*) from log_parquet;
2.6 存储文件的查询速度测试第三遍:
TextFile

select count(*) from log_text1;
ORC

select count(*) from log_orc;
Parquet

select count(*) from log_parquet;
存储文件的查询速度总结:
TextFile > ORC > Parquet
3. 存储和压缩结合
3.1 非压缩的的ORC存储
创建一个非压缩的的ORC存储方式
create table log_orc_none(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc tblproperties ("orc.compress"="NONE");
插入数据
insert into table log_orc_none select * from log_text1;
查看插入后数据

hadoop fs -du -h /user/hive/warehouse/testgmall.db/log_orc_none;
![]()
3.2SNAPPY压缩的ORC存储
创建一个SNAPPY压缩的ORC存储方式
create table log_orc_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc tblproperties ("orc.compress"="SNAPPY");
插入数据
insert into table log_orc_snappy select * from log_text1;
查看插入后数据大小

hadoop fs -du -h /user/hive/warehouse/testgmall.db/log_orc_snappy;
![]()
默认创建的ORC存储方式,导入数据后的大小为:

比Snappy压缩的还小。原因是orc存储文件默认采用ZLIB压缩。比snappy压缩的小。
存储方式和压缩总结:
hive表的数据存储格式一般选择:orc或parquet。压缩方式一般选择snappy。