写几个简单点的shell脚本,配合IDEA,将oracle的建表语句轻松转换为java bean和mybatis的mapper配置
背景
前段时间,遇到一个需求。需求很普通,就是oracle表的一些CRUD。
就是工作量有点大,给了几个sql脚本,里面表有六十多张,每个表一般二三十个字段或者四五十个字段。
用的是mybatis,这样的话,每张表要建一个对应的java bean类,一个对应的mapper文件,需要提供相关的查询和插入语句。
我想了想,硬敲的话,要疯。
mybatis有个逆向工具,我是听过的,只是没用过。不过我一看这些个建表语句都长一个样,就写了几个简单的脚本来转换为对应的bean或mapper。
最近学的东西有点深,不适合写博客,就分享一下我写的这个脚本,有兴趣也能用的上,因为这些sql脚本用pl/sql导出来的时候,基本也长这个样子。
脚本
打个比方,这是一个建表语句,实际表字段很多,我只写了几个字段作为示例,字段名就是这样命名,大小写字母以下划线连接
create table example_table (
user_name VARCHAR2(200) not null,
str1 VARCHAR2(200) not null,
str2 VARCHAR2(200) not null,
str3 VARCHAR2(200),
ONE_FLAG VARCHAR2(1) default 'N' not null,
time5 TIMESTAMP,
str6 VARCHAR2(1) default 'N' not null,
reserved1 VARCHAR2(200),
reserved2 VARCHAR2(200)
);
comment on table example_table is
'样例表';
comment on column example_table.user_name is
'名';
comment on column example_table.str1 is
'这是一个字符串1';
comment on column example_table.str2 is
'这是一个字符串2';
comment on column example_table.str3 is
'这是一个字符串3';
comment on column example_table.ONE_FLAG is
'这是一个标记字符串';
comment on column example_table.time5 is
'时间';
comment on column example_table.str6 is
'又来一个字符串';
comment on column example_table.reserved1 is
'预留字段1';
comment on column example_table.reserved2 is
'预留字段2';在下面要写的脚本所在目录下创建一个名字为txt的文件,把上面的建表语句复制进去。
生成java bean
1. 写一个awk脚本( generate_bean.awk):把表字段转换为变量定义语法,并且加上注释
#! /usr/bin/awk -f
BEGIN {
i = 1;
}
{
comment="";
if ( NR != 1 && i > 0 && $1 != "(" ) {
if ( $1 == ");" ) {
i = -1;
} else {
if ( NF == 1 ) {
print "// "$1;
}
else {
"grep -A 1 comment "FILENAME" | grep -i -A 1 "$1" | grep -i -v "$1 | getline comment;
print "// "comment;
". to_lower_word.sh " $1 | getline lower_word;
print "private String "lower_word";";
}
}
i++;
}
}可以执行下看下效果:./generate_bean.awk txt
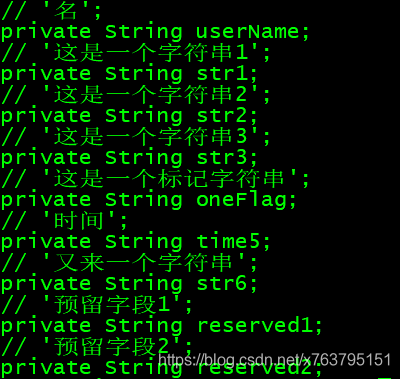
其中to_lower_word.sh,是将str1_str2这种转换为小驼峰命名的变量,如:
#! /bin/bash
echo $1 | tr [:upper:] [:lower:] | sed 's/_[a-z]\{1\}/\U&/g' | sed 's/_//g'
2. 再写一个脚本(gen_ben.sh)调用generate_bean.awk,并去掉注释上的杂质
#! /bin/bash
sed -i 's/^$//g' txt;
if [ ! -e tmp_txt ]; then
touch tmp_txt;
fi
generate_bean.awk txt > tmp_txt;
sed "s/';//g" tmp_txt | sed "s/'//g"
rm tmp_txt看一下执行效果:

3.打开IDEA,新建一个类,复制进去。
