在Docker 1.9 出世前,跨多主机的容器通信方案大致有如下三种:
1、端口映射
将宿主机A的端口P映射到容器C的网络空间监听的端口P’上,仅提供四层及以上应用和服务使用。这样其他主机上的容器通过访问宿主机A的端口P实 现与容器C的通信。显然这个方案的应用场景很有局限。
2、将物理网卡桥接到虚拟网桥,使得容器与宿主机配置在同一网段下
在各个宿主机上都建立一个新虚拟网桥设备br0,将各自物理网卡eth0桥接br0上,eth0的IP地址赋给br0;同时修改Docker daemon的DOCKER_OPTS,设置-b=br0(替代docker0),并限制Container IP地址的分配范围为同物理段地址(–fixed-cidr)。重启各个主机的Docker Daemon后,处于与宿主机在同一网段的Docker容器就可以实现跨主机访问了。这个方案同样存在局限和扩展性差的问题:比如需将物理网段的地址划分 成小块,分布到各个主机上,防止IP冲突;子网划分依赖物理交换机设置;Docker容器的主机地址空间大小依赖物理网络划分等。
3、使用第三方的基于SDN的方案:比如 使用Open vSwitch – OVS 或CoreOS的Flannel 等。
关于这些第三方方案的细节大家可以参考O’Reilly的《Docker Cookbook》 一书。
Docker在1.9版本中给大家带来了一种原生的跨多主机容器网络的解决方案,该方案的实质是采用了基于VXLAN 的覆盖网技术。方案的使用有一些前提条件:
1、Linux Kernel版本 >= 3.16;
2、需要一个外部Key-value Store(官方例子中使用的是consul);
3、各物理主机上的Docker Daemon需要一些特定的启动参数;
4、物理主机允许某些特定TCP/UDP端口可用。
本文将带着大家一起利用Docker 1.9.1创建一个跨多主机容器网络,并分析基于该网络的容器间通信原理。
一、实验环境建立
1、升级Linux Kernel
由于实验环境采用的是Ubuntu 14.04 server amd64,其kernel版本不能满足建立跨多主机容器网络要求,因此需要对内核版本进行升级。在Ubuntu的内核站点 下载3.16.7 utopic内核 的三个文件:
linux-headers-3.16.7-031607_3.16.7-031607.201410301735_all.deb
linux-image-3.16.7-031607-generic_3.16.7-031607.201410301735_amd64.deb
linux-headers-3.16.7-031607-generic_3.16.7-031607.201410301735_amd64.deb
在本地执行下面命令安装:
sudo dpkg -i linux-headers-3.16.7-*.deb linux-image-3.16.7-*.deb
需要注意的是:kernel mainline上的3.16.7内核没有带linux-image-extra,也就没有了aufs 的驱动,因此Docker Daemon将不支持默认的存储驱动:–storage-driver=aufs,我们需要将storage driver更换为devicemapper。
内核升级是一个有风险的操作,并且是否能升级成功还要看点“运气”:我的两台刀片服务器,就是一台升级成功一台升级失败(一直报网卡问题)。
2、升级Docker到1.9.1版本
从国内下载Docker官方的安装包比较慢,这里利用daocloud.io提供的方法 快速安装Docker最新版本:
$ curl -sSL https://get.daocloud.io/docker | sh
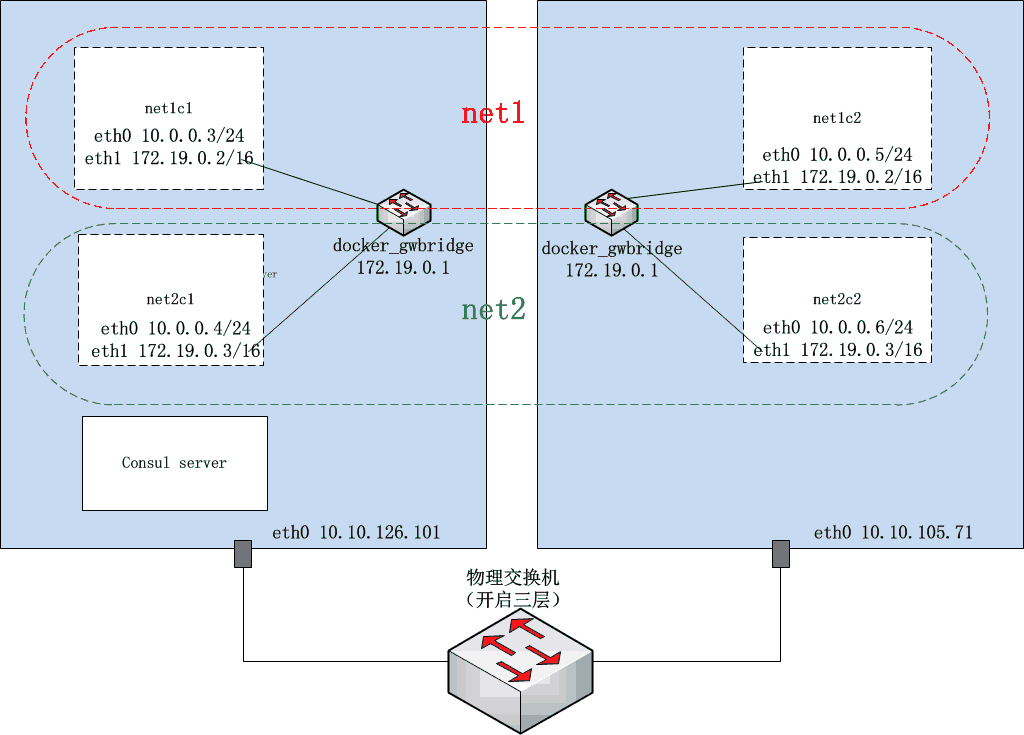
3、拓扑
本次的跨多主机容器网络基于两台在不同子网网段内的物理机承载,基于物理机搭建,目的是简化后续网络通信原理分析。
拓扑图如下:
二、跨多主机容器网络搭建
1、创建consul 服务
考虑到kv store在本文并非关键,仅作跨多主机容器网络创建启动的前提条件之用,因此仅用包含一个server节点的”cluster”。
参照拓扑图,我们在10.10.126.101上启动一个consul,关于consul集群以及服务注册、服务发现等细节可以参考我之前的一 篇文章:
$./consul -d agent -server -bootstrap-expect 1 -data-dir ./data -node=master -bind=10.10.126.101 -client=0.0.0.0 &
