读书笔记----《编写高质量代码:改善Java程序的151个建议》第十~十二章
读书笔记----《编写高质量代码:改善Java程序的151个建议》第十~十二章
- 第10章 性能和效率
- 132:提升Java性能的基本方法
- 133:若非必要,不要克隆对象
- 134:推荐使用“望闻问切”的方式诊断性能
- 135:必须定义性能衡量标准
- 136:枪打出头鸟—解决首要系统性能问题
- 137:调整JVM参数以提升性能
- 138 性能是个大“咕咚”
- 第11章 开源世界
- 139:大胆采用开源工具
- 140:推荐使用Guava扩展工具包
- 141:Apache扩展包
- 142:推荐使用Joda日期时间扩展包
- 143:可以选择多种Collections扩展
- 第12章 思想为源
- 144:提倡良好的代码风格
- 145:不要完全依靠单元测试来发现问题
- 146:让注释正确、清晰、简洁
- 147:让接口的职责保持单一
- 148:增强类的可替换性
- 149:依赖抽象而不是实现
- 150:抛弃7条不良的编码习惯
- 151:以技术员自律而不是工人
第10章 性能和效率
132:提升Java性能的基本方法
- 不要在循环条件中计算
这一点可以引申到“尽可能多的将代码提到循环之外进行” - 尽可能把变量、方法声明为final static类型
- 缩小变量的作用范围,目的是加快GC的回收
- 频繁字符串操作使用StringBuilder或StringBuffer【StringBuilder 优于StringBuffer】
- 使用非线性检索
ArrayList使用indexOf查找元素会比java.utils.Collections.binarySearch的效率低很多,原因是binarySearch是二分搜索法,而indexOf使用的是逐个元素比对的方法。 - 覆写Exception的fillInStackTrace方法
如果我们在开发时不需要关注栈信息,则可以覆盖,如覆盖fillInStackTrace的自定义异常会使性能提升10倍以上。 - 不建立冗余对象
最基本的优化方法就是自我验证,找出最佳的优化途径,提高系统性能,不可盲目信任。
133:若非必要,不要克隆对象
JVM对new做了大量的性能优化,而clone方式只是一个冷僻的生成对象方式,并不是主流,它主要用于构造函数比较复杂,对象属性比较多,通过new关键字创建一个对象比较耗时间的时候。
134:推荐使用“望闻问切”的方式诊断性能
(1)望
性能问题从表象上来看可以分为两类:
& 1) 不可(或很难)重现的偶发性问题
& 2) 可重现的性能问题
至少要测试三个有性能问题的交易(或者三个与业务相关而技术无关的功能,或者与技术有关而业务无关的功能)为什么是三个呢?因为“永远不要带两块手表”,这会致使无法验证和校对。
(2)闻
在性能优化上的“闻”则是关注项目被动产生的信息,其中包括:项目组的技术能力(主要取决于技术经理的技术能力)、文化氛围、群体的习惯和习性,以及他们专注和擅长的领域等。
@如果项目组的技术能力很强,有资深的数据库专家,有顶尖的架构师,也有首席程序员,那性能问题产生的根源就应该定位在无意识的代码缺陷上。
@如果项目组的文化氛围很糟糕,组员不交流,没有固定的代码规范,缺乏整体的架构等,那性能问题的根源就可能存在于某个配置上,或者相互的接口调用上。
@如果项目组已经习惯了某一个框架,而且也习惯了框架的种种约束,那性能的根源就可能是有人越过了框架的协约。
(3)问
与技术人员(缔造者)和业务人员(使用者)一起探讨该问题,了解性能问题的历史状况
(4)切
看设计,看代码,看日志,看系统环境,然后是思考分析,最后给出结论。
注意两点:
一是所有的非一手资料(如报告、非系统信息)都不是100%可信的,二是测试环境毕竟是测试环境,它只是证明假设的辅助工具,并不能证明方法或策略的正确性。
135:必须定义性能衡量标准
出现性能问题不可怕,可怕的是没有目标,用户只是说“我希望它非常快”,或者说“和以前一样快”,在这种情况下,我们就需要把制定性能衡量标准放在首位。
一个好的性能衡量标准应该包括以下KPI(Key Performance Indicators):
- 核心业务的响应时间。
- 重要业务的响应时间。
性能衡量标准必须在一定的环境下,比如网络、操作系统、硬件设备等确定的情况下才会有意义,并且还需要限定并发数、资源数(如10万数据和1000万的数据响应时间肯定不同)等。
136:枪打出头鸟—解决首要系统性能问题
