convolutional pose machines, CVPR 2016
convolutional pose machines, CVPR 2016.
论文:http://arxiv.org/abs/1602.00134
project:https://github.com/shihenw/convolutional-pose-machines-release
=====
看到这篇论文,心里还是有点难受的,当初做pose的毕设时,为什么就不参考下这篇掉渣天的论文呢?
别问我为什么!!!
=====
个人理解
从这个框架来说,类似multi-stage的cascaded network(如deeppose,lecunnet),但是该框架不同于以往的cascaded network:
1 是全卷积网络(FCN),使得整个网络是可导的,也就是意味着可以joint training;
2 不需要显式构建spatial model(或者递归神经网络),通过加大网络的感受野的方式来学习parts之间的空间几何约束关系;
3 不需要post-process
4 容易扩展到multi-person的pose estimation
5 不需要显式利用prior
=====
转入正题:
废话少说,看图(framework)
整个framework还是比较清晰的,也就是构建多个FCN网络来预测part/joint的heat maps,这多个FCN就构成了convolutional pose machines(CPM)。
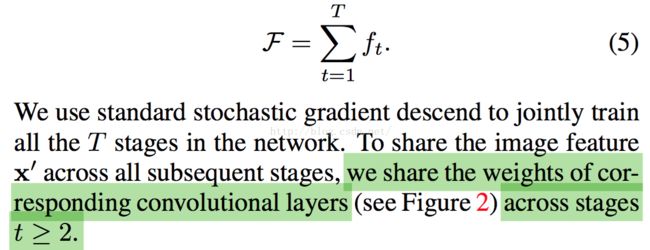
跟别人不同的是,尽管CPM是一个cascaded网络,但是CPM是一个交互的sequence framework,即上一个FCN的上下文(contextual)会作为下一个FCN的输入。
这样就会自然而然地满足了CPM得multi-loss的joint training,而且stage越往前的objective还起到解决梯度弥漫的作用,以及自然而然地提高CPM的感受野。
ps:
值得注意的是,每个stage的卷积核大小的设计,(可以参考deep parsing net的对大卷积核的理解和分析)
=====
目标函数
至于怎么产生ground-truth heat maps的,具体可以参考lecunnet或者flownet。
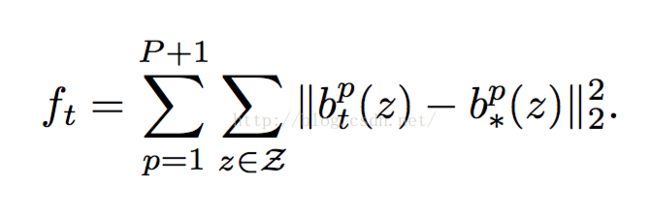
=====
至于怎么training?
论文里给出了4中方式,为了方便还是截图为好

====
至于怎么test?
笔者觉得要么就是用最后一个stage的heat maps来回归出parts/joints的坐标,要么就是把所有的stages的heat maps的加起来,来回归出parts/joints的坐标
从framework来看,即使stage=6,该framework还是比较小,测试速度应该挺快的。
=====
感受野(receptive field)大小的作用

