自动驾驶平台Apollo 5.5阅读手记:Cyber RT中的任务调度
前言
自动驾驶系统Apollo在3.5中引入了Cyber RT,替换了之前基于ROS的变体。Cyber RT的一大特点在于其调度系统。因为自动驾驶与人身安全强相关,因此很强调实时性。传统的机器人系统并不为此设计,所以很难满足实时性要求。系统中存在大量异步任务,如果任其运行和抢占,系统会有很大的不确定性。为了提高系统中任务执行的确定性,Cyber RT引入了协程(Coroutine),在用户态来做调度,一方面让开发者可以结合场景做控制,避免让内核调度任务带来不确定性,另一方面避免用户态-内核态切换带来的开销。去年春节写了些东西 自动驾驶平台Apollo 3.5阅读手记:Cyber RT中的协程(Coroutine) 简单聊了下Cyber RT中协程的机理。今年春节就接下去,聊一下基于它的任务调度机制。
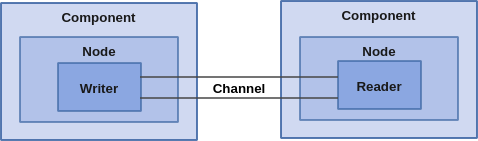
我们知道自动驾驶系统的流程可分感知、决策、执行三大块。从外界环境被车的传感器感知,到刹车、油门和方向的控制,会经过一系列模块的计算。这些模块之间相互有数据信赖,因此可以表示成图的拓扑结构。在Cyber RT的处理流水线中,一个算法模块一般对应一个Component。数据流入该模块,经过算法处理,最后输出结果。Component包含Node,它对应计算图中的结点。Node之间通信通过Channel,它对应计算图中的边。Channel的两边分别是Reader和Writer,用于读取和写入数据。示意图如下:
在Apollo中这些计算结点和它们之间的部分依赖关系是通过dag文件描述的。举例来说,modules/dreamview/conf/hmi_modes/mkz_close_loop.pb.txt中列了整体系统中各子系统对应的dag文件,每个dag文件中又会有多个组件。
1 cyber_modules {
2 key: "Computer"
3 value: {
4 dag_files: "/apollo/modules/drivers/camera/dag/camera_no_compress.dag"
5 dag_files: "/apollo/modules/drivers/gnss/dag/gnss.dag"
6 dag_files: "/apollo/modules/drivers/radar/conti_radar/dag/conti_radar.dag"
7 dag_files: "/apollo/modules/drivers/velodyne/dag/velodyne.dag"
8 dag_files: "/apollo/modules/localization/dag/dag_streaming_msf_localization.dag"
9 dag_files: "/apollo/modules/perception/production/dag/dag_streaming_perception.dag"
10 dag_files: "/apollo/modules/perception/production/dag/dag_streaming_perception_trafficlights.dag"
11 dag_files: "/apollo/modules/planning/dag/planning.dag"
12 dag_files: "/apollo/modules/prediction/dag/prediction.dag"
13 dag_files: "/apollo/modules/storytelling/dag/storytelling.dag"
14 dag_files: "/apollo/modules/routing/dag/routing.dag"
15 dag_files: "/apollo/modules/transform/dag/static_transform.dag"
16 process_group: "compute_sched"
17 }
18 }
19 cyber_modules {
20 key: "Controller"
21 value: {
22 dag_files: "/apollo/modules/canbus/dag/canbus.dag"
23 dag_files: "/apollo/modules/control/dag/control.dag"
24 dag_files: "/apollo/modules/guardian/dag/guardian.dag"
25 process_group: "control_sched"
26 }
27 }
...
