06.图像识别与卷积神经网络------《Tensorflow实战Google深度学习框架》笔记
一、图像识别问题简介及经典数据集
图像识别问题希望借助计算机程序来处理、分析和理解图片中的内容,使得计算机可以从图片中自动识别各种不同模式的目标和对象。图像识别问题作为人工智能的一个重要领域,在最近几年已经取得了很多突破性的进展,其中,卷积神经网络就是这些突破性进展背后最主要的技术支持。
如下为一些经典的数据集介绍:
ImageNet
ImageNet是一个计算机视觉系统识别项目,是目前世界上图像识别最大的数据库。是美国斯坦福的计算机科学家李飞飞模拟人类的识别系统建立的。能够从图片识别物体。目前已经包含14197122张图像,是已知的最大的图像数据库。每年的ImageNet大赛更是魂萦梦牵着国内外各个名校和大型IT公司以及网络巨头的心。图像如下图所示,需要注册ImageNet帐号才可以下载,下载链接为http://www.image-net.org/
PASCAL VOC
PASCALVOC 数据集是视觉对象的分类识别和检测的一个基准测试,提供了检测算法和学习性能的标准图像注释数据集和标准的评估系统。图像如下图所示,包含VOC2007(430M),VOC2012(1.9G)两个下载版本。下载链接为http://pjreddie.com/projects/pascal-voc-dataset-mirror/

Labelme
Labelme是斯坦福一个学生的母亲利用休息时间帮儿子做的标注,后来便发展为一个数据集。该数据集的主要特点包括
(1)专门为物体分类识别设计,而非仅仅是实例识别
(2)专门为学习嵌入在一个场景中的对象而设计
(3)高质量的像素级别标注,包括多边形框(polygons)和背景标注(segmentation masks)
(4)物体类别多样性大,每种物体的差异性,多样性也大。
(5)所有图像都是自己通过相机拍摄,而非copy
(6)公开的,免费的
图像如下图所示,需要通过matlab来下载,一种奇特的下载方式,下载链接为http://labelme2.csail.mit.edu/Release3.0/index.php

COCO
COCO是一种新的图像识别,分割和加字幕标注的数据集。主要由Tsung-Yi Lin(Cornell Tech),Genevieve Patterson (Brown),MatteoRuggero Ronchi (Caltech),Yin Cui (Cornell Tech),Michael Maire (TTI Chicago),Serge Belongie (Cornell Tech),Lubomir Bourdev (UC Berkeley),Ross Girshick (Facebook AI), James Hays (Georgia Tech),PietroPerona (Caltech),Deva Ramanan (CMU),Larry Zitnick (Facebook AI), Piotr Dollár (Facebook AI)等人收集而成。其主要特征如下
(1)目标分割
(2)通过上下文进行识别
(3)每个图像包含多个目标对象
(4)超过300000个图像
(5)超过2000000个实例
(6)80种对象
(7)每个图像包含5个字幕
(8)包含100000个人的关键点
图像如下图所示,支持Matlab和Python两种下载方式,下载链接为http://mscoco.org/

SUN
SUN数据集包含131067个图像,由908个场景类别和4479个物体类别组成,其中背景标注的物体有313884个。图像如下图所示,下载链接为http://groups.csail.mit.edu/vision/SUN/

Caltech
Caltech是加州理工学院的图像数据库,包含Caltech101和Caltech256两个数据集。该数据集是由Fei-FeiLi, Marco Andreetto, Marc 'Aurelio Ranzato在2003年9月收集而成的。Caltech101包含101种类别的物体,每种类别大约40到800个图像,大部分的类别有大约50个图像。Caltech256包含256种类别的物体,大约30607张图像。图像如下图所示,下载链接为http://www.vision.caltech.edu/Image_Datasets/Caltech101/

Corel5k
这是Corel5K图像集,共包含科雷尔(Corel)公司收集整理的5000幅图片,故名:Corel5K,可以用于科学图像实验:分类、检索等。Corel5k数据集是图像实验的事实标准数据集。请勿用于商业用途。私底下学习交流使用。Corel图像库涵盖多个主题,由若干个CD组成,每个CD包含100张大小相等的图像,可以转换成多种格式。每张CD代表一个语义主题,例如有公共汽车、恐龙、海滩等。Corel5k自从被提出用于图像标注实验后,已经成为图像实验的标准数据集,被广泛应用于标注算法性能的比较。Corel5k由50张CD组成,包含50个语义主题。
Corel5k图像库通常被分成三个部分:4000张图像作为训练集,500张图像作为验证集用来估计模型参数,其余500张作为测试集评价算法性能。使用验证集寻找到最优模型参数后4000张训练集和500张验证集混合起来组成新的训练集。
该图像库中的每张图片被标注1~5个标注词,训练集中总共有374个标注词,在测试集中总共使用了263个标注词。图像如下图所示,很遗憾本人也未找到官方下载路径,于是github上传了一份,下载链接为https://github.com/watersink/Corel5K

CIFAR(Canada Institude For Advanced Research)
CIFAR是由加拿大先进技术研究院的AlexKrizhevsky, Vinod Nair和Geoffrey Hinton收集而成的80百万小图片数据集。包含CIFAR-10和CIFAR-100两个数据集。 Cifar-10由60000张32*32的RGB彩色图片构成,共10个分类。50000张训练,10000张测试(交叉验证)。这个数据集最大的特点在于将识别迁移到了普适物体,而且应用于多分类。CIFAR-100由60000张图像构成,包含100个类别,每个类别600张图像,其中500张用于训练,100张用于测试。其中这100个类别又组成了20个大的类别,每个图像包含小类别和大类别两个标签。官网提供了Matlab,C,Python三个版本的数据格式。图像如下图所示,下载链接为http://www.cs.toronto.edu/~kriz/cifar.html

人脸数据库:
AFLW(Annotated Facial Landmarks in the Wild)
AFLW人脸数据库是一个包括多姿态、多视角的大规模人脸数据库,而且每个人脸都被标注了21个特征点。此数据库信息量非常大,包括了各种姿态、表情、光照、种族等因素影响的图片。AFLW人脸数据库大约包括25000万已手工标注的人脸图片,其中59%为女性,41%为男性,大部分的图片都是彩色,只有少部分是灰色图片。该数据库非常适合用于人脸识别、人脸检测、人脸对齐等方面的研究,具有很高的研究价值。图像如下图所示,需要申请帐号才可以下载,下载链接为http://lrs.icg.tugraz.at/research/aflw/

LFW(Labeled Faces in the Wild)
LFW是一个用于研究无约束的人脸识别的数据库。该数据集包含了从网络收集的13000张人脸图像,每张图像都以被拍摄的人名命名。其中,有1680个人有两个或两个以上不同的照片。这些数据集唯一的限制就是它们可以被经典的Viola-Jones检测器检测到(a hummor)。图像如下图所示,下载链接为http://vis-www.cs.umass.edu/lfw/index.html#download

AFW(Annotated Faces in the Wild)
AFW数据集是使用Flickr(雅虎旗下图片分享网站)图像建立的人脸图像库,包含205个图像,其中有473个标记的人脸。对于每一个人脸都包含一个长方形边界框,6个地标和相关的姿势角度。数据库虽然不大,额外的好处是作者给出了其2012 CVPR的论文和程序以及训练好的模型。图像如下图所示,下载链接为http://www.ics.uci.edu/~xzhu/face/

FDDB(Face Detection Data Set and Benchmark)
FDDB数据集主要用于约束人脸检测研究,该数据集选取野外环境中拍摄的2845个图像,从中选择5171个人脸图像。是一个被广泛使用的权威的人脸检测平台。图像如下图所示,下载链接为http://vis-www.cs.umass.edu/fddb/