2、修改Docker Daemon DOCKER_OPTS参数
前面提到过,通过Docker 1.9创建跨多主机容器网络需要重新配置每个主机节点上的Docker Daemon的启动参数:
ubuntu系统这个配置在/etc/default/docker下:
DOCKER_OPTS="--dns 8.8.8.8 --dns 8.8.4.4 -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --cluster-advertise eth0:2375 --cluster-store consul://10.10.126.101:8500/network --storage-driver=devicemapper"
这里多说几句:
-H(或–host)配置的是Docker client(包括本地和远程的client)与Docker Daemon的通信媒介,也是Docker REST api的服务端口。默认是/var/run/docker.sock(仅用于本地),当然也可以通过tcp协议通信以方便远程Client访问,就像上面 配置的那样。非加密网通信采用2375端口,而TLS加密连接则用2376端口。这两个端口已经申请在IANA注册并获批,变成了知名端口。-H可以配置多个,就像上面配置的那样。 unix socket便于本地docker client访问本地docker daemon;tcp端口则用于远程client访问。这样一来:docker pull ubuntu,走docker.sock;而docker -H 10.10.126.101:2375 pull ubuntu则走tcp socket。
–cluster-advertise 配置的是本Docker Daemon实例在cluster中的地址;
–cluster-store配置的是Cluster的分布式KV store的访问地址;
如果你之前手工修改过iptables的规则,建议重启Docker Daemon之前清理一下iptables规则:sudo iptables -t nat -F, sudo iptables -t filter -F等。
3、启动各节点上的Docker Daemon
以10.10.126.101为例:
$ sudo service docker start
$ ps -ef|grep docker
root 2069 1 0 Feb02 ? 00:01:41 /usr/bin/docker -d --dns 8.8.8.8 --dns 8.8.4.4 --storage-driver=devicemapper -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --cluster-advertise eth0:2375 --cluster-store consul://10.10.126.101:8500/network
启动后iptables的nat, filter规则与单机Docker网络初始情况并无二致。
101节点上初始网络driver类型:
$docker network ls
NETWORK ID NAME DRIVER
47e57d6fdfe8 bridge bridge
7c5715710e34 none null
19cc2d0d76f7 host host
4、创建overlay网络net1和net2
在101节点上,创建net1:
$ sudo docker network create -d overlay net1
在71节点上,创建net2:
$ sudo docker network create -d overlay net2
之后无论在71节点还是101节点,我们查看当前网络以及驱动类型都是如下结果:
$ docker network ls
NETWORK ID NAME DRIVER
283b96845cbe net2 overlay
da3d1b5fcb8e net1 overlay
00733ecf5065 bridge bridge
71f3634bf562 none null
7ff8b1007c09 host host
此时,iptables规则也并无变化。
5、启动两个overlay net下的containers
我们分别在net1和net2下面启动两个container,每个节点上各种net1和net2的container各一个:
101:
sudo docker run -itd --name net1c1 --net net1 ubuntu:14.04