论文里的这一点,笔者是满满的惊讶的,解决了一直来笔者心头对receptive field多大才合适的疑惑,
btw,毕设里为啥没有想到这点呢?
继续哭晕在厕所!!!
=====
intermediate supervision
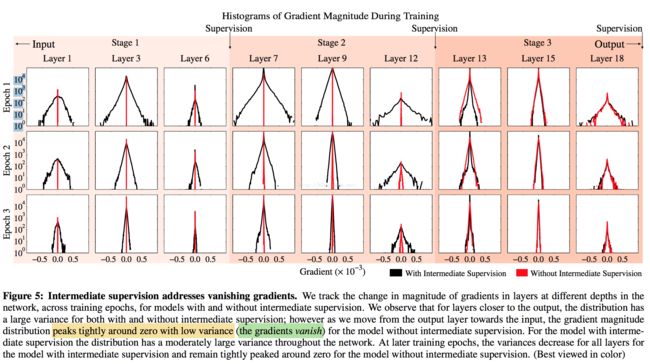
这点应该类似于GoogleNet的auxiliary classfier,用来解决网络随着深度加深而梯度消失的问题。
=====
sequential/stage pose machine的implictly modeling long-range dependencies between parts
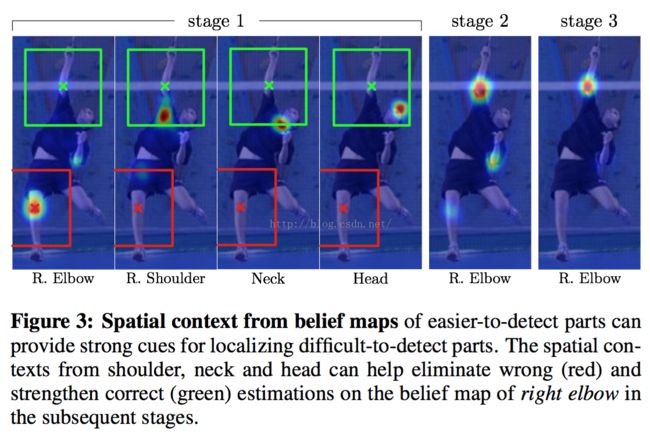
这个看图理解就好,也就是随着stage,CPM会学习到parts之间的空间几何约束关系来纠结这些容易出错的情况,
但是没想到学到的contextual cues能够如此厉害,简直比显式构建的spatial prior model来的好。
=====
看实验效果
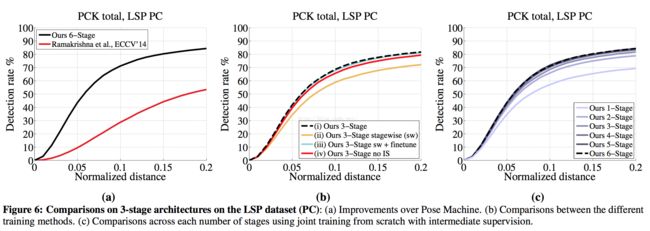

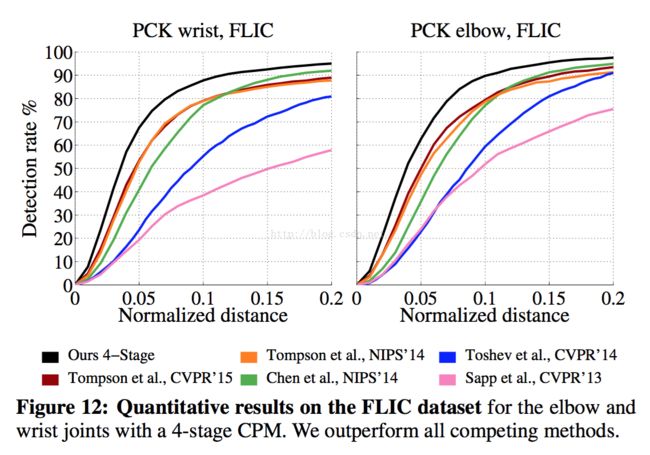
=====
结果可视化

=====
后记
从效果上来看,吊吊的,framework 也容易复现。
有机会的话,重拾毕设时的pose,来套用该框架,看看效果会不会飞起来
(说白了,笔者就是菜鸟一个,哭晕在厕所)
btw,从目前的cvpr,iccv,eccv来看,pose estimation这个问题或者performance已经在各大公开数据集上,刷的飞起来了,笔者会持续关注这个方向的最新进展,好期待!
=====
欢迎各位看客前来讨论交流!
=====
如果这篇博文对你有帮助,可否赏笔者喝杯奶茶?