WIDER FACE
WIDER FACE是香港中文大学的一个提供更广泛人脸数据的人脸检测基准数据集,由YangShuo, Luo Ping ,Loy ,Chen Change ,Tang Xiaoou收集。它包含32203个图像和393703个人脸图像,在尺度,姿势,闭塞,表达,装扮,关照等方面表现出了大的变化。WIDER FACE是基于61个事件类别组织的,对于每一个事件类别,选取其中的40%作为训练集,10%用于交叉验证(cross validation),50%作为测试集。和PASCAL VOC数据集一样,该数据集也采用相同的指标。和MALF和Caltech数据集一样,对于测试图像并没有提供相应的背景边界框。图像如下图所示,下载链接为http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/

CMU-MIT
CMU-MIT是由卡内基梅隆大学和麻省理工学院一起收集的数据集,所有图片都是黑白的gif格式。里面包含511个闭合的人脸图像,其中130个是正面的人脸图像。图像如下图所示,没有找到官方链接,Github下载链接为 https://github.com/watersink/CMU-MIT
GENKI
GENKI数据集是由加利福尼亚大学的机器概念实验室收集。该数据集包含GENKI-R2009a,GENKI-4K,GENKI-SZSL三个部分。GENKI-R2009a包含11159个图像,GENKI-4K包含4000个图像,分为“笑”和“不笑”两种,每个图片的人脸的尺度大小,姿势,光照变化,头的转动等都不一样,专门用于做笑脸识别。GENKI-SZSL包含3500个图像,这些图像包括广泛的背景,光照条件,地理位置,个人身份和种族等。图像如下图所示,下载链接为http://mplab.ucsd.edu,如果进不去可以,同样可以去下面的github下载,链接https://github.com/watersink/GENKI

IJB-A (IARPA JanusBenchmark A)
IJB-A是一个用于人脸检测和识别的数据库,包含24327个图像和49759个人脸。图像如下图所示,需要邮箱申请相应帐号才可以下载,下载链接为http://www.nist.gov/itl/iad/ig/ijba_request.cfm

MALF (Multi-Attribute Labelled Faces)
MALF是为了细粒度的评估野外环境中人脸检测模型而设计的数据库。数据主要来源于Internet,包含5250个图像,11931个人脸。每一幅图像包含正方形边界框,俯仰、蜷缩等姿势等。该数据集忽略了小于20*20的人脸,大约838个人脸,占该数据集的7%。同时,该数据集还提供了性别,是否带眼镜,是否遮挡,是否是夸张的表情等信息。图像如下图所示,需要申请才可以得到官方的下载链接,链接为 http://www.cbsr.ia.ac.cn/faceevaluation/
MegaFace
MegaFace资料集包含一百万张图片,代表690000个独特的人。所有数据都是华盛顿大学从Flickr(雅虎旗下图片分享网站)组织收集的。这是第一个在一百万规模级别的面部识别算法测试基准。 现有脸部识别系统仍难以准确识别超过百万的数据量。为了比较现有公开脸部识别算法的准确度,华盛顿大学在去年年底开展了一个名为“MegaFace Challenge”的公开竞赛。这个项目旨在研究当数据库规模提升数个量级时,现有的脸部识别系统能否维持可靠的准确率。图像如下图所示,需要邮箱申请才可以下载,下载链接为http://megaface.cs.washington.edu/dataset/download.html

300W
300W数据集是由AFLW,AFW,Helen,IBUG,LFPW,LFW等数据集组成的数据库。图像如下图所示,需要邮箱申请才可以下载,下载链接为 http://ibug.doc.ic.ac.uk/resources/300-W/
IMM Data Sets
IMM人脸数据库包括了240张人脸图片和240个asf格式文件(可以用UltraEdit打开,记录了58个点的地标),共40个人(7女33男),每人6张人脸图片,每张人脸图片被标记了58个特征点。所有人都未戴眼镜,图像如下图所示,下载链接为http://www2.imm.dtu.dk/~aam/datasets/datasets.html

MUCT Data Sets
MUCT人脸数据库由3755个人脸图像组成,每个人脸图像有76个点的地标(landmark),图片为jpg格式,地标文件包含csv,rda,shape三种格式。该图像库在种族、关照、年龄等方面表现出更大的多样性。具体图像如下图所示,下载链接为 http://www.milbo.org/muct/
ORL (AT&T Dataset)
ORL数据集是剑桥大学AT&T实验室收集的一个人脸数据集。包含了从1992.4到1994.4该实验室的成员。该数据集中图像分为40个不同的主题,每个主题包含10幅图像。对于其中的某些主题,图像是在不同的时间拍摄的。在关照,面部表情(张开眼睛,闭合眼睛,笑,非笑),面部细节(眼镜)等方面都变现出了差异性。所有图像都是以黑色均匀背景,并且从正面向上方向拍摄。
其中图片都是PGM格式,图像大小为92*102,包含256个灰色通道。具体图像如下图所示,下载链接为http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html

行人检测数据库
INRIA Person Dataset
Inria数据集是最常使用的行人检测数据集。其中正样本(行人)为png格式,负样本为jpg格式。里面的图片分为只有车,只有人,有车有人,无车无人四个类别。图片像素为70*134,96*160,64*128等。具体图像如下图所示,下载链接为http://pascal.inrialpes.fr/data/human/

CaltechPedestrian Detection Benchmark
加州理工学院的步行数据集包含大约包含10个小时640x480 30Hz的视频。其主要是在一个在行驶在乡村街道的小车上拍摄。视频大约250000帧(在137个约分钟的长段),共有350000个边界框和2300个独特的行人进行了注释。注释包括包围盒和详细的闭塞标签之间的时间对应关系。更多信息可在其PAMI 2012 CVPR 2009标杆的论文获得。具体图像如下图所示,下载链接为http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/

MIT cbcl (center for biological and computational learning)Pedestrian Data
该数据集主要包含2个部分,一部分为128*64的包含924个图片的ppm格式的图片,另一部分为从打图中分别切割而出的小图,主要包含胳膊,脑袋,脚,腿,头肩,身体等。具体图像如下图所示,下载链接为http://cbcl.mit.edu/software-datasets/PedestrianData.html,需要才可以。

年龄,性别数据库
Adience
该数据集来源为Flickr相册,由用户使用iPhone5或者其它智能手机设备拍摄,同时具有相应的公众许可。该数据集主要用于进行年龄和性别的未经过滤的面孔估计。同时,里面还进行了相应的landmark的标注。是做性别年龄估计和人脸对齐的一个数据集。图片包含2284个类别和26580张图片。具体图像如下图所示,下载链接为http://www.openu.ac.il/home/hassner/Adience/data.html#agegender

车辆数据库
KITTI(Karlsruhe Institute ofTechnology and Toyota Technological Institute)
KITTI包含7481个训练图片和7518个测试图片。所有图片都是真彩色png格式。该数据集中标注了车辆的类型,是否截断,遮挡情况,角度值,2维和3维box框,位置,旋转角度,分数等重要的信息,绝对是做车载导航的不可多得的数据集。具体图像如下图所示,下载链接为http://www.cvlibs.net/datasets/kitti/
字符数据库
MNIST(Mixed National Instituteof Standards and Technology)
MNIST是一个大型的手写数字数据库,广泛用于机器学习领域的训练和测试,由纽约大学的Yann LeCun整理。MNIST包含60000个训练集,10000个测试集,每张图都进行了尺度归一化和数字居中处理,固定尺寸大小为28*28。具体图像如下图所示,下载链接为http://yann.lecun.com/exdb/mnist/

二、卷积神经网络简介
全连接网络 VS 卷积网络
全连接神经网络之所以不太适合图像识别任务,主要有以下几个方面的问题:
参数数量太多
考虑一个输入1000*1000像素的图片(一百万像素,现在已经不能算大图了),输入层有1000*1000=100万节点。假设第一个隐藏层有100个节点(这个数量并不多),那么仅这一层就有(1000*1000+1)*100=1亿参数,这实在是太多了!我们看到图像只扩大一点,参数数量就会多很多,因此它的扩展性很差。
没有利用像素之间的位置信息
对于图像识别任务来说,每个像素和其周围像素的联系是比较紧密的,和离得很远的像素的联系可能就很小了。如果一个神经元和上一层所有神经元相连,那么就相当于对于一个像素来说,把图像的所有像素都等同看待,这不符合前面的假设。当我们完成每个连接权重的学习之后,最终可能会发现,有大量的权重,它们的值都是很小的(也就是这些连接其实无关紧要)。努力学习大量并不重要的权重,这样的学习必将是非常低效的。
网络层数限制
我们知道网络层数越多其表达能力越强,但是通过梯度下降方法训练深度全连接神经网络很困难,因为全连接神经网络的梯度很难传递超过3层。因此,我们不可能得到一个很深的全连接神经网络,也就限制了它的能力。
那么,卷积神经网络又是怎样解决这个问题的呢?主要有三个思路:
局部连接:这个是最容易想到的,每个神经元不再和上一层的所有神经元相连,而只和一小部分神经元相连。这样就减少了很多参数。
权值共享:一组连接可以共享同一个权重,而不是每个连接有一个不同的权重,这样又减少了很多参数。
下采样:可以使用Pooling来减少每层的样本数,进一步减少参数数量,同时还可以提升模型的鲁棒性。
对于图像识别任务来说,卷积神经网络通过尽可能保留重要的参数,去掉大量不重要的参数,来达到更好的学习效果。
卷积神经网络的基本结构如图所示:

一个卷积神经网络主要由以下五种结构组成:
1、输入层:输入层是整个神经网络的输入,在处理图像的卷积神经网络中,它一般代表了一张图片的像素矩阵。从输入层开始,卷积神经网络通过不同的神经网络结构将上一层的三维矩阵转化为下一层的三维矩阵,直到最后的全连接层。
2、卷积层:和传统全连接层不同,卷积层中每一个节点的输入只是上一层神经网络的一小块,这个小块常用的大小有3x3或者5x5.卷积层试图将神经网络中的每一小块进行更加深入地分析从而得到抽象程度更高的特征。
3、池化层:池化层神经网络不会改变三维矩阵的深度,但是它可以缩小矩阵的大小。池化操作可以认为是将一张分辨率较高的图片转化为分辨率较低的图片。通过池化层,可以进一步缩小最后全连接层中节点的个数,从而达到减少整个神经网络中参数的目的。
4、全连接层:在经过多轮卷积层和池化层的处理之后,在卷积神经网络的最后一般会是由1到2个全连接层来给出最后的分类结果。经过几轮卷积层和池化层的处理之后,可以认为图像中的信息已经被抽象成了信息含量更高的特征。我们可以将卷积层和池化层看成自动图像特征提取的过程。在特征提取完成后,仍然需要使用全连接层来完成分类任务。
5、Softmax层:这一层主要用于分类问题,通过Softmax层,可以得到当前样例属于不同种类的概率分布情况。
三、卷积神经网络常用结构
卷积神经网络输出值的计算
卷积层输出值的计算
我们用一个简单的例子来讲述如何计算卷积,然后,我们抽象出卷积层的一些重要概念和计算方法。
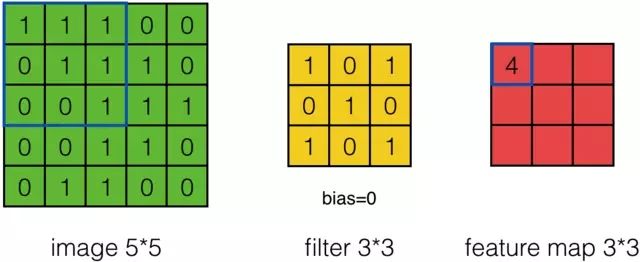
假设有一个5*5的图像,使用一个3*3的filter进行卷积,想得到一个3*3的Feature Map,如下所示:

为了清楚的描述卷积计算过程,我们首先对图像的每个像素进行编号,用Xi,j表示图像的第行第列元素;对filter的每个权重进行编号,用Wm,n表示第m行第n列权重,用Wb表示filter的偏置项;对Feature Map的每个元素进行编号,用ai,j表示Feature Map的第i行第j列元素;用f表示激活函数(这个例子选择relu函数作为激活函数)。然后,使用下列公式计算卷积:

例如,对于Feature Map左上角元素来说,其卷积计算方法为:
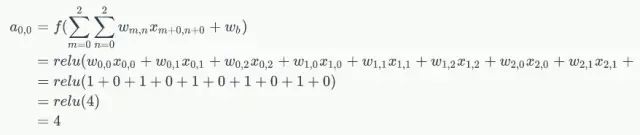
计算结果如下图所示:
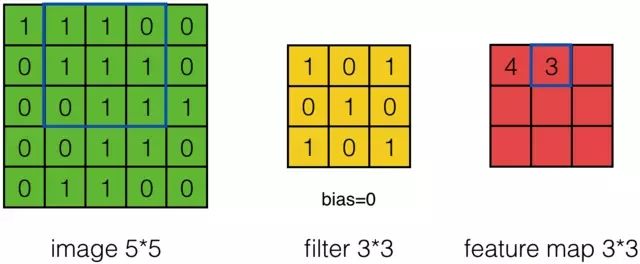
接下来,Feature Map的元素的卷积计算方法为:
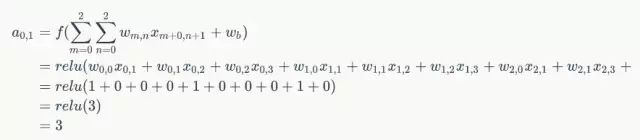
计算结果如下图所示:
可以依次计算出Feature Map中所有元素的值。下面的动画显示了整个Feature Map的计算过程:
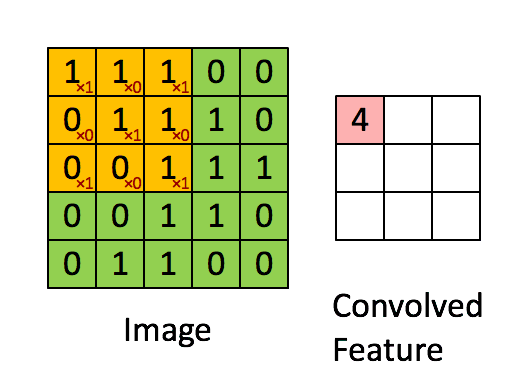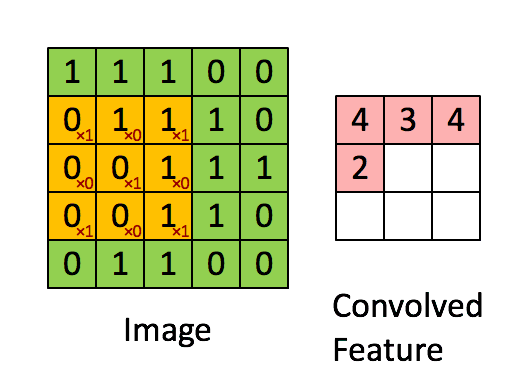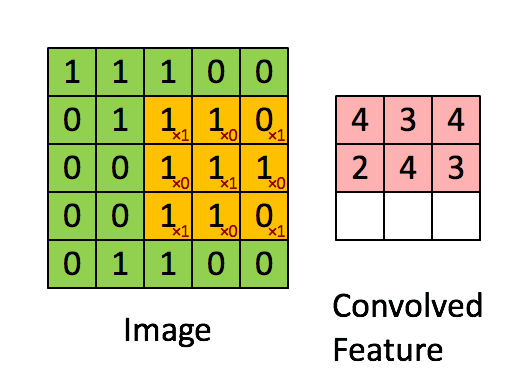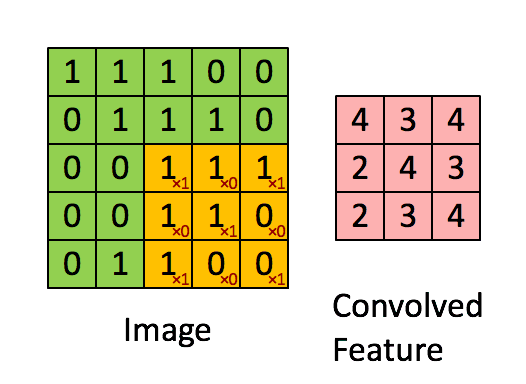
上面的计算过程中,步幅(stride)为1。步幅可以设为大于1的数。例如,当步幅为2时,Feature Map计算如下:
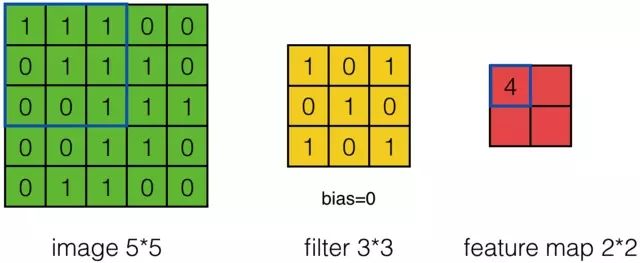
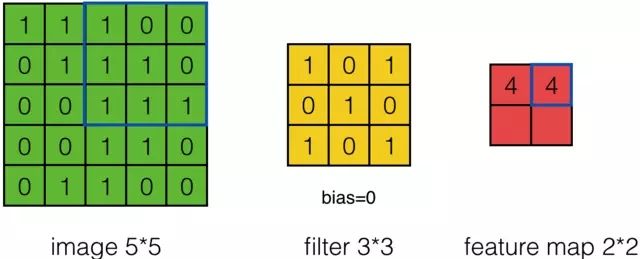
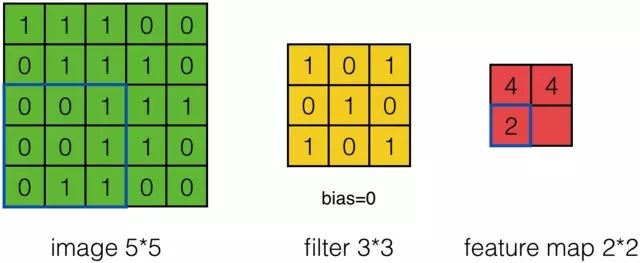

我们注意到,当步幅设置为2的时候,Feature Map就变成2*2了。这说明图像大小、步幅和卷积后的Feature Map大小是有关系的。事实上,它们满足下面的关系:

在上面两个公式中,W2是卷积后Feature Map的宽度;W1是卷积前图像的宽度;F是filter的宽度;P是Zero Padding数量,Zero Padding是指在原始图像周围补几圈0,如果P的值是1,那么就补1圈0;S是步幅;H2是卷积后Feature Map的高度;H1是卷积前图像的宽度。式2和式3本质上是一样的。
以前面的例子来说,图像宽度W1=5,filter宽度F=3,Zero PaddingP=0,步幅S=2,则
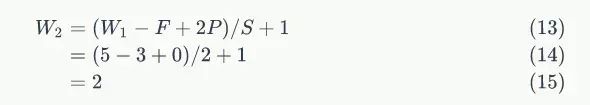
说明Feature Map宽度是2。同样,我们也可以计算出Feature Map高度也是2。
前面我们已经讲了深度为1的卷积层的计算方法,如果深度大于1怎么计算呢?其实也是类似的。如果卷积前的图像深度为D,那么相应的filter的深度也必须为D。我们扩展一下式1,得到了深度大于1的卷积计算公式:
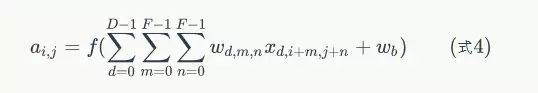
在式4中,D是深度;F是filter的大小(宽度或高度,两者相同);Wd,m,n表示filter的第层第m行第n列权重;ad,I,j表示图像的第d层第i行第j列像素;其它的符号含义和式1是相同的,不再赘述。
我们前面还曾提到,每个卷积层可以有多个filter。每个filter和原始图像进行卷积后,都可以得到一个Feature Map。因此,卷积后Feature Map的深度(个数)和卷积层的filter个数是相同的。
下面的动画显示了包含两个filter的卷积层的计算。我们可以看到7*7*3输入,经过两个3*3*3filter的卷积(步幅为2),得到了3*3*2的输出。另外我们也会看到下图的Zero padding是1,也就是在输入元素的周围补了一圈0。Zero padding对于图像边缘部分的特征提取是很有帮助的。
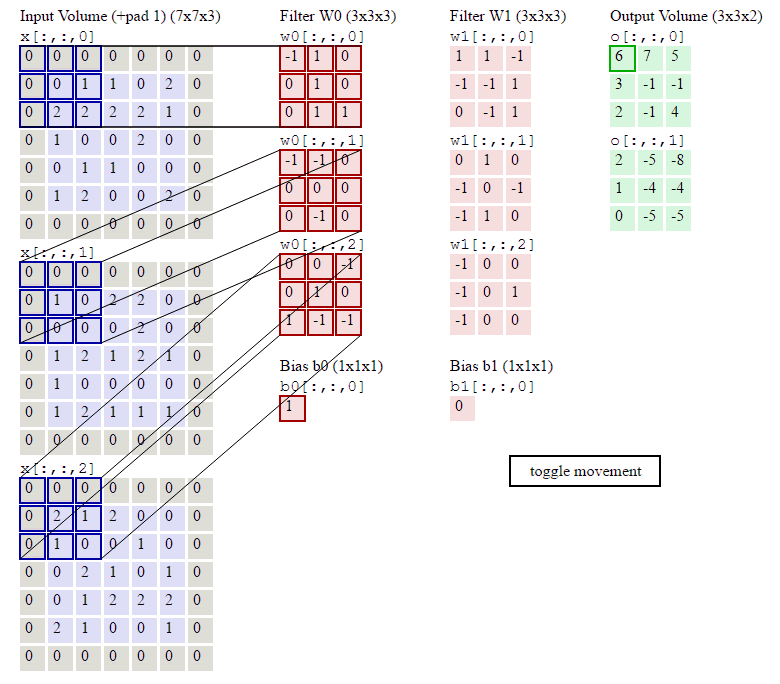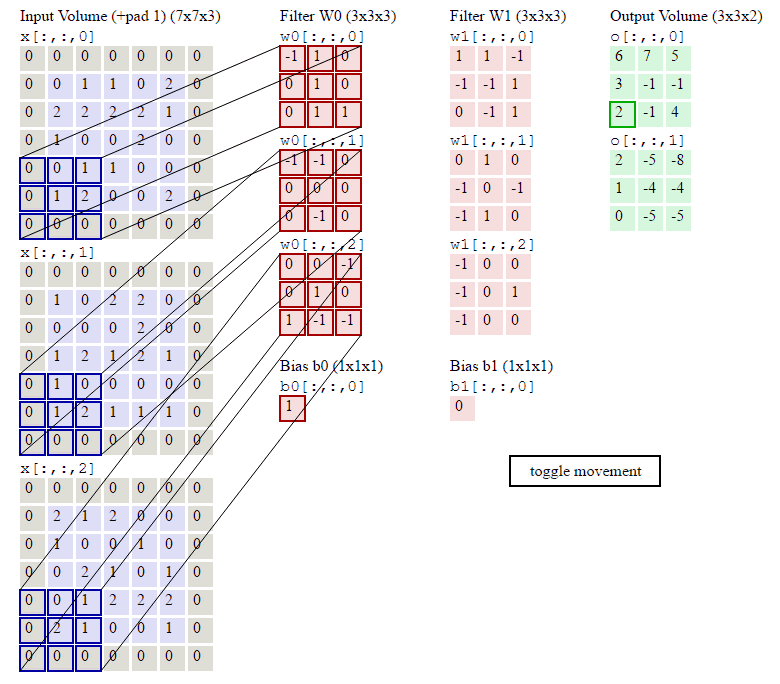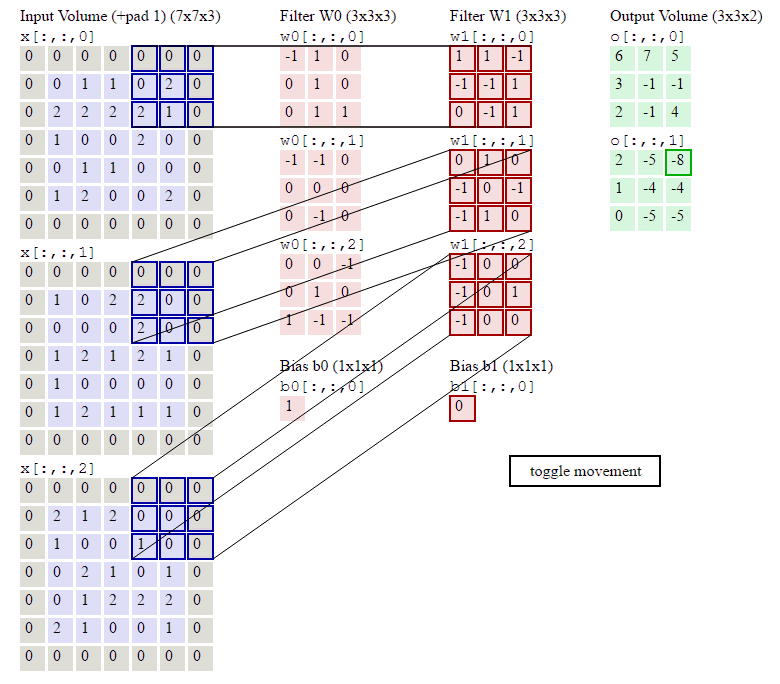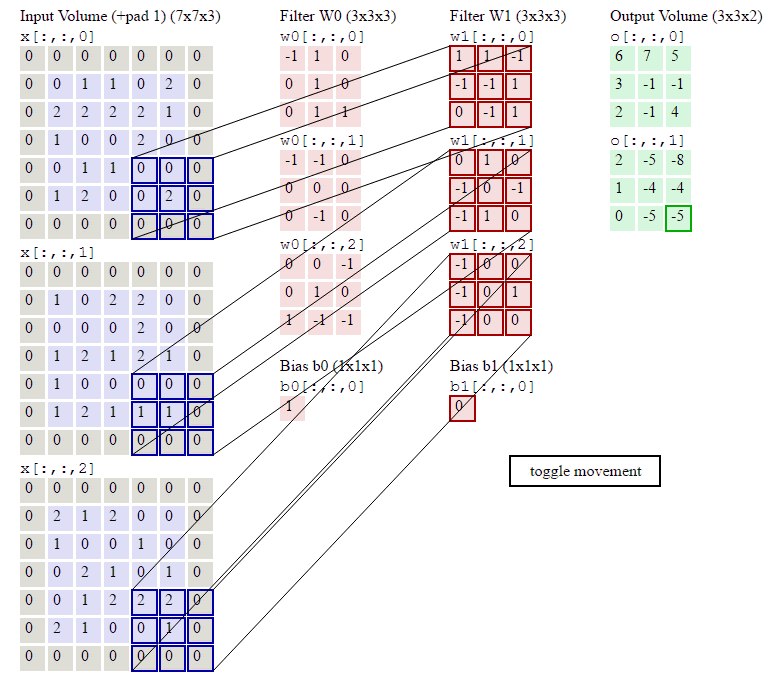
以上就是卷积层的计算方法。这里面体现了局部连接和权值共享:每层神经元只和上一层部分神经元相连(卷积计算规则),且filter的权值对于上一层所有神经元都是一样的。对于包含两个3*3*3的fitler的卷积层来说,其参数数量仅有(3*3*3+1)*2=56个,且参数数量与上一层神经元个数无关。与全连接神经网络相比,其参数数量大大减少了。
用卷积公式来表达卷积层计算
不想了解太多数学细节的读者可以跳过这一节,不影响对全文的理解。
式4的表达很是繁冗,最好能简化一下。就像利用矩阵可以简化表达全连接神经网络的计算一样,我们利用卷积公式可以简化卷积神经网络的表达。
下面我们介绍二维卷积公式。
设矩阵A,B,其行、列数分别为ma、na、mb、nb,则二维卷积公式如下:

且s,t满足条件: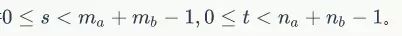
我们可以把上式写成
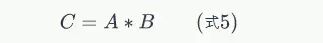
如果我们按照式5来计算卷积,我们可以发现矩阵A实际上是filter,而矩阵B是待卷积的输入,位置关系也有所不同:
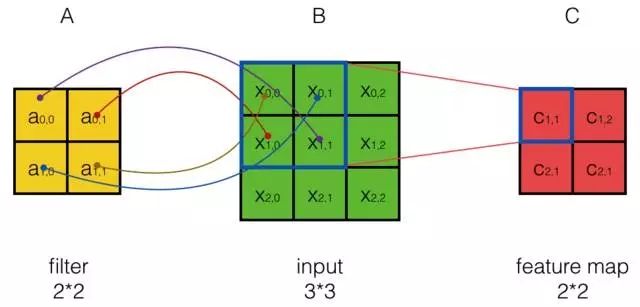
从上图可以看到,A左上角的值a0,0与B对应区块中右下角的值b1,1相乘,而不是与左上角的相乘。因此,数学中的卷积和卷积神经网络中的『卷积』还是有区别的,为了避免混淆,我们把卷积神经网络中的『卷积』操作叫做互相关(cross-correlation)操作。
卷积和互相关操作是可以转化的。首先,我们把矩阵A翻转180度,然后再交换A和B的位置(即把B放在左边而把A放在右边。卷积满足交换率,这个操作不会导致结果变化),那么卷积就变成了互相关。
如果我们不去考虑两者这么一点点的区别,我们可以把式5代入到式4:
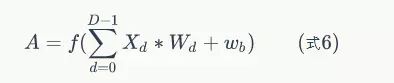
其中,A是卷积层输出的feature map。同式4相比,式6就简单多了。然而,这种简洁写法只适合步长为1的情况。
Pooling层输出值的计算
Pooling层主要的作用是下采样,通过去掉Feature Map中不重要的样本,进一步减少参数数量。Pooling的方法很多,最常用的是Max Pooling。Max Pooling实际上就是在n*n的样本中取最大值,作为采样后的样本值。下图是2*2 max pooling:
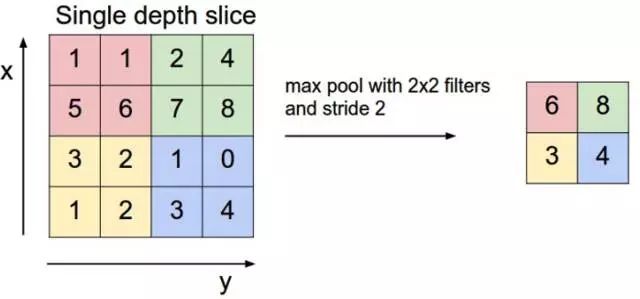
除了Max Pooing之外,常用的还有Mean Pooling——取各样本的平均值。
对于深度为D的Feature Map,各层独立做Pooling,因此Pooling后的深度仍然为D。
四、经典卷积网络模型
1、LeNet-5模型
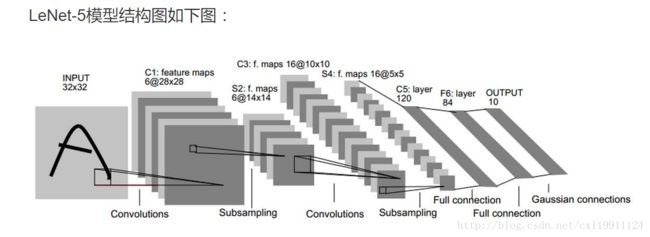
7层结构分别是:
卷积层-池化层-卷积层-池化层-全连接层-全连接层-输出层
1. C1层是一个卷积层
输入图片:32*32
卷积核大小:5*5
卷积核种类:6
输出featuremap大小:28*28 (32-5+1)
神经元数量:28*28*6
可训练参数:(5*5+1)*6(每个滤波器5*5=25个unit参数和一个bias参数,一共6个滤波器)
连接数:(5*5+1)*6*28*28
2. S2层是一个下采样层
输入:28*28
采样区域:2*2
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
采样种类:6
输出featureMap大小:14*14(28/2)
神经元数量:14*14*6
可训练参数:2*6(和的权+偏置)
连接数:(2*2+1)*6*14*14
S2中每个特征图的大小是C1中特征图大小的1/4
3. C3层也是一个卷积层
输入:S2中所有6个或者几个特征map组合
卷积核大小:5*5
卷积核种类:16
输出featureMap大小:10*10
C3中的每个特征map是连接到S2中的所有6个或者几个特征map的,表示本层的特征map是上一层提取到的特征map的不同组合
存在的一个方式是:C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个将S2中所有特征图为输入。
则:可训练参数:6*(3*25+1)+6*(4*25+1)+3*(4*25+1)+(25*6+1)=1516
连接数:10*10*1516=151600
4. S4层是一个下采样层
输入:10*10
采样区域:2*2
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
采样种类:16
输出featureMap大小:5*5(10/2)
神经元数量:5*5*16=400
可训练参数:2*16=32(和的权+偏置)
连接数:16*(2*2+1)*5*5=2000
S4中每个特征图的大小是C3中特征图大小的1/4�
5. C5层是一个卷积层
输入:S4层的全部16个单元特征map(与s4全相连)
卷积核大小:5*5
卷积核种类:120
输出featureMap大小:1*1(5-5+1)
可训练参数/连接:120*(16*5*5+1)=48120
6. F6层全连接层
输入:c5 120维向量
计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数
可训练参数:84*(120+1)=10164
2、Inception-v3模型
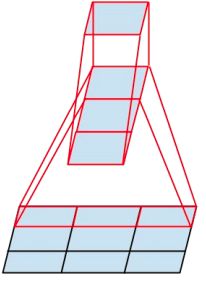
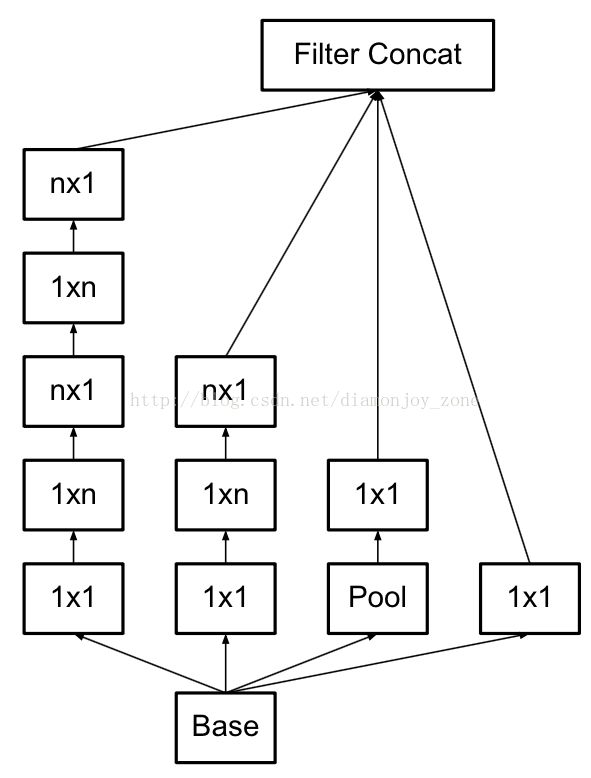

将一个3´3卷积拆成1´3卷积和3´1卷积
一是引入了 Factorization into small convolutions 的思想,将一个较大的二维卷积拆成两个较小的一维卷积,比如将7´7卷积拆成1´7卷积和7´1卷积,或者将3´3卷积拆成1´3卷积和3´1卷积,如上图所示。一方面节约了大量参数,加速运算并减轻了过拟合(比将7´7卷积拆成1´7卷积和7´1卷积,比拆成3个3´3卷积更节约参数),同时增加了一层非线性扩展模型表达能力。论文中指出,这种非对称的卷积结构拆分,其结果比对称地拆为几个相同的小卷积核效果更明显,可以处理更多、更丰富的空间特征,增加特征多样性。
另一方面,Inception V3 优化了 Inception Module 的结构,现在 Inception Module 有35´35、17´17和8´8三种不同结构。这些 Inception Module 只在网络的后部出现,前部还是普通的卷积层。并且 Inception V3 除了在 Inception Module 中使用分支,还在分支中使用了分支(8´8的结构中),可以说是Network In Network In Network。最终取得 top-5 错误率 3.5%。
五、卷积神经网络迁移学习
简单的讲就是将一个在数据集上训练好的卷积神经网络模型通过简单的调整快速移动到另外一个数据集上。
随着模型的层数及模型的复杂度的增加,模型的错误率也随着降低。但是要训练一个复杂的卷积神经网络需要非常多的标注信息,同时也需要几天甚至几周的时间,为了解决标注数据和训练时间的问题,就可以使用迁移学习。
下面的代码就是介绍如何利用ImageNet数据集训练好的inception-v3模型来解决一个新的图像分类问题。其中有论文依据表明可以保留训练好的inception-v3模型中所有卷积层的参数,只替换最后一层全连接层。在最后这一层全连接层之前的网络称为瓶颈层。
原理:在训练好的inception-v3模型中,因为将瓶颈层的输出再通过一个单层的全连接层神经网络可以很好的区分1000种类别的图像,所以可以认为瓶颈层输出的节点向量可以被作为任何图像的一个更具有表达能力的特征向量。于是在新的数据集上可以直接利用这个训练好的神经网络对图像进行特征提取,然后将提取得到的特征向量作为输入来训练一个全新的单层全连接神经网络处理新的分类问题。
一般来说在数据量足够的情况下,迁移学习的效果不如完全重新训练。但是迁移学习所需要的训练时间和训练样本要远远小于训练完整的模型。
这其中说到inception-v3模型,其实它是和LeNet-5结构完全不同的卷积神经网络。在LeNet-5模型中,不同卷积层通过串联的方式连接在一起,而inception-v3模型中的inception结构是将不同的卷积层通过并联的方式结合在一起。
具体细节请参考别处。
案例来源于 《TensorFlow实战Google深度学习框架》
谷歌提供的训练好的Inception-v3模型: https://storage.googleapis.com/download.tensorflow.org/models/inception_dec_2015.zip
案例使用的数据集: http://download.tensorflow.org/example_images/flower_photos.tgz
数据集文件解压后,包含5个子文件夹,子文件夹的名称为花的名称,代表了不同的类别。平均每一种花有734张图片,图片是RGB色彩模式,大小也不相同。
- # -*- coding: utf-8 -*-
- """
- @author: tz_zs
- 卷积神经网络 Inception-v3模型 迁移学习
- """
- import glob
- import os.path
- import random
- import numpy as np
- import tensorflow as tf
- from tensorflow.python.platform import gfile
- # inception-v3 模型瓶颈层的节点个数
- BOTTLENECK_TENSOR_SIZE = 2048
- # inception-v3 模型中代表瓶颈层结果的张量名称
- BOTTLENECK_TENSOR_NAME = 'pool_3/_reshape:0'
- # 图像输入张量所对应的名称
- JPEG_DATA_TENSOR_NAME = 'DecodeJpeg/contents:0'
- # 下载的谷歌训练好的inception-v3模型文件目录
- MODEL_DIR = '/path/to/model/google2015-inception-v3'
- # 下载的谷歌训练好的inception-v3模型文件名
- MODEL_FILE = 'tensorflow_inception_graph.pb'
- # 保存训练数据通过瓶颈层后提取的特征向量
- CACHE_DIR = 'tmp/bottleneck'
- # 图片数据的文件夹
- INPUT_DATA = '/path/to/flower_data'
- # 验证的数据百分比
- VALIDATION_PERCENTAGE = 10
- # 测试的数据百分比
- TEST_PERCENTACE = 10
- # 定义神经网路的设置
- LEARNING_RATE = 0.01
- STEPS = 4000
- BATCH = 100
- # 这个函数把数据集分成训练,验证,测试三部分
- def create_image_lists(testing_percentage, validation_percentage):
- """
- 这个函数把数据集分成训练,验证,测试三部分
- :param testing_percentage:测试的数据百分比 10
- :param validation_percentage:验证的数据百分比 10
- :return:
- """
- result = {}
- # 获取目录下所有子目录
- sub_dirs = [x[0] for x in os.walk(INPUT_DATA)]
- # ['/path/to/flower_data', '/path/to/flower_data\\daisy', '/path/to/flower_data\\dandelion',
- # '/path/to/flower_data\\roses', '/path/to/flower_data\\sunflowers', '/path/to/flower_data\\tulips']
- # 数组中的第一个目录是当前目录,这里设置标记,不予处理
- is_root_dir = True
- for sub_dir in sub_dirs: # 遍历目录数组,每次处理一种
- if is_root_dir:
- is_root_dir = False
- continue
- # 获取当前目录下所有的有效图片文件
- extensions = ['jpg', 'jepg', 'JPG', 'JPEG']
- file_list = []
- dir_name = os.path.basename(sub_dir) # 返回路径名路径的基本名称,如:daisy|dandelion|roses|sunflowers|tulips
- for extension in extensions:
- file_glob = os.path.join(INPUT_DATA, dir_name, '*.' + extension) # 将多个路径组合后返回
- file_list.extend(glob.glob(file_glob)) # glob.glob返回所有匹配的文件路径列表,extend往列表中追加另一个列表
- if not file_list: continue
- # 通过目录名获取类别名称
- label_name = dir_name.lower() # 返回其小写
- # 初始化当前类别的训练数据集、测试数据集、验证数据集
- training_images = []
- testing_images = []
- validation_images = []
- for file_name in file_list: # 遍历此类图片的每张图片的路径
- base_name = os.path.basename(file_name) # 路径的基本名称也就是图片的名称,如:102841525_bd6628ae3c.jpg
- # 随机讲数据分到训练数据集、测试集和验证集
- chance = np.random.randint(100)
- if chance < validation_percentage:
- validation_images.append(base_name)
- elif chance < (testing_percentage + validation_percentage):
- testing_images.append(base_name)
- else:
- training_images.append(base_name)
- result[label_name] = {
- 'dir': dir_name,
- 'training': training_images,
- 'testing': testing_images,
- 'validation': validation_images
- }
- return result
- # 这个函数通过类别名称、所属数据集和图片编号获取一张图片的地址
- def get_image_path(image_lists, image_dir, label_name, index, category):
- """
- :param image_lists:所有图片信息
- :param image_dir:根目录 ( 图片特征向量根目录 CACHE_DIR | 图片原始路径根目录 INPUT_DATA )
- :param label_name:类别的名称( daisy|dandelion|roses|sunflowers|tulips )
- :param index:编号
- :param category:所属的数据集( training|testing|validation )
- :return: 一张图片的地址
- """
- # 获取给定类别的图片集合
- label_lists = image_lists[label_name]
- # 获取这种类别的图片中,特定的数据集(base_name的一维数组)
- category_list = label_lists[category]
- mod_index = index % len(category_list) # 图片的编号%此数据集中图片数量
- # 获取图片文件名
- base_name = category_list[mod_index]
- sub_dir = label_lists['dir']
- # 拼接地址
- full_path = os.path.join(image_dir, sub_dir, base_name)
- return full_path
- # 图片的特征向量的文件地址
- def get_bottleneck_path(image_lists, label_name, index, category):
- return get_image_path(image_lists, CACHE_DIR, label_name, index, category) + '.txt' # CACHE_DIR 特征向量的根地址
- # 计算特征向量
- def run_bottleneck_on_image(sess, image_data, image_data_tensor, bottleneck_tensor):
- """
- :param sess:
- :param image_data:图片内容
- :param image_data_tensor:
- :param bottleneck_tensor:
- :return:
- """
- bottleneck_values = sess.run(bottleneck_tensor, {image_data_tensor: image_data})
- bottleneck_values = np.squeeze(bottleneck_values)
- return bottleneck_values
- # 获取一张图片对应的特征向量的路径
- def get_or_create_bottleneck(sess, image_lists, label_name, index, category, jpeg_data_tensor, bottleneck_tensor):
- """
- :param sess:
- :param image_lists:
- :param label_name:类别名
- :param index:图片编号
- :param category:
- :param jpeg_data_tensor:
- :param bottleneck_tensor:
- :return:
- """
- label_lists = image_lists[label_name]
- sub_dir = label_lists['dir']
- sub_dir_path = os.path.join(CACHE_DIR, sub_dir) # 到类别的文件夹
- if not os.path.exists(sub_dir_path): os.makedirs(sub_dir_path)
- bottleneck_path = get_bottleneck_path(image_lists, label_name, index, category) # 获取图片特征向量的路径
- if not os.path.exists(bottleneck_path): # 如果不存在
- # 获取图片原始路径
- image_path = get_image_path(image_lists, INPUT_DATA, label_name, index, category)
- # 获取图片内容
- image_data = gfile.FastGFile(image_path, 'rb').read()
- # 计算图片特征向量
- bottleneck_values = run_bottleneck_on_image(sess, image_data, jpeg_data_tensor, bottleneck_tensor)
- # 将特征向量存储到文件
- bottleneck_string = ','.join(str(x) for x in bottleneck_values)
- with open(bottleneck_path, 'w') as bottleneck_file:
- bottleneck_file.write(bottleneck_string)
- else:
- # 读取保存的特征向量文件
- with open(bottleneck_path, 'r') as bottleneck_file:
- bottleneck_string = bottleneck_file.read()
- # 字符串转float数组
- bottleneck_values = [float(x) for x in bottleneck_string.split(',')]
- return bottleneck_values
- # 随机获取一个batch的图片作为训练数据(特征向量,类别)
- def get_random_cached_bottlenecks(sess, n_classes, image_lists, how_many, category, jpeg_data_tensor,
- bottleneck_tensor):
- """
- :param sess:
- :param n_classes: 类别数量
- :param image_lists:
- :param how_many: 一个batch的数量
- :param category: 所属的数据集
- :param jpeg_data_tensor:
- :param bottleneck_tensor:
- :return: 特征向量列表,类别列表
- """
- bottlenecks = []
- ground_truths = []
- for _ in range(how_many):
- # 随机一个类别和图片编号加入当前的训练数据
- label_index = random.randrange(n_classes)
- label_name = list(image_lists.keys())[label_index] # 随机图片的类别名
- image_index = random.randrange(65536) # 随机图片的编号
- bottleneck = get_or_create_bottleneck(sess, image_lists, label_name, image_index, category, jpeg_data_tensor,
- bottleneck_tensor) # 计算此图片的特征向量
- ground_truth = np.zeros(n_classes, dtype=np.float32)
- ground_truth[label_index] = 1.0
- bottlenecks.append(bottleneck)
- ground_truths.append(ground_truth)
- return bottlenecks, ground_truths
- # 获取全部的测试数据
- def get_test_bottlenecks(sess, image_lists, n_classes, jpeg_data_tensor, bottleneck_tensor):
- bottlenecks = []
- ground_truths = []
- label_name_list = list(image_lists.keys()) # ['dandelion', 'daisy', 'sunflowers', 'roses', 'tulips']
- for label_index, label_name in enumerate(label_name_list): # 枚举每个类别,如:0 sunflowers
- category = 'testing'
- for index, unused_base_name in enumerate(image_lists[label_name][category]): # 枚举此类别中的测试数据集中的每张图片
- '''''
- print(index, unused_base_name)
- 0 10386503264_e05387e1f7_m.jpg
- 1 1419608016_707b887337_n.jpg
- 2 14244410747_22691ece4a_n.jpg
- ...
- 105 9467543719_c4800becbb_m.jpg
- 106 9595857626_979c45e5bf_n.jpg
- 107 9922116524_ab4a2533fe_n.jpg
- '''
- bottleneck = get_or_create_bottleneck(
- sess, image_lists, label_name, index, category, jpeg_data_tensor, bottleneck_tensor)
- ground_truth = np.zeros(n_classes, dtype=np.float32)
- ground_truth[label_index] = 1.0
- bottlenecks.append(bottleneck)
- ground_truths.append(ground_truth)
- return bottlenecks, ground_truths
- def main(_):
- image_lists = create_image_lists(TEST_PERCENTACE, VALIDATION_PERCENTAGE)
- n_classes = len(image_lists.keys())
- # 读取模型
- with gfile.FastGFile(os.path.join(MODEL_DIR, MODEL_FILE), 'rb') as f:
- graph_def = tf.GraphDef()
- graph_def.ParseFromString(f.read())
- # 加载模型,返回对应名称的张量
- bottleneck_tensor, jpeg_data_tensor = tf.import_graph_def(graph_def, return_elements=[BOTTLENECK_TENSOR_NAME,
- JPEG_DATA_TENSOR_NAME])
- # 输入
- bottleneck_input = tf.placeholder(tf.float32, [None, BOTTLENECK_TENSOR_SIZE], name='BottleneckInputPlaceholder')
- ground_truth_input = tf.placeholder(tf.float32, [None, n_classes], name='GroundTruthInput')
- # 全连接层
- with tf.name_scope('final_training_ops'):
- weights = tf.Variable(tf.truncated_normal([BOTTLENECK_TENSOR_SIZE, n_classes], stddev=0.001))
- biases = tf.Variable(tf.zeros([n_classes]))
- logits = tf.matmul(bottleneck_input, weights) + biases
- final_tensor = tf.nn.softmax(logits)
- # 损失
- cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=ground_truth_input)
- cross_entropy_mean = tf.reduce_mean(cross_entropy)
- # 优化
- train_step = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(cross_entropy_mean)
- # 正确率
- with tf.name_scope('evaluation'):
