【深度学习】深度学习分类与模型评估
内容大纲
- 分类和回归之外的机器学习形式
- 评估机器学习模型的规范流程
- 为深度学习准备数据
- 特征工程
- 解决过拟合问题
- 处理机器学习问题的通用流程
监督学习的主要种类及其变种
主要包括两大类问题:
- 分类
- 回归
变种问题主要有:
- 序列生成:给定一张图像,输出描述图像的文字;可以被重新表示为分类问题
- 语法树预测:给定一个句子,输出其分解生成的语法树
- 目标检测:给定一张图像,在图中的目标周围绘制一个边界框;可以被表示为分类问题,或者分类与回归联合问题
- 图像分割:给定图像,在特定的物体上画一个像素级别的mask
无监督学习
不给定目标值,模型需要从输入数据中寻找到有价值的变换,常常用来做数据可视化,数据压缩,数据去噪或者辅助我们更好理解数据中的相关性等。
无监督学习是数据分析的必备技能。
为了更好的理解数据集,无监督学习是一个必要步骤。比如降维和聚类分析方法。
自监督学习
这个是监督学习的一个特例。它的特殊之处在于没有人工标注的标签,但是标签仍然存在,而这些标签是如何生成的呢?它们来自输入数据,常常用启发式算法来生成。
强化学习
智能体接收有关环境的信息,并学会选择使得奖励函数最大化的动作。
部分术语解析
- 二分类:每个输入样本被划分到两个互斥的类别之一
- 多分类:每个输入样本被划分到两个以上的类别之一,如手写体数字分类
- 多标签分类:每个输入样本都可以被划分到多个标签,如图像标注任务
- 标量回归:输出一个标量,连续值
- 向量回归:输出一组连续值的任务,比如输出图像中物体的边界框
- 小批量,批量:模型同时处理的一部分样本,通常取2的幂,便于GPU分配内存
模型评估
训练集,验证集和测试集
三者的具体分工是:在训练集上训练模型,在验证集上评估模型以及在测试集上最后测试。
在验证集上可以调节超参数,比如前面训练时,我们用验证集上的效果来得出训练多少轮次合适,这就是超参数选择的过程。调节模型时,是万万不能用到测试集的,测试集就像最后的高考,验证集则是月考,训练集则是我们平时的作业。
三种经典的评估方法
- 留出验证
- K折验证
- 含打乱数据的重复验证
留出验证
即留出一定比例的数据作为测试集,为了调节模型我们还需要从训练集中拿出一部分数据做验证集。
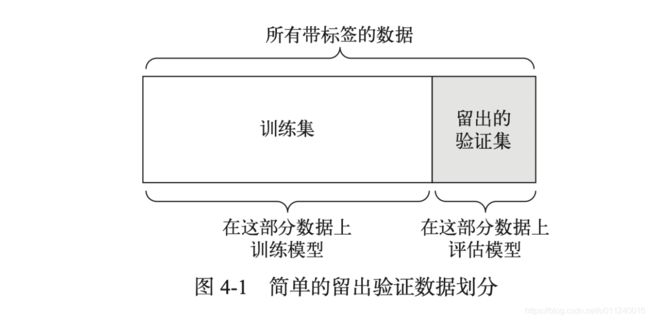
这个图只表达了划分出两部分数据,训练集里还要再细分出一部分数据做验证,本质上,验证集也是训练调节模型,大类仍可归于训练集。
num_validation_samples = 10000
np.random.shuffle(data) # 打乱数据
validation_data = data[:num_validation_samples] # 验证集
train_data = data[num_validation_samples:]
model = build_model()
model.fit(train_data, train_targets)
validation_score = model.evaluate(validation_data) # 验证集上评估模型并得出最优超参数
# 找到最优超参数,重新训练
model = build_model()
model.fit(np.concatenate([train_data, validation_data], train_targets)
test_score = model.evaluate(test_data)
在知晓超参数以后,重新训练模型时,验证集数据也作为训练集数据,这样可以更好的训练模型。
这个验证方法不适用于样本数据量较少的情况。
K折验证

这个一图就说明白了,但还是需要特别强调一下,这里的数据确定后是个整体,当然之前可以先打乱使得分布均匀。然后砍成一段一段的,拼在一起就是完整的数据集。之所以这么强调,是为了和下面的打乱随机K折验证区分一下。
k = 3
num_validation_samples = len(data) // k
np.random.shuffle(data)
validation_scores = [] # 每一折得出一个验证分数
for fold in range(k):
validation_data= data[num_validation_samples * fold: num_validation_samples * (fold + 1)]
