Kafka Tool 2.0.7(最新)版本超详细使用指北
Kafka Tool 2.0.7版本使用指北
本篇博客要点如下:
Kafka Tool 2.0.7下载安装
Kafka Tool 2.0.7参数优化及连接Kafka集群
- Kafka Tool 2.0.7参数优化
- 使用Kafka Tool查看Broker信息
Kafka Tool 2.0.7操作指北
- Kafka Tool功能简介
- 使用Kafka Tool查看Broker信息
- 使用Kafka Tool查看和管理Topic
- 使用Kafka Tool查看和管理Consumer
案例: 使用Kafka Tool排查定位生产问题
一. Kafka Tool 2.0.7下载安装
下载:
Kafka Tool下载链接:
根据操作系统和Kafka版本选择合适的安装包:
注意 : Kafka 0.10及之前版本请选择 Kafka Tool 1.0.3
我的操作系统是windows64位,生产环境的Kafka版本是2.1.1
所以下载下图所示的安装包
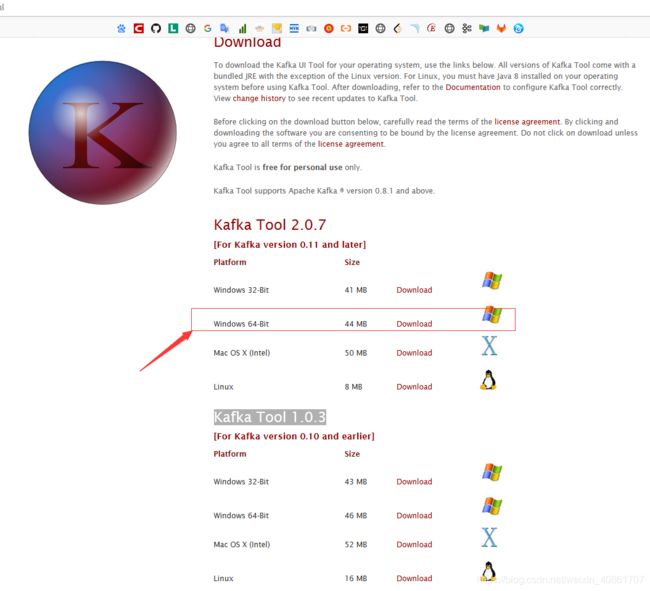 安装:
安装:
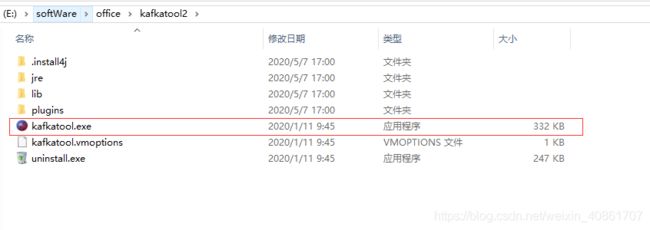
安装过程十分简单,一路next即可(记得更改默认安装路径,保持良好习惯)
安装后目录结构如下图所示,双击kafkatool.exe文件启动Kafka Tool工具
二. Kafka Tool 2.0.7参数优化及连接Kafka集群
2.1 参数优化(可选项)
正式连接Kafka集群前,需要对工具的JVM参数进行配置(根据实际情况)
编辑kafkatool.vmoptions文件
设置参数
-Xmx4096m # 最大堆内存
-Xms4096m # 最小堆内存

原因 : 我们生产环境的数据量相对较大,查询Kafka集群数据时需要更大的内存来避免频繁的垃圾回收或者内存溢出
同时,设置最大堆内存和最小堆内存相同,避免垃圾回收完成后JVM重新分配内存
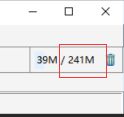
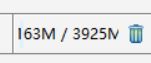
通过两张图片参数修改后工具的差别:
修改前:
修改后:
注意:这里也不要修改的过大,不然机器内存不足,会导致工具无法正常使用!