性能优化项目中超过80%的只要修正了第一个缺陷,其他的性能问题就会自行解决或非常容易解决,已经不成为问题了。
解决性能问题时,不要把所有的问题都摆在眼前,这只会“扰乱”你的思维,集中精力,找到那个“出头鸟”,解决它,在大部分情况下,一批性能问题都会迎刃而解,而且我们的用户关注最多的可能就是系统20%的功能,可能我们解决了这一部分,已经达到了用户的预期目标,也就标志着我们的优化工作可以结束了。
137:调整JVM参数以提升性能
(1)调整堆内存大小
(2)调整堆内存中各分区的比例
(3)变更GC的垃圾回收策略
(4)更换JVM
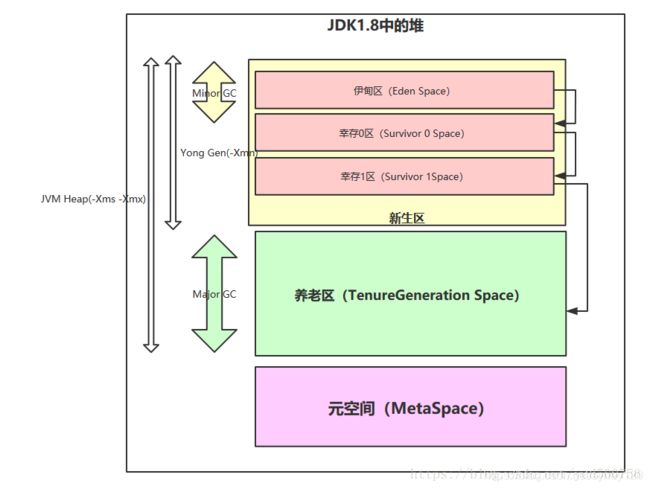 注意点:
注意点:
metaSpace在jdk1.7之前被称为Permanent Space
而且严格意义上讲metaSpace不属于堆空间
见下图:
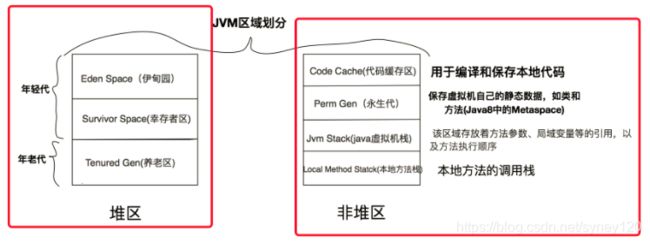 关于metaSpace 的具体介绍,请参考这篇文章
关于metaSpace 的具体介绍,请参考这篇文章
关于部分调优项的介绍
| 调优参数 | 说明 | 备注 |
|---|---|---|
| -Xms | 初始堆的分配大小 | 默认为物理内存的六十四分之一 |
| -Xmx | 堆的最大分配大小 | 默认为物理内存的四分之一 |
| -Xmn | 新生代的大小 | Sun官方推荐配置为整个堆的3/8 |
| -Xss | 每个线程的堆栈大小 | JDK5.0以后每个线程堆栈默认大小为1M |
| -XX:NewRatio | 设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代) | 设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5 |
| -XX:SurvivorRatio | 如设置年轻代中Eden区与Survivor区的大小比值 | 如设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6 |
| -XX:MaxTenuringThreshold | 设置垃圾最大年龄 | 如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代 |
| -XX:MetaspaceSize | 元空间初始值 | 对应jdk1.8之前的-XX:PermSize |
| -XX:MaxMetaspaceSize | 元空间最大值 | 默认没有限制,对应jdk1.8之前的-XX:MaxPermSize |
| -XX:MinMetaspaceFreeRatio | 在GC之后,最小的Metaspace剩余空间容量的百分比 | 为了减少为分配空间所导致的垃圾收集 |
| -XX:MaxMetaspaceFreeRatio | 在GC之后,最大的Metaspace剩余空间容量的百分比 | 为了减少为释放空间所导致的垃圾收集 |
138 性能是个大“咕咚”
(1)没有慢的系统,只有不满足业务的系统
(2)没有慢的系统,只有架构不良的系统
(3)没有慢的系统,只有懒惰的技术人员
(4)没有慢的系统,只有不愿意投入的系统
第11章 开源世界
139:大胆采用开源工具
在选择开源工具和框架时要遵循一定的原则:
- 普适性原则
确保大部分项目成员对工具都比较熟悉 - 唯一性原则
相同的工具只选择一个或一种,不要让多种相同或相似职能的工具共存。
例如集合工具可以在Apache Commons的collections包和Google Guava的Collections工具包中二选其一。 - “大树纳凉”原则
寻找比较有名的开源组织,比如Apache、Spring、opensymphony、google等 - 精而专原则
比如虽然Spring框架提供了Utils工具包,但在一般情况下不要使用它,因为它不专,Utils工具包只是Spring框架中的一个附加功能而已,要用就用Apache Commons的BeanUtils、Lang等工具包。 - 高热度原则
一个开源项目的热度越高,更新得就越频繁,使用的人群就越广,Bug的曝光率就越快,修复效率也就越高。
140:推荐使用Guava扩展工具包
不再赘述,谁用谁知道。
141:Apache扩展包
同上条
142:推荐使用Joda日期时间扩展包
(1)本地格式的日期时间
(2)日期计算
(3)时区时间
(4)可以与JDK的日期库方便地进行转换
143:可以选择多种Collections扩展
三个比较有个性的Collections扩展工具包:
(1)fastutil
主要提供了两种功能:一种是限定键值类型(Type Specific)的Map、List、Set等,另一种是大容量的集合。
(2)Trove
提供了一个快速、高效、低内存消耗的Collection集合,并且还提供了过滤和拦截的功能,同时还提供了基本类型的集合。
Trove的最大优势是在高性能上,在进行一般的增加、修改、删除操作时,Trove的响应时间比JDK的集合少一个数量级,比fastutil也会高很多,因此在高性能项目中要考虑使用Trove。
(3)lambdaj
lambdaj是一个纯净的集合操作工具,它不会提供任何的集合扩展,只会提供对集合的操作,比如查询、过滤、统一初始化等,特别是它的查询操作,非常类似于DBRMS上的SQL语句,而且也会提供诸如求和、求平均值等的方法:
List<Integer>ints=new ArrayList<Integer>();
//计算平均值
Lambda.avg(ints);
//统计每个元素出现的次数,返回的是一个Map
Lambda.count(ints);
//按照年龄排序
List<Person>persons=new ArrayList<Person>();
Lambda.sort(persons, Lambda.on(Person.class).getAge()));
//串联所有元素的指定属性,输出为:张三,李四,王五
Lambda.joinFrom(persons).getName();
//过滤出年龄大于20岁的所用元素,输出为一个子列表
Lambda.select(persons, new BaseMatcher<Person>(){
@Override
public boolean matches(Object_person){
Person p=(Person)_person;
return p.getAge()>20;
}
public void describeTo(Description desc){
}
});
//查找出最大年龄
Lambda.maxFrom(persons).getAge();
//抽取出所有姓名形成一个数组
Lambda.extract(persons, Lambda.on(Person.class).getName()));
第12章 思想为源
144:提倡良好的代码风格
(1)整洁
(2)统一
一个团队中诞生的代码应该具有一致的风格
(3)流行
(4)便捷
制定出来的编码规范必须有通用开发工具支撑,不能制定出只能由个别开发工具支持的规范,甚至是绑定在某一个IDE上
推荐使用Checkstyle,
阿里有阿里规范检测插件,支持ideal和eclipse,功能更强大。
145:不要完全依靠单元测试来发现问题
(1)单元测试不可能测试所有的场景(路径)
单元测试必须测试的三种数据场景是:正常场景、边界场景、异常场景。如果要进行完整的测试就必须建立三个不同的测试场景:正常数据场景,用来测试代码的主逻辑;边界数据场景,用来测试代码(或数据)在边界的情况下逻辑是否正确;异常数据场景,用来测试出现异常非故障时能否按照预期运行。
通常在项目中,单元测试覆盖率很难达到60%,因为不能100%覆盖,这就导致了代码测试的不完整性,隐藏的缺陷也就必然存在了。
(2)代码整合错误是不可避免的
(3)部分代码无法(或很难)测试
单元测试只能对确定算法进行假设,不能对不确定算法进行验证。
(4)单元测试验证的是编码人员的假设
如果编码者从一开始就误解了需求意图,此时的单元测试就充当了帮凶:验证了一个错误的假设。
146:让注释正确、清晰、简洁
避免以下类型的注释:
(1)废话式注释
(2)故事式注释
(3)不必要的注释【非废话,但多此一举的注释】
(4)过时的注释
(5)大块注释代码
(6)流水账式的注释
(7)专为JavaDoc编写的注释
在注释中只保留<p>、<code>等几个常用的标签,不要增加<font>、<table>、<div>等标签。
提倡好的注释:
(1)法律版权信息
(2)解释意图的注释
说明为什么要这样做,而不是怎么做的,比如解决了哪个Bug,方法过时的原因是什么。
(3)警示性注释
(4)TODO注释
注释不是美化剂,而是催化剂,或为优秀加分,或为拙劣减分。
147:让接口的职责保持单一
