windows 安装 配置 hadoop2.7.2 spark2.2.3 初学入门
Hadoop
1.下载安装包,不赘述了。我解压路径为:E:\soft\hadoop-2.7.2
2.修改etc文件夹下的文件:
core-site.xml:
hadoop-env.cmd:
set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_144
我的JDK安装目录是C:\Program Files\Java\jdk1.8.0_144, 由于Program Files中间有空格,这里会报错,所以用PROGRA~1代替Program Files。如果你的jdk路径没有空格,那么就直接用你自己的路径就好。
hadoop-env.sh ,mapred-env.sh, yarn-env.sh:
export JAVA_HOME=C:\Program Files\Java\jdk1.8.0_144 这三个文件配置路径,这里可以不替换Program Files
hdfs-site.xml:
mapred-site.xml:
yarn-site.xml:
3.配置hadoop环境变量
添加环境变量HADOOP_HOME值为E:\soft\hadoop-2.7.2
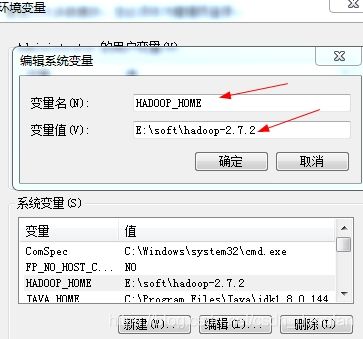
添加path 值为%HADOOP_HOME%\bin;
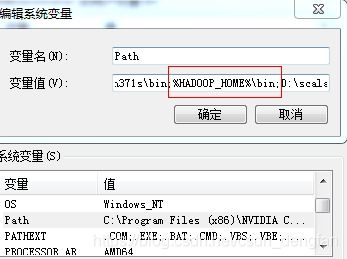
4.启动集群
打开cmd,进入hadoop的sbin目录,执行start-all.cmd命令启动集群(关闭集群是用stop-all.cmd命令)

回车启动,会启动4个窗口,启动成功。
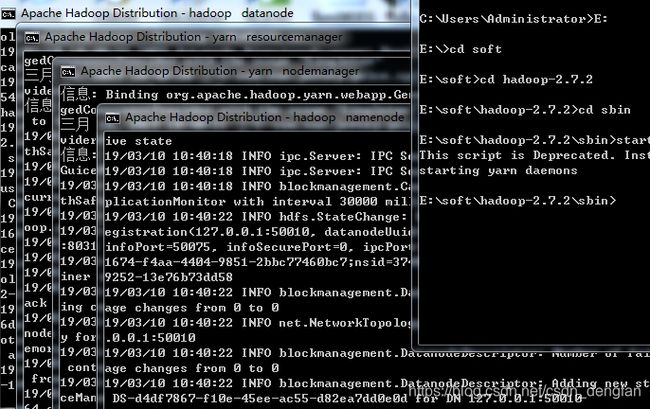
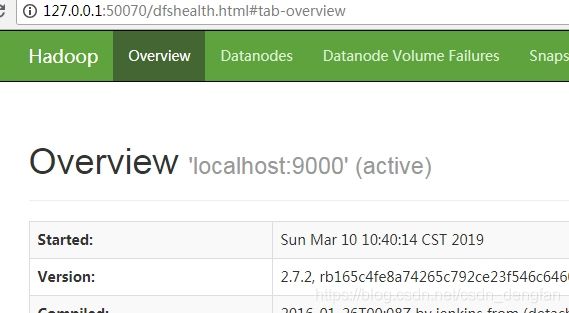
测试:
1.访问:http://127.0.0.1:50070
2.创建一个目录 /user/test
在cmd中,hdfs dfs -mkdir -p /user/test
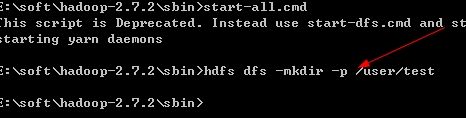
在浏览器上查看结果

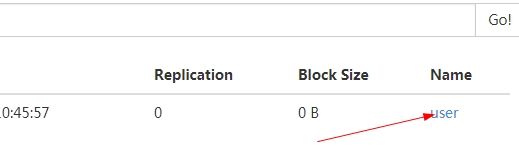
成功。
3. 上传文件到集群
随便准备一个文件test.txt,在cmd中运行拷贝命令: hdfs dfs -put D:\\test.txt /user/test

浏览器查看结果:

成功。
Spark
1. 下载spark包 http://spark.apache.org/downloads.html

2.解压,我是解压到了 D:\spark-2.2.3
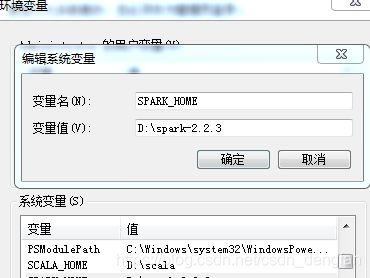
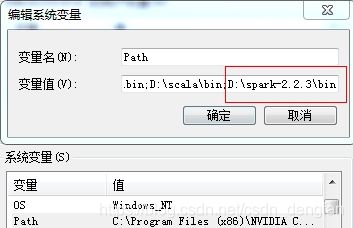
3. 配置文件不做修改,直接配置环境变量
SPARK_HOME 值为D:\spark-2.2.3 path中的值为 D:\spark-2.2.3\bin
测试:
cmd中输入spark-shell
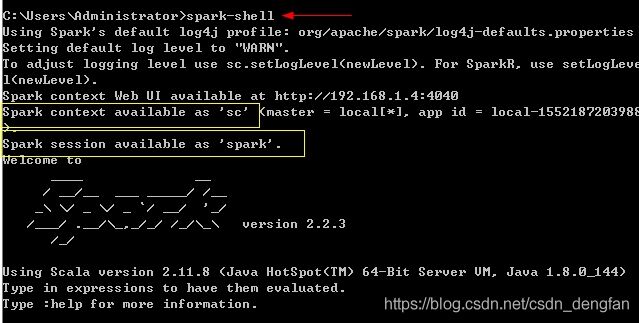
如果出现上图黄框中的内容表示开启成功。 第二个黄框中的spark session就是过去的spark sql。
*从上图我们还看到了spark图形下面有句话: Using Scala version 2.11.8 。。。。
这意味着,如果我们想再安装scala,那么最好安装2.11.8 版本。