2.2 连接Kafka集群
-
双击kafkatool.exe文件启动Kafka Tool工具
-
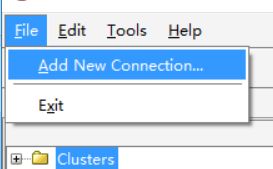
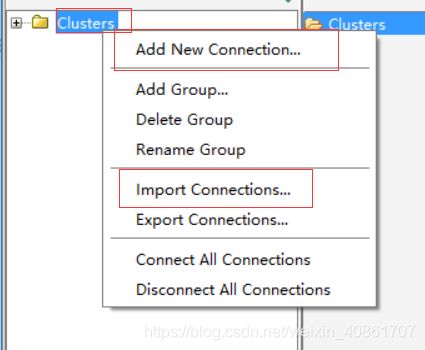
File–> Add New Connection 或者右键Clusters–> Add New Connection创建新的连接,如下图所示:
-
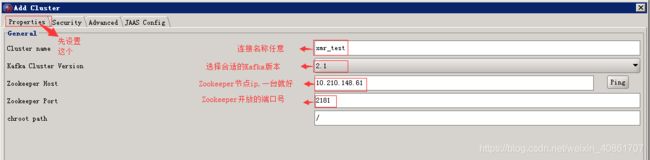
配置连接信息,如下图所示
首先配置Properties
 接下来配置Advanced
接下来配置Advanced
 配置成功后,点击add
配置成功后,点击add -
连接集群
选择刚刚添加的连接,点击界面右下方的connect按钮
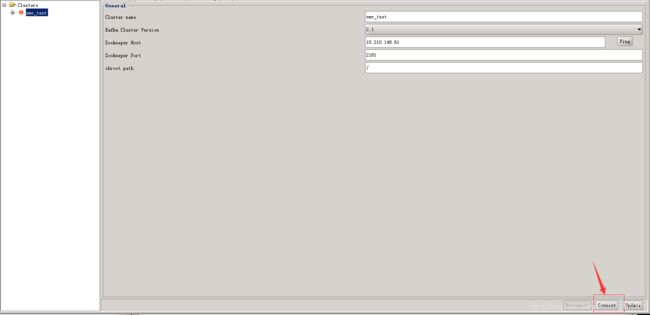 连接框变为绿色,证明连接成功!
连接框变为绿色,证明连接成功!
三. Kafka Tool 2.0.7操作指北
3.1 Kafka Tool 功能简介
以下内容来自官网翻译:
Kafka工具是用于管理和使用Apache Kafka集群的GUI应用程序。
它提供了一种直观的UI,可让用户快速查看Kafka集群中的对象以及集群主题中存储的消息。
它包含面向开发人员和管理员的功能。
主要功能如下:
1. 快速查看所有的Kafka集群,包括: brokers,topics,consumers
2. 查看分区中的内容并添加新消息
3. 查看消费者的偏移量
4. 以漂亮的格式展示Json和XML消息
5. 添加删除主题,以及其它管理功能
6. 将单个消息从集群分区保存到本地