alt+insert,快速生成get和set还有toString等方法:

这里有一个问题,写脚本的时候为了赶时间,写的比较low,有些地方需要调整,比如这里都默认转换为String类型了,对于其它类型需要手动改一下。
生成mytatis的ResultMap
1.写一个awk脚本(generate_result.awk):将字段转换为小驼峰,然后拼接处理下
#! /usr/bin/awk -f
BEGIN {
i = 1;
print "";
}
{
file = FILENAME;
if ( NR != 1 && i > 0 && $1 != "(" ) {
if ( $1 == ");" ) {
i = -1;
} else {
if ( NF > 1 ) {
". to_lower_word.sh " $1 | getline lower_word;
print "\t";
}
}
i++;
}
}
END {
print " "
}2.再写一个脚本(gen_result.sh)调用这个脚本:
#! /bin/bash
generate_result.awk txt3.执行看下效果
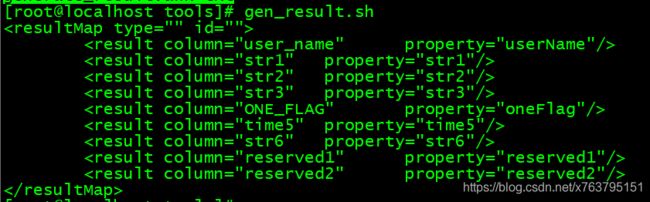
复制到mapper的xml文件里
生成select的sql
1.写一个awk脚本(generate_fields.awk)将数据库表字段转换为小驼峰格式两列数据,第一行是表名:
#! /usr/bin/awk -f
BEGIN {
i = 1;
}
{
if ( NR == 1 ) {
print $3;
}
if ( NR != 1 && i > 0 && $1 != "(" ) {
if ( $1 == ");" ) {
i = -1;
} else {
". to_lower_word.sh " $1 | getline lower_word;
print $1,lower_word;
}
i++;
}
}看一下效果:
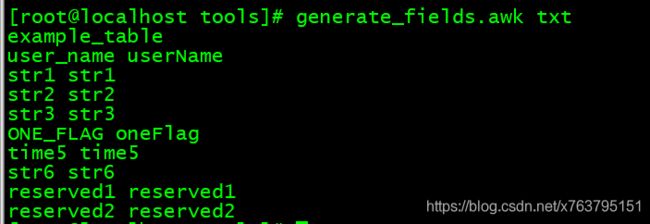
2. 再写一个脚本(gen_select.sh)将这拼接为一个select的sql
#! /bin/bash
generate_fields.awk txt > fields_tmp.txt
table_name=`head -1 fields_tmp.txt`
lines=`wc -l fields_tmp.txt | awk '{print $1}'`
awk -v total=$lines 'BEGIN {print "select";}{ if (NR > 1 && NR < total && NF > 1) {print "\t"$1",";}} END {print "\t"$1;}' fields_tmp.txt;
echo "from $table_name"
echo ""
awk '{if ( NR > 1 ) { print "\t""" "\n\t\t AND " $1" = #{" $2 "}" "\n\t " }}' fields_tmp.txt;
echo " "
rm fields_tmp.txt3.执行下,复制到mapper.xml中,看下效果:
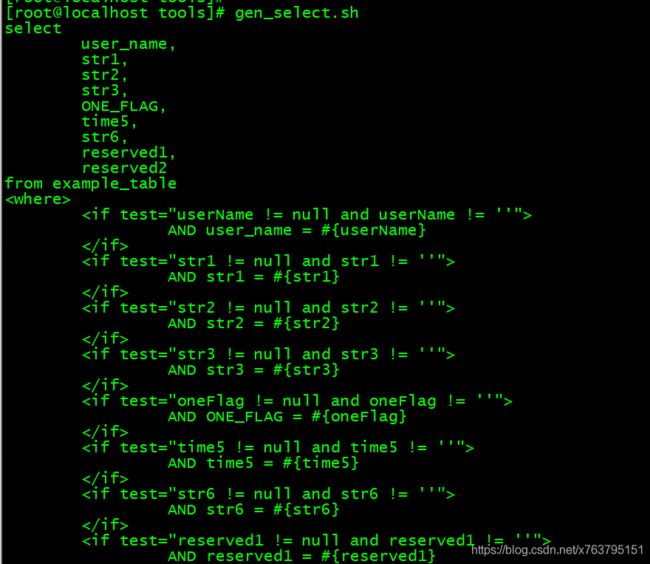
里面有部分字段,根据需要该删除删除,该调整调整
生成insert
1. 脚本(gen_insert.sh)
#! /bin/bash
generate_fields.awk txt > fields_tmp.txt
table_name=`head -1 fields_tmp.txt`
lines=`wc -l fields_tmp.txt | awk '{print $1}'`
awk -v total=$lines -v table_name=$table_name 'BEGIN {print "insert into "table_name"(";}{ if (NR > 1 && NR < total && NF > 1) {print "\t"$1",";}} END {print "\t"$1")";}' fields_tmp.txt;
echo "values("
awk -v total=$lines '{if ( NR > 1 && NR < total ) { print "\t#{" $2 ", jdbcType=VARCHAR}," }} END {print "\t#{"$1 ", jdbcType=VARCHAR}"}' fields_tmp.txt;
echo ")"
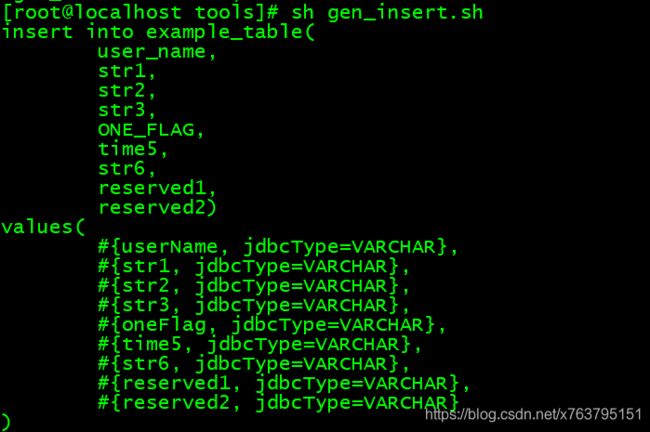
rm fields_tmp.txt2. 执行,copy到mapper.xml中,效果如下:
后记
犹记得那天,我中午没睡用了2个小时才把这个脚本鼓捣出来 。
次日上午,以我疯狂的手速,用了2个小时,不到半天的时间,提交了上万行代码。