- correct_prediction = tf.equal(tf.argmax(final_tensor, 1), tf.argmax(ground_truth_input, 1))
- evaluation_step = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
- with tf.Session() as sess:
- # 初始化参数
- init = tf.global_variables_initializer()
- sess.run(init)
- for i in range(STEPS):
- # 每次获取一个batch的训练数据
- train_bottlenecks, train_ground_truth = get_random_cached_bottlenecks(sess, n_classes, image_lists, BATCH,
- 'training', jpeg_data_tensor,
- bottleneck_tensor)
- # 训练
- sess.run(train_step,
- feed_dict={bottleneck_input: train_bottlenecks, ground_truth_input: train_ground_truth})
- # 验证
- if i % 100 == 0 or i + 1 == STEPS:
- validation_bottlenecks, validation_ground_truth = get_random_cached_bottlenecks(sess, n_classes,
- image_lists, BATCH,
- 'validation',
- jpeg_data_tensor,
- bottleneck_tensor)
- validation_accuracy = sess.run(evaluation_step, feed_dict={bottleneck_input: validation_bottlenecks,
- ground_truth_input: validation_ground_truth})
- print('Step %d: Validation accuracy on random sampled %d examples = %.1f%%' % (
- i, BATCH, validation_accuracy * 100))
- # 测试
- test_bottlenecks, test_ground_truth = get_test_bottlenecks(sess, image_lists, n_classes, jpeg_data_tensor,
- bottleneck_tensor)
- test_accuracy = sess.run(evaluation_step,
- feed_dict={bottleneck_input: test_bottlenecks, ground_truth_input: test_ground_truth})
- print('Final test accuracy = %.1f%%' % (test_accuracy * 100))
- if __name__ == '__main__':
- tf.app.run()
- '''''
- Step 0: Validation accuracy on random sampled 100 examples = 40.0%
- Step 100: Validation accuracy on random sampled 100 examples = 81.0%
- Step 200: Validation accuracy on random sampled 100 examples = 79.0%
- Step 300: Validation accuracy on random sampled 100 examples = 92.0%
- Step 400: Validation accuracy on random sampled 100 examples = 90.0%
- Step 500: Validation accuracy on random sampled 100 examples = 88.0%
- Step 600: Validation accuracy on random sampled 100 examples = 89.0%
- Step 700: Validation accuracy on random sampled 100 examples = 94.0%
- Step 800: Validation accuracy on random sampled 100 examples = 91.0%
- Step 900: Validation accuracy on random sampled 100 examples = 88.0%
- Step 1000: Validation accuracy on random sampled 100 examples = 84.0%
- Step 1100: Validation accuracy on random sampled 100 examples = 92.0%
- Step 1200: Validation accuracy on random sampled 100 examples = 86.0%
- Step 1300: Validation accuracy on random sampled 100 examples = 91.0%
- Step 1400: Validation accuracy on random sampled 100 examples = 96.0%
- Step 1500: Validation accuracy on random sampled 100 examples = 89.0%
- Step 1600: Validation accuracy on random sampled 100 examples = 94.0%
- Step 1700: Validation accuracy on random sampled 100 examples = 90.0%
- Step 1800: Validation accuracy on random sampled 100 examples = 94.0%
- Step 1900: Validation accuracy on random sampled 100 examples = 94.0%
- Step 2000: Validation accuracy on random sampled 100 examples = 94.0%
- Step 2100: Validation accuracy on random sampled 100 examples = 93.0%
- Step 2200: Validation accuracy on random sampled 100 examples = 92.0%
- Step 2300: Validation accuracy on random sampled 100 examples = 96.0%
- Step 2400: Validation accuracy on random sampled 100 examples = 92.0%
- Step 2500: Validation accuracy on random sampled 100 examples = 92.0%
- Step 2600: Validation accuracy on random sampled 100 examples = 93.0%
- Step 2700: Validation accuracy on random sampled 100 examples = 90.0%
- Step 2800: Validation accuracy on random sampled 100 examples = 92.0%
- Step 2900: Validation accuracy on random sampled 100 examples = 91.0%
- Step 3000: Validation accuracy on random sampled 100 examples = 96.0%
- Step 3100: Validation accuracy on random sampled 100 examples = 90.0%
- Step 3200: Validation accuracy on random sampled 100 examples = 94.0%
- Step 3300: Validation accuracy on random sampled 100 examples = 97.0%
- Step 3400: Validation accuracy on random sampled 100 examples = 95.0%
- Step 3500: Validation accuracy on random sampled 100 examples = 92.0%
- Step 3600: Validation accuracy on random sampled 100 examples = 94.0%
- Step 3700: Validation accuracy on random sampled 100 examples = 94.0%
- Step 3800: Validation accuracy on random sampled 100 examples = 95.0%
- Step 3900: Validation accuracy on random sampled 100 examples = 95.0%
- Step 3999: Validation accuracy on random sampled 100 examples = 94.0%
- Final test accuracy = 95.4%
- '''
将一个3´3卷积拆成1´3卷积和3´1卷积
一是引入了 Factorization into small convolutions 的思想,将一个较大的二维卷积拆成两个较小的一维卷积,比如将7´7卷积拆成1´7卷积和7´1卷积,或者将3´3卷积拆成1´3卷积和3´1卷积,如上图所示。一方面节约了大量参数,加速运算并减轻了过拟合(比将7´7卷积拆成1´7卷积和7´1卷积,比拆成3个3´3卷积更节约参数),同时增加了一层非线性扩展模型表达能力。论文中指出,这种非对称的卷积结构拆分,其结果比对称地拆为几个相同的小卷积核效果更明显,可以处理更多、更丰富的空间特征,增加特征多样性。
另一方面,Inception V3 优化了 Inception Module 的结构,现在 Inception Module 有35´35、17´17和8´8三种不同结构。这些 Inception Module 只在网络的后部出现,前部还是普通的卷积层。并且 Inception V3 除了在 Inception Module 中使用分支,还在分支中使用了分支(8´8的结构中),可以说是Network In Network In Network。最终取得 top-5 错误率 3.5%。