pytorch 基础操作知识(一)
文章目录
- 前言
- python与pytorch
-
- 1、类型对比
- 2、代码实例
- pytorch的标量创建
- pytorch的张量创建
- 几个名词对应的概念
- 数据的导入
- 数据的初始化问题
-
- 1、未初始化的分配
- 2、随机数初始化
- 3、指定值初始化
- 索引与切片
- 维度变化
-
- 1、不可逆变化
- 2、维度增加
- 3、维度减少
- 4、维度拓展
- 4、转置操作
- 5、维度交换
前言
这个系列应该会有两篇文章,主要记录整理了一些pytorch的基本使用与实验代码。
python与pytorch
1、类型对比
| python | pytorch |
|---|---|
| int | inttensor of size() |
| float | floattensor of size() |
| int array | inttensor of size [d1,d2,d3…] |
| float array | floattensor of size [d1,d2,d3…] |
| string | – |
Quest1. 如何来表示string类型
one-hot就是:总共几种类型就用几维数组来表示,但是会有两个比较不好的地方。第一,当数据维度特别大的时候,数据稀疏(大部分位都是0);第二,对于比如说文本,转化之后不能保留原有文本的语义相关性等等。Embedding:Word2vecglove
2、代码实例
当然,仅仅是pytorch内部,就也存在着cpu变量与gpu变量的不同,结合下面的代码来进一步了解吧。所有代码的ipynb格式代码都在整个专栏的github代码库中,欢迎star与下载使用
import torch
a = torch.randn(2,3) # 随机初始化一个两行三列的矩阵 randn表示N(0,1)来进行初始化
print(a)
print(a.type())
print(type(a)) # 不推荐使用python的type,不显示其详细类型
print(isinstance(a, torch.FloatTensor)) # isinstance 判断是否是已知的这个类型
tensor([[-0.4170, -0.5086, 0.0340],
[-1.8330, 0.3811, -0.3105]])
torch.FloatTensor
<class 'torch.Tensor'>
True
torch.FloatTensor
# cpu类型与gpu类型的不同
print(isinstance(a, torch.cuda.FloatTensor))
a = a.cuda()
print(isinstance(a, torch.cuda.FloatTensor))
False
True
pytorch的标量创建
直接看下面的代码吧,写在备注里面了
# pytorch的标量表示
a = torch.tensor(1.1) # 标量0维矩阵
print(a.shape)
print(len(a.shape))
print(a.size())
torch.Size([])
0
torch.Size([])
pytorch的张量创建
三种创建方法:
# 第一种创建方法,直接赋值
torch.tensor([1,2,3])

# 第二种创建方法,指定初始化的元素个数
torch.Tensor(3) # 注意要大写,区分上面的那个标量表示

# 第三种创建方法 使用numpy创建,之后引入
import numpy
data = numpy.ones(2)
data
torch.from_numpy(data)

几个名词对应的概念
例子:
[[1,1],[2,2]] # 2行2列矩阵
dim:全写dimension,也就是维度,对应行或列size/shape:对应[2,2]表示对应数据时2行2列矩阵tensor变量名:就是具体指上面的这个数据
数据的导入
数据导入最常见的就是通过numpy进行导入,
# 从numpy导入数据
import numpy,torch
a = numpy.array([2,3,3])
print(a)
b = torch.from_numpy(a)
print(b)
# 从list中导入
torch.tensor([1,2,3,4,5])

数据的初始化问题
1、未初始化的分配
虽然说大写的T也是可以赋值的,但是为了避免某些时候的混淆,代码可读性,大写为未赋值的初始化,小写为赋值初始化(也可以理解为就是list转变成tensor类型)
# 未初始化的api
torch.Tensor(2,2)
# 分配了内存空间之后一定要记得初始化赋值,否则可能会出现各种各样的问题,比如下面的例子,数值非常大或者非常小

设置torch.set_default_tensor_type(torch.DoubleTensor)是为了提高精度,一般没做任何改动的时候,默认的是torch.FloatTensor类型
2、随机数初始化
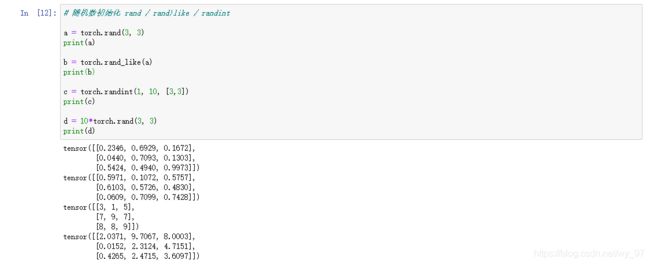
# 随机数初始化 rand / rand)like / randint
a = torch.rand(3, 3)
print(a)
b = torch.rand_like(a)
print(b)
c = torch.randint(1, 10, [3,3])
print(c)
d = 10*torch.rand(3, 3)
print(d)
两个注意点:
_like这种类型的函数都是相当于,把指定tensor的shape提取出来,去丢给随机初始化函数初始化;rand初始化的范围是0,1,而randint必须是整数,所以必须通过乘法手段来获取范围内的float随机数初始化
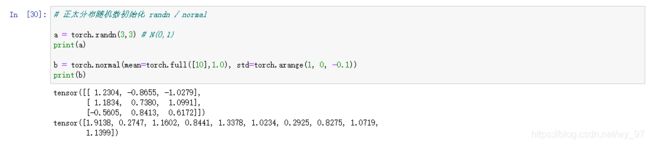
# 正太分布随机数初始化 randn / normal
a = torch.randn(3,3) # N(0,1)
print(a)
b = torch.normal(mean=torch.full([10],1.0), std=torch.arange(1, 0, -0.1))
print(b)
注意:
normal生成的每个值是对应的N(mean,std)生成的随机数,我给了10个mean,是个std,所以最终生成10个随机数,不过是一维的,自己可以重新切分成多维tensor
3、指定值初始化
# 用指定值填充指定结构,dtype指定类型
print(torch.full([10],1, dtype=torch.int))
print(torch.full([2,3],1, dtype=torch.int))
print(torch.full([],1, dtype=torch.int))
torch.arange(100,90,-1)

# 等分
print(torch.linspace(0,10, steps=5))
print(torch.logspace(0,10, steps=5)) # 这个分出来还要变成10 x次方

Ps:最后补充,为了解决torch中没有shuffle功能
# 产生随机索引,主要是为了shuffle
torch.randperm(10)

索引与切片
a = torch.rand(4,3,28,28)
# 从最左边开始索引
print(a[0].shape)
print(a[0,0].shape)
print(a[0,0,2,4])
# 冒号索引,和python中的列表的用法差不多
print(a.shape)
print(a[:2].shape)
print(a[:1,:1].shape)
print(a[:1,1:].shape)
print(a[:1,-1:].shape)
# 隔行采样,和python也一样 start:end:step
print(a[:1,:1,0:10:2].shape)
print(a[:1,:1,::2].shape)

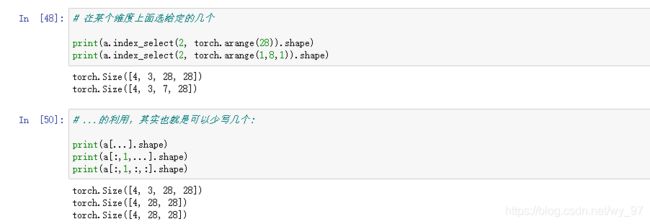
# 在某个维度上面选给定的几个
print(a.index_select(2, torch.arange(28)).shape)
print(a.index_select(2, torch.arange(1,8,1)).shape)
# ...的利用,其实也就是可以少写几个:
print(a[...].shape)
print(a[:,1,...].shape)
print(a[:,1,:,:].shape)
x = torch.randn(4,4)
print(x)
mark = x.ge(0.5) # 把所有大于0.5的选出来
print(mark)
print(torch.masked_select(x, mark))# 把对应标记矩阵中为true的选出来

维度变化
1、不可逆变化
a = torch.rand(4,1,28,28)
print(a.shape)
b = a.view(4,28*28)
print(b.shape)
b = a.reshape(4,28*28)
print(b.shape)

reshape和view函数完全是一致的作用,使用这两个函数的时候,一定要注意三个问题:
- 和原先的数据总量一定要一样多
- 不要做没有实际意义(无法理解)的变化操作
- 做完操作之后,由于丢失了原先的信息,没有办法
reshape回去,原来的维度/存储顺序非常重要
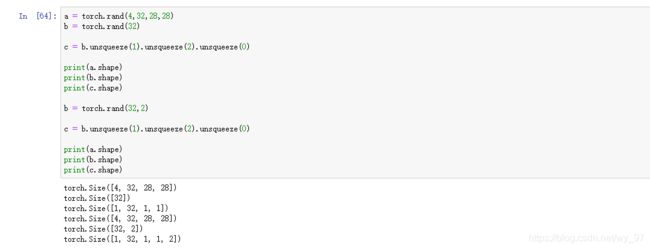
2、维度增加
a = torch.rand(4,32,28,28)
b = torch.rand(32)
c = b.unsqueeze(1).unsqueeze(2).unsqueeze(0)
print(a.shape)
print(b.shape)
print(c.shape)
b = torch.rand(32,2)
c = b.unsqueeze(1).unsqueeze(2).unsqueeze(0)
print(a.shape)
print(b.shape)
print(c.shape)
在某个维度新增维度,看上面两个例子的对比,很容易理解
3、维度减少
这里的c是上一个代码片的c
# squeeze与unsqueeze相反,将所有1的尽可能给压缩
print(c.shape)
print(c.squeeze().shape)
print(c.squeeze(0).shape)

可以看到在不指定压缩维度的时候,直接将能压缩的(值为1)全部压缩了,指定了则按照指定的来
4、维度拓展
注意区分下增加于拓展的区别,而且expand拓展需要有两个前提:
- 维度一致
- 1拓展成n
结合代码的例子来理解吧
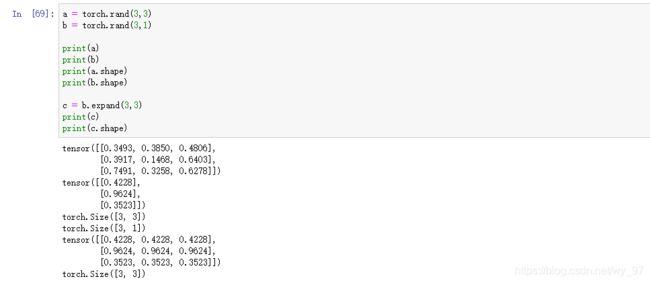
a = torch.rand(3,3)
b = torch.rand(3,1)
print(a)
print(b)
print(a.shape)
print(b.shape)
c = b.expand(3,3)
print(c)
print(c.shape)
再来看下repeat拓展
print(b.shape)
d = b.repeat(3,3)
e = b.repeat(1,3)
print(d.shape)
print(d)
print(e.shape)
print(e)

repeat对应维度的复制次数,而不是最终维度
4、转置操作
a = torch.rand(2,3)
a.t()

这里需要注意的是,转置只适用于2维矩阵
5、维度交换
# transpose 只能两两交换
a = torch.rand(1,2,3,4)
print(a.shape)
b = a.transpose(1,3)
print(b.shape)
c = a.permute(0,3,1,2)# 这里的0,1,2,3指的是之前的tensor矩阵的维度位置
print(c.shape)
transpose 只能两两交换,permute则可以直接一次性搞定