7. 编写自己的插件,可以自定义数据格式
8. Kafka工具可以在包括Windows,Linux和Mac OS等系统上运行
3.2 使用Kafka Tool查看Broker信息
如下图所示,点开我们之前获取到的连接
可以查看集群broker的ID,Host和Port信息

3.3 使用Kafka Tool查看和管理Topic
查看topic整体信息
任意选择一个topic
在Properties里,你能够获取到该topic的总偏移量,key和消息的类型
如下图所示:
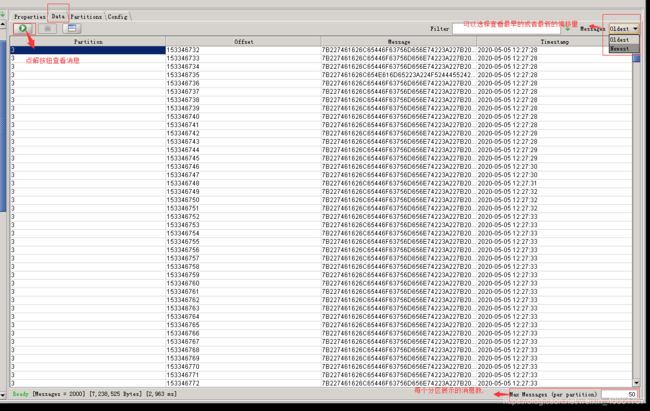
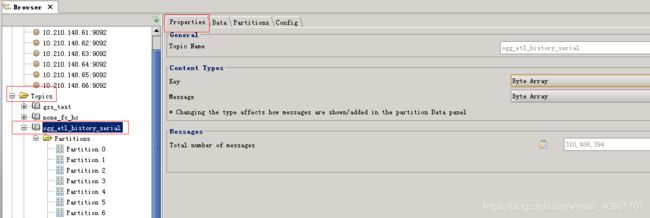 通过Data查看topic的数据(会将二进制的消息转换成我们能看懂的格式),可以选择查询最早或者最新偏移量的数据,并指定每个分区显示的条数
通过Data查看topic的数据(会将二进制的消息转换成我们能看懂的格式),可以选择查询最早或者最新偏移量的数据,并指定每个分区显示的条数
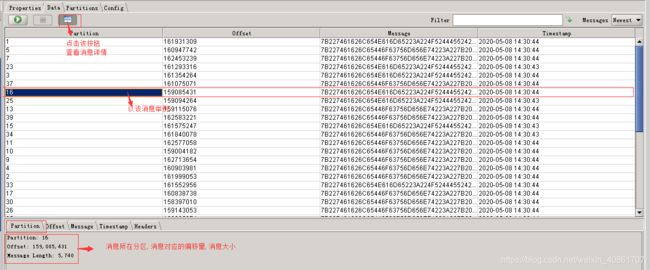
在这里,我们还可以看到每条消息的详细信息,如下图:
我们可以看到,每条消息所在分区,对应偏移量,消息大小,消息的时间戳,以及消息的原始值(我这里是二进制的)
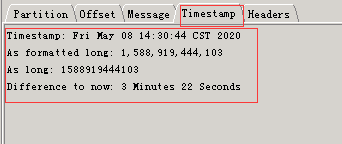
 时间戳信息:
时间戳信息:
原始消息内容:
这里我们可以点击下图所示的按钮,将集群的消息下载到本地
![]()
设置好下载路径和文件名,点击保存按钮,即可!
下载好的内容如下图所示:
可以看到,在集群中存储为二进制的数据,下载到本地是很好的json格式
这个功能还是很实用的!

