ZooKeeper入门简介
ZooKeeper 是什么?
ZooKeeper 顾名思义 动物园管理员,他是拿来管大象(Hadoop) 、 蜜蜂(Hive) 、 小猪(Pig) 的管理员, Apache Hbase和 Apache Solr 以及LinkedIn sensei 等项目中都采用到了 Zookeeper。ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,ZooKeeper是以Fast Paxos算法为基础,实现同步服务,配置维护和命名服务等分布式应用。
ZooKeeper 如何工作?
ZooKeeper是作为分布式应用建立更高层次的同步(synchronization)、配置管理 (configuration maintenance)、群组(groups)以及名称服务(naming)。在编程上,ZooKeeper设计很简单,所使用的数据模型风格很像文件系统的目录树结构,简单来说,有点类似windows中注册表的结构,有名称,有树节点,有Key(键)/Value(值)对的关系,可以看做一个树形结构的数据库,分布在不同的机器上做名称管理。
Zookeeper分为2个部分:服务器端和客户端,客户端只连接到整个ZooKeeper服务的某个服务器上。客户端使用并维护一个TCP连接,通过这个连接发送请求、接受响应、获取观察的事件以及发送心跳。如果这个TCP连接中断,客户端将尝试连接到另外的ZooKeeper服务器。客户端第一次连接到ZooKeeper服务时,接受这个连接的 ZooKeeper服务器会为这个客户端建立一个会话。当这个客户端连接到另外的服务器时,这个会话会被新的服务器重新建立。
启动Zookeeper服务器集群环境后,多个Zookeeper服务器在工作前会选举出一个Leader,在接下来的工作中这个被选举出来的Leader死了,而剩下的Zookeeper服务器会知道这个Leader死掉了,在活着的Zookeeper集群中会继续选出一个Leader,选举出leader的目的是为了可以在分布式的环境中保证数据的一致性。如图所示:
另外,ZooKeeper 支持watch(观察)的概念。客户端可以在每个znode结点上设置一个观察。如果被观察服务端的znode结点有变更,那么watch就会被触发,这个watch所属的客户端将接收到一个通知包被告知结点已经发生变化。若客户端和所连接的ZooKeeper服务器断开连接时,其他客户端也会收到一个通知,也就说一个Zookeeper服务器端可以对于多个客户端,当然也可以多个Zookeeper服务器端可以对于多个客户端,如图所示:
你还可以通过命令查看出,当前那个Zookeeper服务端的节点是Leader,哪个是Follower,如图所示:
记得大约在2006年的时候Google出了Chubby来解决分布一致性的问题(distributed consensus problem),所有集群中的服务器通过Chubby最终选出一个Master Server ,最后这个Master Server来协调工作。简单来说其原理就是:在一个分布式系统中,有一组服务器在运行同样的程序,它们需要确定一个Value,以那个服务器提供的信息为主/为准,当这个服务器经过n/2+1的方式被选出来后,所有的机器上的Process都会被通知到这个服务器就是主服务器 Master服务器,大家以他提供的信息为准。很想知道Google Chubby中的奥妙,可惜人家Google不开源,自家用。
但是在2009年3年以后沉默已久的Yahoo在Apache上推出了类似的产品ZooKeeper,并且在Google原有Chubby的设计思想上做了一些改进,因为ZooKeeper并不是完全遵循Paxos协议,而是基于自身设计并优化的一个2 phase commit的协议,如图所示:
ZooKeeper跟Chubby一样用来存放一些相互协作的信息(Coordination),这些信息比较小一般不会超过1M,在zookeeper中是以一种hierarchical tree的形式来存放,这些具体的Key/Value信息就store在tree node中,如图所示:
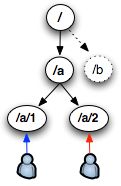
当有事件导致node数据,例如:变更,增加,删除时,Zookeeper就会调用 triggerWatch方法,判断当前的path来是否有对应的监听者(watcher),如果有watcher,会触发其process方法,执行process方法中的业务逻辑,如图所示:
应用实例
ZooKeeper有了上述的这些用途,让我们设想一下,在一个分布式系统中有这这样的一个应用:
2个任务工厂(Task Factory)一主一从,如果从的发现主的死了以后,从的就开始工作,他的工作就是向下面很多台代理(Agent)发送指令,让每台代理(Agent)获得不同的账户进行分布式并行计算,而每台代理(Agent)中将分配很多帐号,如果其中一台代理(Agent)死掉了,那么这台死掉的代理上的账户就不会继续工作了。
上述,出现了3个最主要的问题:
1.Task Factory 主/从一致性的问题
2.Task Factory 主/从心跳如何用简单+稳定 或者2者折中的方式实现。
3.一台代理(Agent)死掉了以后,一部分的账户就无法继续工作,需要通知所有在线的代理(Agent)重新分配一次帐号。
怕文字阐述的不够清楚,画了系统中的Task Factory和Agent的大概系统关系,如图所示:
OK,让我们想想ZooKeeper是不是能帮助我们去解决目前遇到的这3个最主要的问题呢?
解决思路
1. 任务工厂Task Factory都连接到ZooKeeper上,创建节点,设置对这个节点进行监控,监控方法例如:
event= new WatchedEvent(EventType.NodeDeleted, KeeperState.SyncConnected, "/TaskFactory");
这个方法的意思就是只要Task Factory与zookeeper断开连接后,这个节点就会被自动删除。
2.原来主的任务工厂断开了TCP连接,这个被创建的/TaskFactory节点就不存在了,而且另外一个连接在上面的Task Factory可以立刻收到这个事件(Event),知道这个节点不存在了,也就是说主TaskFactory死了。
3.接下来另外一个活着的TaskFactory会再次创建/TaskFactory节点,并且写入自己的ip到znode里面,作为新的标记。
4.此时Agents也会知道主的TaskFactory不工作了,为了防止系统中大量的抛出异常,他们将会先把自己手上的事情做完,然后挂起,等待收到Zookeeper上重新创建一个/TaskFactory节点,收到 EventType.NodeCreated 类型的事件将会继续工作。
5.原来从的TaskFactory 将自己变成一个主TaskFactory,当系统管理员启动原来死掉的主的TaskFactory,世界又恢复平静了。
6.如果一台代理死掉,其他代理他们将会先把自己手上的事情做完,然后挂起,向TaskFactory发送请求,TaskFactory会重新分配(sharding)帐户到每个Agent上了,继续工作。
上述内容,大致如图所示: