语音信号处理基础(二)
语音信号处理基础(二)
1.2.2 语音编码
语音编码的目的
保证在一定语音质量的前提下,尽可能降低编码比特率,以节省频率资源。
语音编码技术的鼻祖:
研究开始于1939年军事保密通信的需要,贝尔电话实验室的Homer Dudley提出并实现了在低频带宽电话电报电缆上传输语音信号的通道声码器。
20世纪70年代:国际电联(ITU-T,原CCITT(国际电话电报谘询委员会))64kbit/s脉冲编码调制(PCM)语音编码算法的G.711建议,它被广泛应用于数字通信、数字交换机等领域。
1980年:美国政府公布了一种2.4kbit/s的线性预测编码标准算法LPC-10,这使得在普通电话带宽中传输数字电话成为可能。
ITU-T也于20世纪80年代初着手研究低于64kbit/s的非PCM编码算法,1984年通过了32kbit/s ADPCM语音编码G.721建议,它不仅可以达到与PCM相同的语音质量,而且具有更优良的抗误码性能。1988年美国又公布了一个4.8kbit/s的码激励线性预测(CELP)编码算法。与此同时,欧洲也推出了一个16kbit/s的规则脉冲激励线性预测(RPE-LPC)编码算法。
20世纪90年代:随着因特网在全球范围的兴起,人们对能在网络上传输语音的VoIP技术兴趣大增,由此,IP分组语音通信技术获得了突破性进展和实际应用。
20世纪90年代中期到现在,第三代移动通信技术逐渐成熟并走向商用,变速率语音编码和带宽语音编码得到了迅速的发展,不断有新的国际标准和地区标准公布。
语音编码技术主要有两个努力的方向:
一个是中低速率的语音编码的实用化及如何在实用化过程中进一步提高其抗干扰、抗噪声的能力;
另一个是如何进一步降低其编码速率。
1.2.3 语音识别
与机器进行语音交流,让机器明白你说什么。而语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令。
根据在不同限制条件下的研究任务,产生了不同的研究研究领域。这些领域包括:
- 根据对说话人说话方式的要求,可以分为
孤立字语音识别系统
连续字语音识别系统
连续语音识别系统
- 根据对说话人的依赖程度可以分为
特定人语音识别系统
非特定人语音识别系统
- 根据词汇量大小,可以分为
小词汇量语音识别系统
中等词汇量语音识别系统
大词汇量语音识别系统
无限词汇量语音识别系统
语音识别发展历程:
20世纪50年代:AT&T贝尔实验室的Audry系统,它是第一个可以识别10个英语数字的语音识别系统。
1956年:RAC实验室的Olson等人也独立地研制出了10个单音节词的识别系统,系统采用从带通滤波器组获得的频谱参数作为语音的特征。
1959年:Fry和Denes等人采用频谱分析和模式匹配进行识别决策构建音素识别器来辨别4个元音和9个辅音。MIT林肯实验室采用声道的时变估计技术研究10个元音的识别
20世纪60年代末:重要成果是提出了动态规划(DP)(是对解最优化问题的一种途径、一种方法,而不是一种特殊算法。)和线性预测编码(LPC)分析技术,其中后者较好地解决了语音信号产生模型的问题,对整个语音识别、语音合成、语音分析、语音编码的研究发展产生了深远影响。
20世纪70年代:在理论上,LPC技术得到进一步发展,动态时间规整(DTW)技术基本成熟,特别是提出了矢量量化(VQ)和隐马尔可夫模型(HMM)理论。在实践上,首先在孤立词识别方面,由日本学者Sakoe给出了使用动态规划方法(DP)进行语音识别的途径——DP算法。Itakura基于语音编码中广泛使用的LPC技术,通过定义基于LPC频谱参数的合适的距离测度,成功地将其应用到语音识别中。同时,以IBM为首的一些语音研究单位还着手开展了连续语音识别的研究。
20世纪70年代末到20世纪80年代初:Linda、Buzo、Gray等人解决了矢量量化码本生成的方法,并将矢量量化成功地应用到语音编码中,从此矢量量化技术很快被推广应用到其他领域。
20世纪80年代开始:语音识别研究进一步走向深入,就是识别算法从模式匹配技术转向基于统计模型的技术,更多地追求从整体统计的角度来建立最佳的语音识别系统。HMM技术就是其中的一个典型技术。
20世纪80年代中期:重新开始的人工神经网络(ANN)研究,也给语音识别带来一片新的生机。
20世纪90年代初期:许多发达国家如美国、日本以及IBM、Apple、AT&T、NTT等著名公司都为语音识别系统的实用化开发研究投以巨资。