如果将它们画出来可以看到是一个比较复杂的计算图(没画全,实际还会比这个复杂不少):
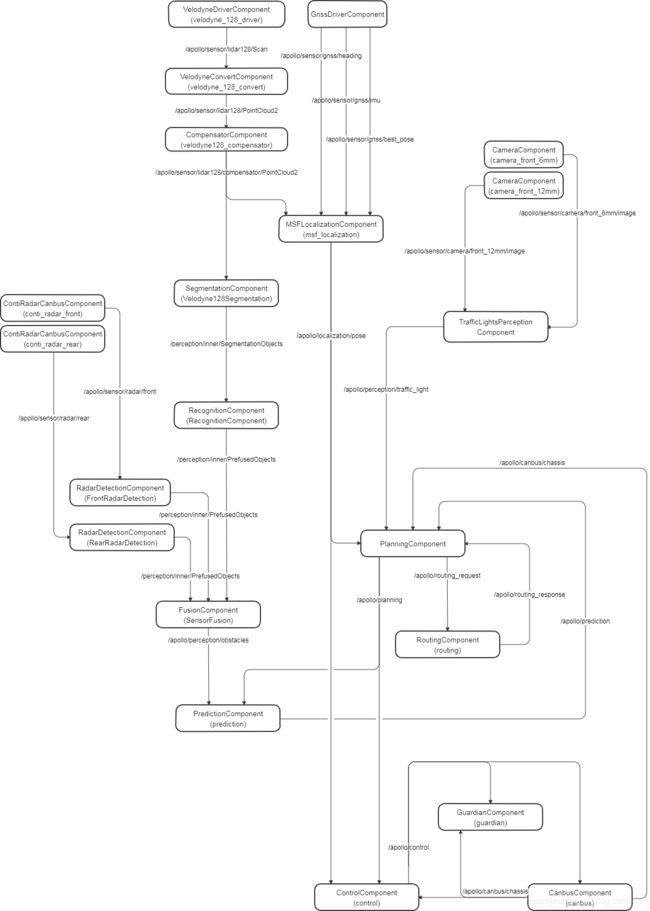
那么问题来了。如何调度整个计算图使其的执行能满足各种时间约束,以达到系统的实时性和确定性,是个巨大的挑战。本文结合最新v5.5.0版本的Apollo源码看下Cyber RT中的调度系统。
实现剖析
调度的实现主要在cyber/scheduler目录下。最核心的类是Scheduler。它有两个继承类,分别对应两种调度方法:Classic(经典)策略与Choreophgray(编排)策略。两者并不是互斥关系,后者可看作对前者的扩展。它们的介绍和示例可参考官方文档 Cyber RT Scheduler。调度策略配置文件用protobuf定义,协议格式文件在cyber/proto目录下: scheduler_conf.proto, classic_conf.proto和choreography_conf.proto。调度策略配置文件在cyber/conf目录下。对于上面mkz_close_loop.pb.txt中的两个process group:compute_sched和control_sched,根据调度策略不同分别有两个版本:
| group\policy | Classic | Choreophgraphy |
|---|---|---|
| Compute | compute_sched_classic.conf |
compute_sched_choreography.conf |
| Control | control_sched_classic.conf |
control_sched_choreography.conf |
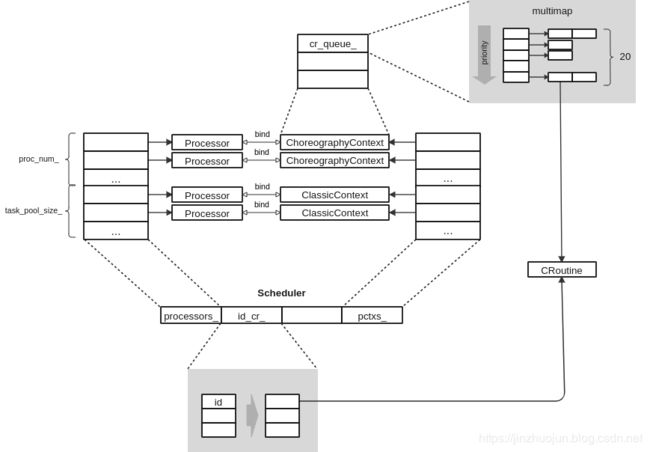
Scheduler是个单例,它的Instance()方法第一次被调用时会加载调度配置文件进行初始化。初始化中会根据配置文件中指定的类型创建SchedulerClassic或者SchedulerChoreography对象。几个相关的核心类关系如下图: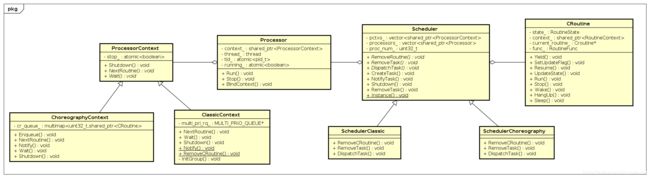
先来看下classic调度策略。对于计算任务的调度配置compute_sched_classic.conf,大概长这个样子:
scheduler_conf {
policy: "classic"
classic_conf {
groups: [
{
name: "compute"
processor_num: 16
affinity: "range"
cpuset: "0-7,16-23"
processor_policy: "SCHED_OTHER"
processor_prio: 0
tasks: [
{
name: "velodyne_16_front_center_convert"
prio: 10
},
{
name: "velodyne_16_rear_left_convert"
prio: 10
},
...