sudo docker run -itd --name net2c1 --net net2 ubuntu:14.04
71:
sudo docker run -itd --name net1c2 --net net1 ubuntu:14.04
sudo docker run -itd --name net2c2 --net net2 ubuntu:14.04
启动后,我们就得到如下网络信息(容器的ip地址可能与前面拓扑图中的不一致,每次容器启动ip地址都可能变化):
net1:
net1c1 - 10.0.0.7
net1c2 - 10.0.0.5
net2:
net2c1 - 10.0.0.4
net2c2 - 10.0.0.6
6、容器连通性
在net1c1中,我们来看看其到net1和net2的连通性:
root@021f14bf3924:/# ping net1c2
PING 10.0.0.5 (10.0.0.5) 56(84) bytes of data.
64 bytes from 10.0.0.5: icmp_seq=1 ttl=64 time=0.670 ms
64 bytes from 10.0.0.5: icmp_seq=2 ttl=64 time=0.387 ms
^C
--- 10.0.0.5 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.387/0.528/0.670/0.143 ms
root@021f14bf3924:/# ping 10.0.0.4
PING 10.0.0.4 (10.0.0.4) 56(84) bytes of data.
^C
--- 10.0.0.4 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 1008ms
可见,net1中的容器是互通的,但net1和net2这两个overlay net之间是隔离的。
三、跨多主机容器网络通信原理
在“单机容器网络”一文中,我们说过容器间的通信以及容器到外部网络的通信是通过docker0网桥并结合iptables实现的。那么在上面已经建立的跨多主机容器网络里,容器的通信又是如何实现的呢?下面我们一起来理解一下。注意:有了单机容器网络基础后,这里很多网络细节就不再赘述了。
我们先来看看,在net1下的容器的网络配置,以101上的net1c1容器为例:
$ sudo docker attach net1c1
root@021f14bf3924:/# ip route
default via 172.19.0.1 dev eth1
10.0.0.0/24 dev eth0 proto kernel scope link src 10.0.0.4
172.19.0.0/16 dev eth1 proto kernel scope link src 172.19.0.2
root@021f14bf3924:/# ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
8: eth0: mtu 1450 qdisc noqueue state UP group default
link/ether 02:42:0a:00:00:04 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.4/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:aff:fe00:4/64 scope link
valid_lft forever preferred_lft forever
10: eth1: mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:13:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.19.0.2/16 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::42:acff:fe13:2/64 scope link
valid_lft forever preferred_lft forever
可以看出net1c1有两个网口:eth0(10.0.0.4)和eth1(172.19.0.2);从路由表来看,目的地址在172.19.0.0/16范围内的,走eth1;目的地址在10.0.0.0/8范围内的,走eth0。
我们跳出容器,回到主机网络范畴:
在101上:
$ ip a
... ...