单一职责原则(Single Responsibility Principle,简称SRP)就是要求我们的接口(或类)尽可能保持单一,它的定义是说“一个类有且仅有一个变化的原因(There should never be more than one reason for a class to change)”
单一职责有以下三个优点:
(1)类的复杂性降低
(2)可读性和可维护性提高
(3)降低变更风险
实施单一职责原则:
(1)分析职责
依靠变化因素来划分职责
(2)设计接口
先不考虑实现类是如何设计的,首先确定每个职责通过一个接口来实现。
(3)合并实现
实现类不一定要分别实现每一个接口 :这样做确实完全满足了单一职责原则的要求:每个接口和类职责分明,结构清晰。
对于单一职责原则,建议接口一定要做到职责单一,类的设计尽量做到只有一个原因引起变化。
148:增强类的可替换性
多态的好处非常多,其中有一点就是增强了类的可替换性,但是单单一个多态特性,很难保证我们的类是完全可以替换的,幸好还有一个里氏替换原则来约束。
里氏替换原则是说 “所有引用基类的地方必须能透明地使用其子类的对象”,通俗点讲,只要父类型能出现的地方子类型就可以出现,而且将父类型替换为子类型还不会产生任何错误或异常,反过来就不行了,有子类型出现的地方,父类型未必就能适应。
设计类的时候考虑以下三点:
(1)子类型必须完全实现父类型的方法
(2)前置条件可以被放大
方法中的输入参数称为前置条件
(3)后置条件可以被缩小
父类型方法的返回值是类型T,子类同名方法(重载或覆写)的返回值为S,那么S可以是T的子集:
1> 若是覆写,父类型和子类型的方法名名称就会相同,输入参数也相同(前置条件相同),只是返回值S是T类型的子集,子类型替换父类型完全没有问题。
2> 若是重载,方法的输入参数类型或数量则不相同(前置条件不同),在使用子类型替换父类型的情况下,子类型的方法不会被调用到的,已经无关返回值类型了,此时子类依然具备可替换性。
增强类的可替换性,则增强了程序的健壮性,版本升级时也可以保持非常好的兼容性
149:依赖抽象而不是实现
依赖倒置原则(Dependence Inversion Principle,简称DIP):
高层模块不应该依赖低层模块,两者都应该依赖其抽象。
抽象不应该依赖细节。
细节应该依赖抽象。
要做到遵循此原则要做到以下几点:
(1)尽量抽象
接口和抽象类都是属于抽象的,有了抽象才可能依赖倒置。
(2)表面类型必须是抽象的
比如定义集合,尽量使用:
List<String>list=new ArrayList<String>();
(3)任何类都不应该从具体类派生
开发阶段要做到这一点,但不是绝对的,尤其是在维护时。
(4)尽量不要覆写基类的方法
(5)抽象不关注细节
150:抛弃7条不良的编码习惯
(1)自由格式的代码
(2)不使用抽象的代码
(3)彰显个性的代码
“最小惊诧原则”(Principle Of Least Surprise简称POLS,或者Principle Of Least Astonishment简称POLA),其意是说要使用最常见的,而不是最新颖的功能。
(4)死代码
这些代码按照正常的执行逻辑是不可能被执行到,但是在某些未知情况下它就是执行了,此时就会产生严重的影响。
(5)冗余代码
(6)拒绝变化的代码
(7)自以为是的代码
151:以技术员自律而不是工人
(1)熟悉工具
(2)使用IDE
(3)坚持编码
不要考虑自己的职位、岗位
(4)编码前思考
(5)坚持重构
(6)多写文档
(7)保持程序版本的简单性
(8)做好备份
(9)做单元测试
(10)不要重复发明轮子
但是如果想共享一个新的MVC框架,那就尽管去重复发明轮子吧,它不是以交付为目的的,而是以技术研究为目标的。
(11)不要拷贝
(12)让代码充满灵性
(13)测试自动化
(14)做压力测试
(15)“剽窃”不可耻
多看开源代码
(16)坚持向敏捷学习
不管“敏捷”与“非敏捷”之间的争论有多激烈,敏捷中的一些思想是非常优秀的,例如TDD测试驱动开发、交流的重要性、循序渐渐开发等。
(17)重里更重面
UI(User Interface)是“面”,Java程序是“里”
(18)分享
(19)刨根问底
(20)横向扩展
Java要运行在JVM、操作系统上,同时还要与硬件、网络、存储交互,另外要遵循诸如FTP、SMTP、HTTP等协议,还要实现Web Service、RMI、XML-RPC等接口,所以我们必须熟悉相关的知识—扩展知识面,这些都是必须去学习的。