查看topic具体分区信息
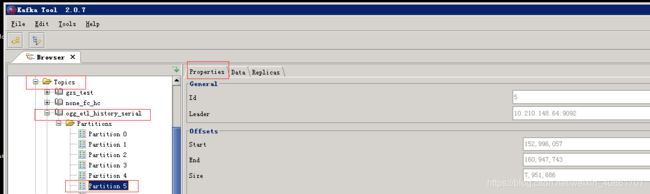
我们以上文中列举的topic的分区5为例
Properties包括: 分区的id,分区的leader,起始偏移量,截止偏移量,分区大小等信息
Replicas包括每个副本集的broker信息,以及每个副本是否同步,如下图所示:
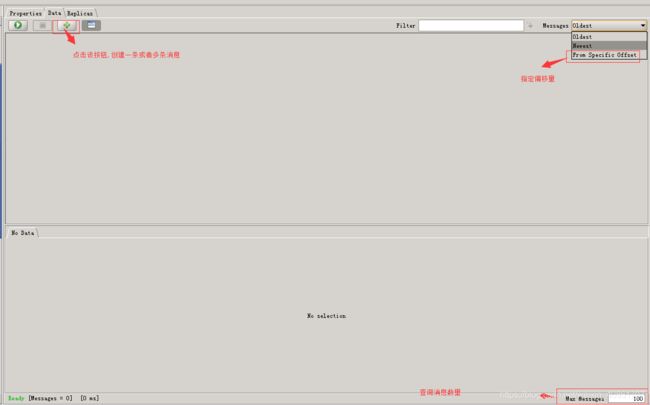
 Data包含如下内容查看消息,添加消息等,具体细节如下图:
Data包含如下内容查看消息,添加消息等,具体细节如下图:
和Topic下的Data有所区别,不同的地方在下图中用红线标出
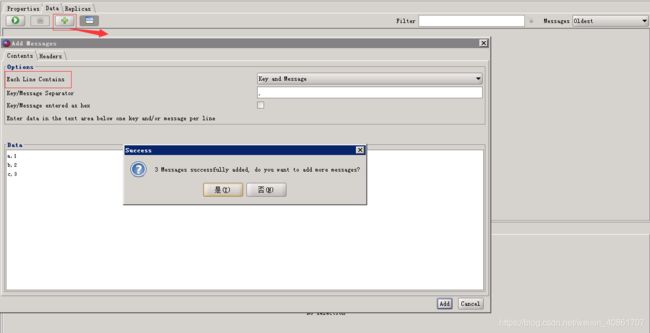
为分区增加消息
1. 点击Data下面的 + 按钮
2. 弹出框选择Add Multiple Message
3. 设置消息配置选项(每行内容,key.message分隔符,以及是否使用16进制)
4. Data文本框按格式输入要添加消息
5. 点击add按钮添加消息
具体操作如下图所示:
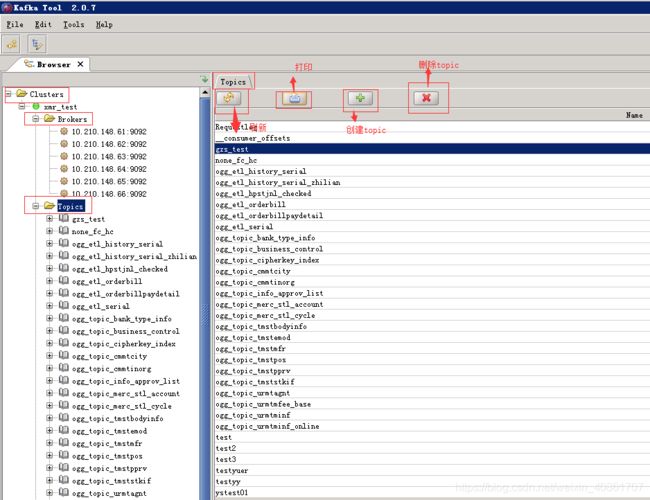
添加和删除topic
点击界面左侧的Topics,在界面右侧的弹出框中包括刷新,打印,创建topic,删除topic
具体操作如下图:
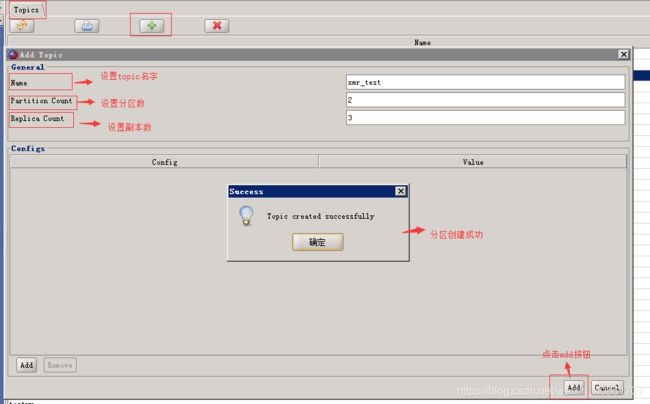
添加topic
1. 点击Topics里的 + 按钮
2. 设置topic信息(名字,分区数,副本数)
3. 点击add按钮
4. topic创建成功
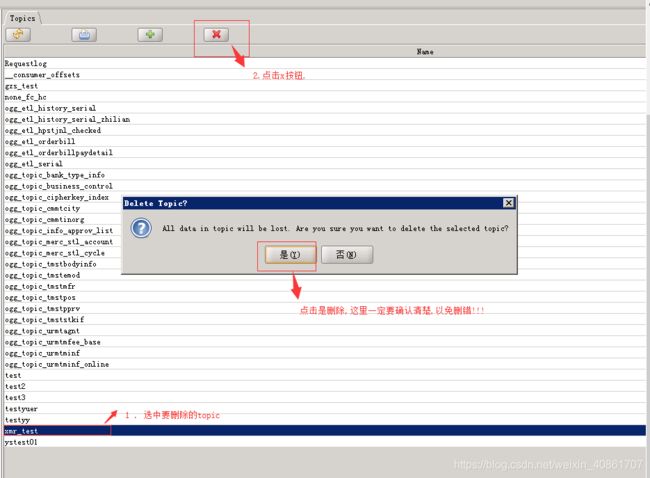
删除topic
1. 选中要删除的topic