实现类为SchedulerClassic。它的构造函数中首先载入配置文件(如compute_sched.conf,它是compute_sched_classic.conf的链接)。如果读取配置文件失败,会设置默认值。默认值由GlobalData(单例,保存一些全局数据)从配置文件cyber.pb.conf中读入,如默认线程数为16。如果读取成功,会进行相应的初始化:
- 将配置文件中的内部线程信息记录到
inner_thr_confs_查询表中。当这些指定的线程起来后会调用SetInnerThreadAttr()根据这里的配置设置线程的affinity和priority等属性。 - 根据配置设置进程级别的cpuset,这样就指定了该进程中的所有任务都只能在限定的CPU核上运行。
- 配置文件中将所有task分为group。一个group包含多个task。这里将task的配置信息放于
cr_confs_查询表中。 - 根据配置文件中指定的线程个数创建工作线程。虽然Cyber RT引入了协程,但协程的执行仍需以线程为载体。每一个
Processor对象对应一个这样的工作线程。这个名称初看有些容易混淆,因为Processor这个词很多时候是特指CPU的,而这里对应一个线程。因为对于这些协程来说,一个线程可以看作一个逻辑上的CPU。如上面配置文件中指定compute这个group中processor_num为16,则会创建16个Processor,记于processors_结构。同时创建相应数量的ClassicContext实例,记于pctxs_结构,并和Processor绑定,它们是Processor运行的上下文。另外,还会根据配置文件调用函数SetSchedAffinity()与SetSchedPolicy()设置每个线程的affinity与priority属性。Affinity有两种选择,一种是range,即这个线程可以跑在cpuset指定的任一核;另一种是1to1,即绑定于单个核上。
注意配置文件中有两个优先级,一个是processor_prio,它就是Linux中线程的优先级,即nice值,范围从-20到19,值越低优先级越高,默认值为0;另一个是task的prio,它是Cyber RT中的协程调度时的优先级,共20级,值越高优先越高。调度配置文件中的每个group对应一个多优先级任务队列。这些队列放在cr_group_中。优先级共20级,所以每组有20个队列。而每个线程对应的ClassicContext结构中的multi_pri_rq_指向所在group对应的任务队列。示意图如下:
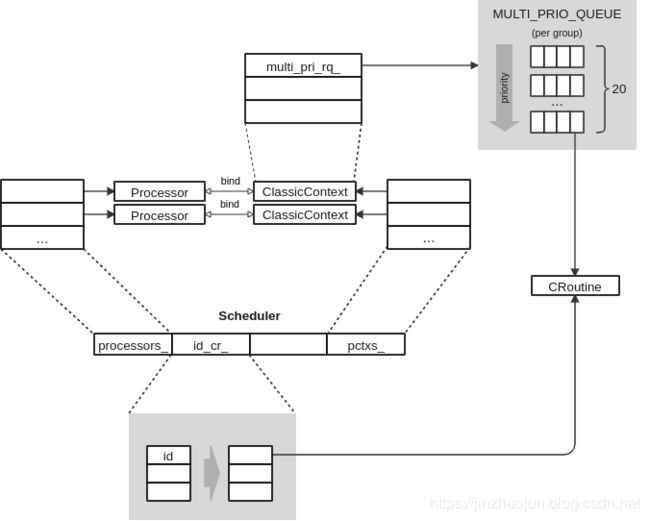
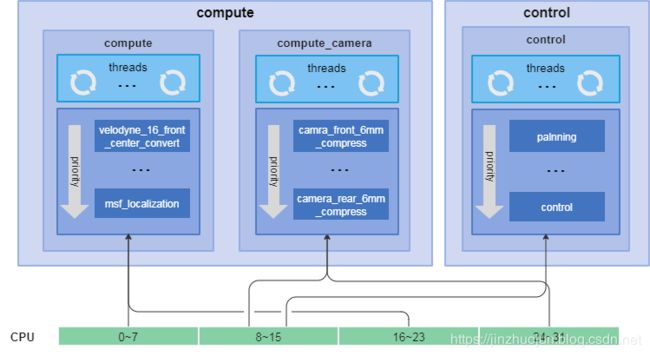
以classic调度策略为例,它将相关任务以组为单位与线程以及CPU物理核作了绑定。示意图如下:
再来看下choreography调度策略。就像前面提到的,它是classic调试策略的扩展,主要差别是它可以将task与线程绑定。因此,使用它需要开发者对系统中各模块有充分的了解。其配置文件大概长这个样子:
scheduler_conf {
policy: "choreography"
choreography_conf {
choreography_processor_num: 8
choreography_affinity: "range"
choreography_cpuset: "0-7"
pool_processor_num: 12
pool_affinity: "range"
pool_cpuset: "8-11,16-23"
tasks: [
{
name: "velodyne_128_convert"
processor: 0
prio: 11
},
{
name: "velodyne128_compensator"
processor: 1
prio: 12
},
...