如今,深度神经网络(DNN)在语音领域的应用,使得语音识别性能又上了一个新的台阶。
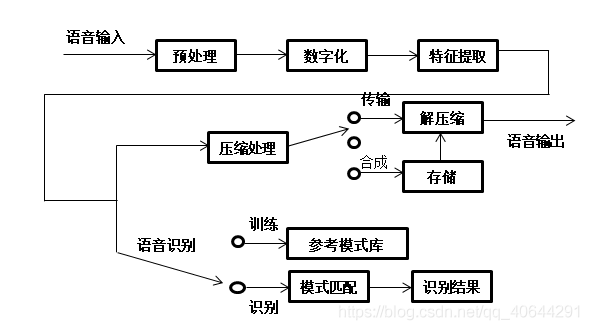
1.3 语音信号处理过程的总体结构
名词解释
PCM(脉冲编码调制)
脉冲编码调制 (Pulse Code Modulation)是一种对模拟信号数字化的取样技术,将模拟语音信号变换为数字信号的编码方式。利用脉冲序列对连续信号进行抽样产生的信号称为脉冲幅度调制信号。这一过程的实质是把连续信号转换为脉冲序列,而每个脉冲的幅度与个抽样点信号的幅度成正比。
脉冲编码调制主要经过3个过程:抽样、量化和编码。抽样过程将连续时间模拟信号变为离散时间、连续幅度的抽样信号,量化过程将抽样信号变为离散时间、离散幅度的数字信号,编码过程将量化后的信号编码成为一个二进制码组输出。
LPC(线性预测编码)
线性预测编码(LPC)是主要用于音频信号处理与语音处理中根据线性预测模型的信息用压缩形式表示数字语音信号谱包络(spectral envelope)的工具。它是最有效的语音分析技术之一,也是低位速下编码方法高质量语音最有用的方法之一,它能够提供非常精确的语音参数预测。
线性预测编码通过估计共振峰、剔除它们在语音信号中的作用、估计保留的蜂鸣音强度与频率来分析语音信号。剔除共振峰的过程称为逆滤波,经过这个过程剩余的信号称为残余信号(residue)。
共振峰的概念在前一节提过
码激励线性预测(CELP)编码算法
它由欧洲通信标准协会(ETSI)制定。 CELP语音编码算法用线性预测提取声道参数,用一个包含许多典型的激励矢量的码本作为激励参数,每次编码时都在这个码本中搜索一个最佳的激励矢量,这个激励矢量的编码值就是这个序列的码本中的序号。
其特点是改善语音的质量:
① 对误差信号进行感觉加权,利用人类听觉的掩蔽特性来提高语音的主观质量;
②用分数延迟(延迟间隔为采样间隔的整数倍)改进基音预测,使浊音的表达更为准确,尤其改善了女性语音的质量;
③ 使用修正的MSPE(纯均方误差)准则来寻找 “最佳”的延迟,使得基音周期延迟的外形更为平滑;
④根据长时预测的效率,调整随机激励矢量的大小,提高语音的主观质量;
⑤ 使用基于信道错误率估计的自适应平滑器,在信道误码率较高的情况下也能合成自然度较高的语音。
规则脉冲激励线性预测(RPE-LPC)编码算法
规则脉冲是多脉冲的一种,即脉冲间隔固定的多脉冲激励。对于规则脉冲激励,算法可以简化。其结构图如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LqH58doQ-1572442798431)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20191029165019826.png)]
规则脉冲是让原始语音经短时滤波后的信号r(n)与激励信号作差,然后对感觉加权后的差值信号求均方误差最小来确定最佳激励。
规则脉冲激励的问题是
A、确定规则脉冲最佳的相位
B、为每个非零脉冲确定一个幅度。
VOIP技术
基于IP的语音传输(Voice over Internet Protocol)是一种语音通话技术
VoIP的基本原理是通过语音的压缩算法对语音数据编码进行压缩处理,然后把这些语音数据按 TCP/IP 标准进行打包,经过 IP 网络把数据包送至接收地,再把这些语音数据包串起来,经过解压处理后,恢复成原来的语音信号,从而达到由互联网传送语音的目的。
矢量量化(VQ)
将k个样点构成的有序集(信源矢量集合)映射为M个恢复失量构成的有限集A(码书,码本)中的某个矢量Yi(码字,码元)的映射,为矢量量化,它是对标量量化在K维空间的一个推广。在传统的预测和变换编码中,首先将信号经某种映射变换变成一个数的序列,然后对其一个一个地进行标量量化编码。而在矢量量化编码中,则是把输入数据几个一组地分成许多组,成组地量化编码,即将这些数看成一个k维矢量,然后以矢量为单位逐个矢量进行量化。
隐马尔可夫模型(HMM)理论
参考文献
[1]陈彩莲,于宏毅,罗柏文, 等.一种灵活高效的分数延迟数字滤波器[J].信息工程大学学报,2009,10(4):457-460. DOI:10.3969/j.issn.1671-0673.2009.04.008.
[2]罗丽.计算机语音信号处理与语音识别系统分析[J].数字化用户,2019,25(14):78.