2. 点击×按钮
3. 弹出来的提示框中选择是
4. topic删除
删除操作一定要慎重!请仔细确认!!!
删除操作一定要慎重!请仔细确认!!!
删除操作一定要慎重!请仔细确认!!!
具体操作如下图所示:
3.4 使用Kafka Tool查看和管理Consumer
界面左侧点击Consumers可以看到该集群的所有消费者组
在下面列出来的消费者组中,随便点击一个
右侧会出现包含Properties和Offsets选项的界面
Properties包含如下内容:
消费者组(组名)Id,消费者类型,偏移量存储位置
如下图:
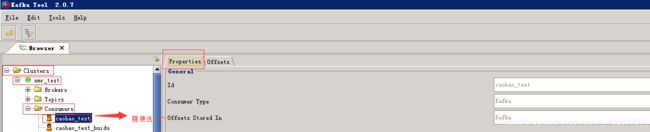 Offsets包含如下信息:
Offsets包含如下信息:
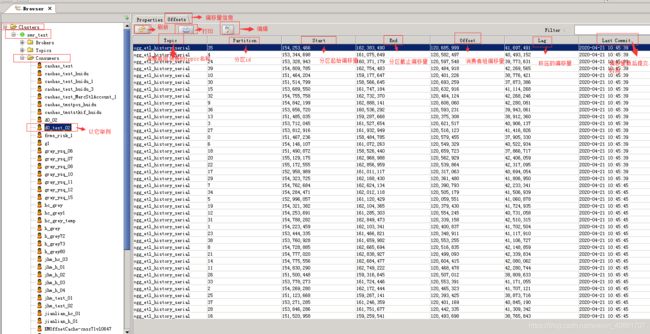
它提供了刷新,打印,编辑功能
可以获取到消费者组消费的topic信息,分区偏移量信息,获取消费端的偏移量,积压的偏移量,以及偏移量最后提交时间
具体如下图所示
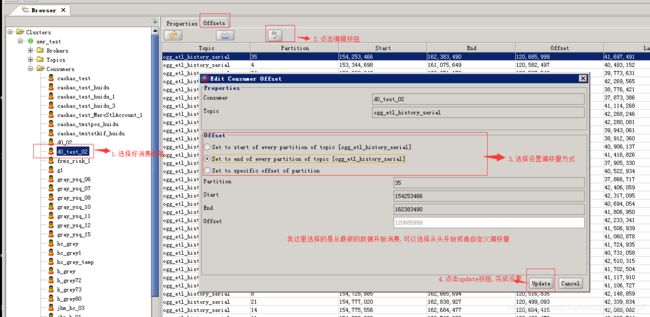
看一下它的编辑功能:
1. 选择要编辑的消费者组
2. 点击编辑按钮
3. 选择设置偏移量方式(从起始位置消费,从截止位置消费,或者从指定的偏移量开始消费)
4. 点击update完成设置
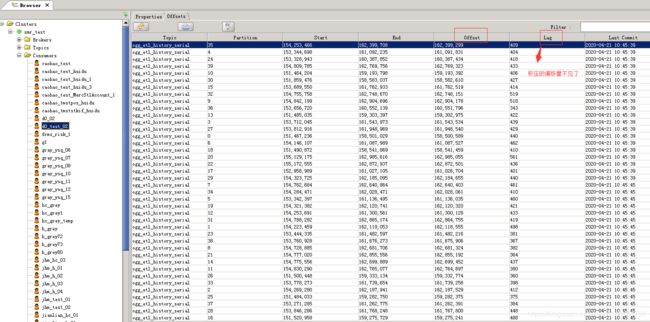
看一下更新之后的效果:
可以看到: 消费端的偏移量和topic的截止消费量基本一致(不等的原因是,topic一直有数据推送)
同时,消费端的数据积压也清空了
 在实际生产中,我们可以通过这种方式跳过我们不需要消费的数据,以提高消费端性能,减少资源占用!
