关于自编码器的核心点理解
参考文献
1.一文看懂AutoEncoder模型演进图谱
2.《神经网络与深度学习》
3.自编码器是什么?有什么用?这里有一份入门指南(附代码)
4.自动编码器
5.自编码器实现代码(可视化版本)

一、稀疏编码
1.生物学背景
稀疏编码(Sparse Coding)也是一种受哺乳动物视觉系统中简单细胞感受野而启发的模型。外界刺激在视觉神经系统的表示具有很高的稀疏性。编码的稀疏性在一定程度上符合生物学的低功耗特性。
从维度上分析,稀疏编码本质上属于一种升维操作。
2.表示
为了得到稀疏的编码,我们需要找到一组 “超完备” 的基向量(即 p > d)来进行编码。在超完备基向量之间往往会存在一些冗余性,因此对于一个输入样本,会存在很多有效的编码。如果加上稀疏性限制,就可以减少解空间的大小,得到 “唯一” 的稀疏编码。

稀疏性衡量函数有很多种选择,如:L0范数、对数函数、指数函数等。
3.训练方法

4.优点
计算量降低、可解释性提高、可以实现特征的自动选择
二、自编码器
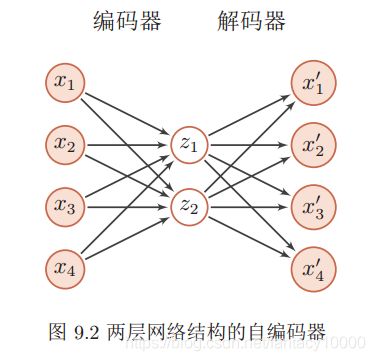
1.最基本的自编码器
自编码器的学习目标:最小化重构错误(reconstruction errors):
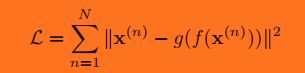
实际中,加入正则项后,目标函数变为:

自编码器利用类似神经网络的双隐层的方式,简单粗暴地提取了样本的特征。
这个双隐层是有争议的,最初的编码器确实使用了两组(W,b),但是Vincent在2010年的论文中做了研究,发现只要单组W就可以了。即W’=WT, W 和 W’ 称为Tied Weights。实验证明,W’ 真的只是在打酱油,完全没有必要去做训练。
逆向重构矩阵让人想起了逆矩阵,若W-1=WT的话,W就是个正交矩阵了,即W是可以训成近似正交阵的。
由于W’就是个酱油,训练完之后就没它事了。正向传播用W即可,相当于为input预先编个码,再导入到下一layer去。所以叫自动编码器,而不叫自动编码解码器。
我们使用自编码器是为了得到有效的数据表示,因此在训练结束后,我们一般去掉解码器,只保留编码器。编码器的输出可以直接作为后续机器学习模型的输入。
2.稀疏自编码器
假设中间隐藏层 z 的维度为 p 大于输入样本 x 的维度 d,并让 z 尽量稀疏,这就是稀疏自编码器(Sparse Auto-Encoder)。
目标函数如下:
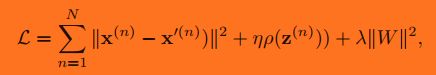
其中稀疏性度量函数 ρ(·)除了可以选择为L0范数、对数函数、指数函数外,还可以定义为一组训练样本中每一个神经元激活的频率
3.栈式自编码器(SAE)
在实践中经常使用逐层堆叠的方式来训练一个深层的自编码器,称为堆叠自编码器(Stacked Auto-Encoder, SAE)。堆叠自编码一般可以采用逐层训练(layer-wise training)来学习网络参数。
当然,这种做法就有一个问题,AutoEncoder可以看作是PCA的非线性补丁加强版,PCA的取得的效果是建立在降维基础上的。仔细想想CNN这种结构,随着layer的推进,每层的神经元个数在递增,如果用了AutoEncoder去预训练,岂不是增维了?真的没问题?
paper中给出的实验结果认为AutoEncoder的增维效果还不赖,原因可能是非线性网络能力很强,尽管神经元个数增多,但是每个神经元的效果在衰减。同时,随机梯度算法给了后续监督学习一个良好的开端。整体上,增维是利大于弊的。
SAE本质上都是非监督学习,SAE各层的输出都是原始数据的不同表达。对于分类任务,往往在SAE顶端再添加一分类层(如Softmax层),并结合有标注的训练数据,在误差函数的指导下,对系统的参数进行微调,以使得整个网络能够完成所需的分类任务。
对于微调过程,既可以只调整分类层的参数(此时相当于把整个SAE当做一个feature extractor),也可以调整整个网络的参数(适合训练数据量比较大的情况)。
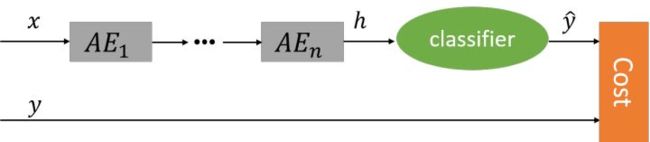
栈式自编码器采用了2006年提出的逐层预训练技术,这一技术真正推动了第三次深度学习浪潮的兴起,虽然后期不断有新技术的提出,使得逐层预训练不再那么必要,但是这一技术仍然有很好的用途,下面是Bingio先生在2015年所作出的评价:
Stacks of unsupervised feature learning layers are STILL useful when you are in a regime with insufficient labeled examples, for transfer learning or domain adaptation. It is a regularizer. But when the number of labeled examples becomes large enough, the advantage of that regularizer becomes much less. I suspect however that this story is far from ended! There are other ways besides pre-training of combining supervised and unsupervised learning, and I believe that we still have a lot to improve in terms of our unsupervised learning algorithms.
4.降噪自编码器(DAE)
为了提高模型对数据部分损坏的鲁棒性,提出了降噪自编码器。
降噪自编码器(Denoising Autoencoder)就是一种通过引入噪声来增加编码鲁棒性的自编码器。
引入噪声的方法有两种:
【1】对于一个向量 x,我们首先根据一个比例 µ 随机将 x 的一些维度的值设置为 0,得到一个被损坏的向量 x˜。然后将损坏比例 µ 一般不超过 0.5;
【2】也可以使用其它的方法来损坏数据,比如引入高斯噪声。
被损坏的向量 x˜ 输入给自编码器得到编码 z,并重构出原始的无损输入 x , 流程如下图所示:

思考:这些衍生的自编码器的产生动机是怎么来的??
实际上这些衍生模型,来自于问题:隐层的维度到底怎么确定?怎么才能称得上是一个好的表达?
事实上,这个问题回答并不唯一,也正是从不同的角度去思考这个问题,导致了自编码器的各种变种形式出现。