可以看到和classic模式很相似,事实上pool开头的那些就是对应classic模式。不同的是增加了choreography开头的那几个属性,它们用于设置专门的线程,并让下面的task可以通过processor属性与这些线程进行绑定。这体现在实现上是与ClassicContext中多优先级任务队列会在一个group的线程间共享不同,每一个ChoreographyContext有一个单独的优先级队列cr_queue_。而在派发任务 DispatchTask()函数中,如果该任务协程所指定的线程在choreography的线程集中,则将之放入该线程对应ChoreographyContext的任务队列中。
Scheduler中所有的工作线程起来后都会执行Processor::Run()函数:
void Processor::Run() {
tid_.store(static_cast<int>(syscall(SYS_gettid)));
AINFO << "processor_tid: " << tid_;
snap_shot_->processor_id.store(tid_);
while (cyber_likely(running_.load())) {
if (cyber_likely(context_ != nullptr)) {
auto croutine = context_->NextRoutine();
if (croutine) {
snap_shot_->execute_start_time.store(cyber::Time::Now().ToNanosecond());
snap_shot_->routine_name = croutine->name();
croutine->Resume();
croutine->Release();
} else {
snap_shot_->execute_start_time.store(0);
context_->Wait();
}
} else {
std::unique_lock<std::mutex> lk(mtx_ctx_);
cv_ctx_.wait_for(lk, std::chrono::milliseconds(10));
}
}
}
它的核心主循环逻辑很简单,就是不断地调用与之绑定的ProcessorContext的NextRoutine()函数取得下一个协程,也就是下一个任务。如果没取到,就调用ProcessorContext的Wait()等待。如果取到了,就调用协程类的Resume()函数继续运行。
接下来看下NextRoutine()函数是如何挑选下一个任务的。ProcessorContext有两个实现类ClassicContext和ChoreographyContext。就像前面提到的,它们两个的实现由于其任务优先级队列结构不同也略有不同。前者是按优先级从高到低从所在group对应的任务队列multi_pri_rq_中取任务;而后者也是按优先级从高到低的顺序,但是从cr_queue_中取。取到后,需要判断其状态是否为READY,如果是就返回它。对每个协程,对调用UpdateState()函数检查其状态。这个函数中,对于那些之前睡下去的协程,这里判断是否睡够了,睡够了就将状态设为READY。对于那些之前是因为等待IO或者数据而切走的协程,当等待的东西已经就绪了(SetUpdateFlag()来标记更新),就将协程状态设为READY。
我们知道,这里调度的单位是协程,一个协程对应一个任务。那这些任务主要来自于哪里呢?这就需要看下CreateTask()函数主要在哪些地方被调用:
Component:我们知道,整个系统中处理数据的计算图由组件构成。它的初始化函数Initialize()中最后会调用CreateTask()创建task。参数包含RoutinFactory对象,它包含该task的执行体和DataVisitor。这个执行体主要调用Component的Process()函数,它继而调用继承类可自定义的纯虚函数Proc()。DataVisitor用来管理该组件对指定channel的数据访问。它的RegisterNotifyCallback()函数注册回调。该回调在指定channel有数据到来时被调用,它会调用Scheduler的NotifyProcessor()函数通知相应的协程来处理。以SChedulerClassic::NotifyProcessor()为例,它先设置相应协程的状态,然后唤醒该协程所在组的线程池中的线程之一。接下去,正常情况下这个被唤醒线程就会去载入这个因数据到来而就绪的协程运行。Reader:用于读channel上的数据。Node::CreateReader()调用NodeChannelImpl::CreateReader()创建指定消息类型的Reader对象。在Reader类的初始化函数Init()中,它会调用CreateTask()创建task。这个task主要干的是在消息来的时候将之放入队列中,同时调用事先注册的处理回调函数(如有)。Async:TaskManager用于管理一些自定义异步任务的执行。它会维护一个任务队列task_queue_。通过cyber::Async()函数创建一个异步任务就是往这个任务队列中放入一个新的任务。在TaskManager的构造函数中,会通过Scheduler得到线程个数,并创建同样个数的协程任务。这些协程的执行体就是不断地从这个任务队列中拿任务。如果拿不到,它会将状态设为等待数据并将自己切走;如果拿到了就会执行该任务。
结语
自动驾驶中安全是重中之重,而安全性的核心必要条件之一就是确定性。Cyber RT的主要特点之一就是提高系统调度的确定性。通过对CPU的细粒度分配和基于协程的调度,开发者得以按照自动驾驶系统中各模块的业务特点将它们进行编排。同时,也要注意几点:
- 任务以协程为单位调度,但对Kernel来说,调度的仍是线程。因此如果Kernel不是实时的,那就像木桶原理,整个系统仍无法保证实时性和确定性。这也是为啥架构图中的下层一般会画上RTOS的原因。
- 需要显式地使用Cyber RT的接口才能纳入其调度。祼起的原生线程不受控制。理论上如果起个原生线程而且设个很高的优先级可能会打乱已有编排,破坏确定性。
- 框架提供了提高确定性的调度机制,但如何编排来保证确定性是需要开发者完成的。相信自动化或半自动化的编排策略生成是演进的重要方向。