在实际生产中,我们可以通过这种方式跳过我们不需要消费的数据,以提高消费端性能,减少资源占用!
四.使用Kafka Tool排查定位生产问题
最后,在介绍一个使用这个工具定位生产问题的案例
生产问题描述
通过监控邮件发现, Kafka消费落地后的数据,在(数据条数,数据质量)均与源端(oracle)的数据存在差异
而我们对于数据准确性的要求很高
问题排查
查询程序日志,发现如下报错:
 即: Kafka集群在几分钟的时间里不可用
即: Kafka集群在几分钟的时间里不可用
与相关同事确认,在这段时间Kafka集群重启
但他们声称,重启是无感知的,不会造成数据丢失,可能是消费端的参数设计有问题,或者说程序不够健壮???
来不及扯皮,用补数程序把数据补好先~
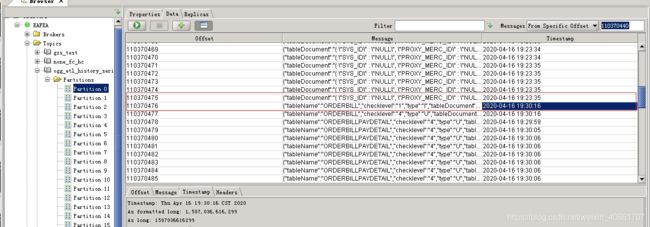
用Kafka-tool工具,查询我用的topic某个分区的数据(窥一豹而见全身)
使用From Specific Offset功能,使用一点子智慧,调整时间戳到集群重启的时间点
发现了如下内容:在接近7分钟的时间里,topic没有任何数据新增(正常情况下,每秒都会有几条到几十条不等的数据)
接下来,根据我的补数程序打印出来的主键信息去Mongo数据库核查,
发现数据全部落在这个时间点
(因为推送端是同时写入这个库和Kafka的)
这个库有对应时间的数据,Kafka集群却没有,可以确定Kafka集群这段时间的数据全部缺失

至此,问题排查清楚
确诊
原因是相关同事在集群重启之前,没有衡量好影响.
同时也没有告知使用方
因此,负责推送的同事没有在集群重启前,停掉推送端,导致这段时间数据丢失
(推送端出于性能和数据一致性的综合考虑,推送失败时会重试几次,但不会一直阻塞)
------ 感谢这个工具, 没有让可怜的我背黑锅~