train_data = data[:num_validation_samples * fold] + data[num_validation_samples * (fold + 1):]
model = build_model()
model.fit(train_data)
validation_score = model.evaluate(validation_data)
validation_scores.append(validation_score)
validation_score = np.average(validation_scores)
model = build_model()
model.fit(data)
test_score = model.evaluate(test_data)
包含打乱数据的重复K折验证
一句话描述就是,多次使用上面的K折验证,每次都打乱数据一下。假设重复P次,那么需要训练和评估的模型个数是PxK个,这种做法代价很大,但是效果很好,在Kaggle比赛里很有用。
评估模型的注意事项
数据代表性
将数据随机打乱,可以使得训练集和测试集都能代表当前数据。
时间箭头
如果是用过去数据来预测未来,则不能随机打乱数据,否则会导致时间泄露问题。
数据冗余
我们需要保证训练集和验证集之间不存在交集。
数据预处理,特征工程,特征学习
在具体使用模型之前,需要耗费很大精力来处理数据。
数据预处理
针对神经网络,我们将数据处理得更加适用于神经网络处理。主要包括如下几种方法:
- 向量化
- 标准化
- 缺失值处理
- 特征提取
特征工程
通常机器学习模型无法从完全任意的数据中学习。所以我们需要利用先验知识对数据进行编码转换,以改善模型的效果。
特征工程的本质是:用更简单的方式表述问题,使得问题更加容易解决。这需要我们深入理解问题。
现代深度学习,大部分特征工程是不需要的。神经网络可以从原始数据中自动提取有用特征。但是并不表示深度神经网络不需要特征工程。使用特征工程,一方面可以用更少的资源解决问题,另一方面,定义良好的特征可以更少的数据解决问题。样本很少时,恰当的特征工程价值极大。
处理过拟合和欠拟合问题
欠拟合表示模型仍有改进的空间,还需要继续训练,所以这个问题不大,更需要特别设计解决的是过拟合问题。降低过拟合的方法叫作正则化。常用的正则化的方法有:
- 减小网络大小
- 添加权重正则化
- L1
- L2
- 添加dropout正则化
减小网络大小
这是防止过拟合的最简单的方法,通过减少模型的学习参数个数。
**模型容量:**可学习参数的个数。
深度学习模型通常都很擅长拟合训练数据,但是真正的挑战在于泛化,而不是拟合。
更大的网络的训练损失容易很快就接近0,即网络的容量越大,则拟合数据的速度就越快,也就容易过拟合。
添加权重正则化
from keras import regularizers
model = models.Sequential()
model.add(layers.Dense(16, kernel_regularizer=regularizers.l2(0.001), activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, kernel_regularizer=regularizers.l2(0.001), activation='relu'))
model.add(layers.Dense(1, kernel_regularizer=regularizers.l2(0.001), activation='relu'))
其中,l2(0.001)的意思是:该层权重矩阵的每个系数都会使网络总损失增加0.001 * weight_coefficient_calue,惩罚项只在训练时添加,测试时不计算,所以训练损失会大于测试损失。
添加dropout正则
这是训练神经网络最有效也最常用的方法。对某一层使用dropout,会在训练过程中随机将该层的一些输出特征置为0。设置的dropout比率是元素被设置为0的比例。测试时没有单元会被舍弃。
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
深度学习流程
这部分再单独写一篇笔记,之前也写过一次。
END.
参考:
《Deep Learning with Python》