5: docker_gwbridge: mtu 1500 qdisc noqueue state UP
link/ether 02:42:52:35:c9:fc brd ff:ff:ff:ff:ff:ff
inet 172.19.0.1/16 scope global docker_gwbridge
valid_lft forever preferred_lft forever
inet6 fe80::42:52ff:fe35:c9fc/64 scope link
valid_lft forever preferred_lft forever
6: docker0: mtu 1500 qdisc noqueue state DOWN
link/ether 02:42:4b:70:68:9a brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 scope global docker0
valid_lft forever preferred_lft forever
11: veth26f6db4: mtu 1500 qdisc noqueue master docker_gwbridge state UP
link/ether b2:32:d7:65:dc:b2 brd ff:ff:ff:ff:ff:ff
inet6 fe80::b032:d7ff:fe65:dcb2/64 scope link
valid_lft forever preferred_lft forever
16: veth54881a0: mtu 1500 qdisc noqueue master docker_gwbridge state UP
link/ether 9e:45:fa:5f:a0:15 brd ff:ff:ff:ff:ff:ff
inet6 fe80::9c45:faff:fe5f:a015/64 scope link
valid_lft forever preferred_lft forever
我们看到除了我们熟悉的docker0网桥外,还多出了一个docker_gwbridge网桥:
$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.02424b70689a no
docker_gwbridge 8000.02425235c9fc no veth26f6db4
veth54881a0
并且从brctl的输出结果来看,两个veth都桥接在docker_gwbridge上,而不是docker0上;docker0在跨多主机容器网络中并没有被用到。docker_gwbridge替代了docker0,用来实现101上隶属于net1网络或net2网络中容器间的通信以及容器到外部的通信,其职能就和单机容器网络中docker0一样。
但位于不同host且隶属于net1的两个容器net1c1和net1c2间的通信显然并没有通过docker_gwbridge完成,从net1c1路由表来看,当net1c1 ping net1c2时,消息是通过eth0,即10.0.0.4这个ip出去的。从host的视角,net1c1的eth0似乎没有网络设备与之连接,那网络通信是如何完成的呢?
这一切是从创建network开始的。前面我们执行docker network create -d overlay net1来创建net1 overlay network,这个命令会创建一个新的network namespace。
我们知道每个容器都有自己的网络namespace,从容器的视角看其网络名字空间,我们能看到网络设备诸如:lo、eth0。这个eth0与主机网络名字空间中的vethx是一个虚拟网卡pair。overlay network也有自己的net ns,而overlay network的net ns与容器的net ns之间也有着一些网络设备对应关系。
我们先来查看一下network namespace的id。为了能利用iproute2工具对network ns进行管理,我们需要做如下操作:
$cd /var/run
$sudo ln -s /var/run/docker/netns netns
这是因为iproute2只能操作/var/run/netns下的net ns,而docker默认的net ns却放在/var/run/docker/netns下。上面的操作成功执行后,我们就可以通过ip命令查看和管理net ns了:
$ sudo ip netns
29170076ddf6
1-283b96845c
5ae976d9dc6a
1-da3d1b5fcb
我们看到在101主机上,有4个已经建立的net ns。我们大胆猜测一下,这四个net ns分别是两个container的net ns和两个overlay network的net ns。从netns的ID格式以及结合下面命令输出结果中的network id来看:
$ docker network ls
NETWORK ID NAME DRIVER
283b96845cbe net2 overlay
da3d1b5fcb8e net1 overlay
dd84da8e80bf host host
3295c22b22b8 docker_gwbridge bridge
b96e2d8d4068 bridge bridge
23749ee4292f none null
我们大致可以猜测出来:
1-da3d1b5fcb 是 net1的net ns;
1-283b96845c是 net2的net ns;
29170076ddf6和5ae976d9dc6a则分属于两个container的net ns。
由于我们以net1为例,因此下面我们就来分析net1的net ns – 1-da3d1b5fcb。通过ip命令我们可以得到如下结果:
$ sudo ip netns exec 1-da3d1b5fcb ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: br0: mtu 1450 qdisc noqueue state UP
link/ether 06:b0:c6:93:25:f3 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.1/24 scope global br0
valid_lft forever preferred_lft forever
inet6 fe80::b80a:bfff:fecc:a1e0/64 scope link
valid_lft forever preferred_lft forever
7: vxlan1: mtu 1500 qdisc noqueue master br0 state UNKNOWN
link/ether ea:0c:e0:bc:19:c5 brd ff:ff:ff:ff:ff:ff
inet6 fe80::e80c:e0ff:febc:19c5/64 scope link
valid_lft forever preferred_lft forever
9: veth2: mtu 1450 qdisc noqueue master br0 state UP
link/ether 06:b0:c6:93:25:f3 brd ff:ff:ff:ff:ff:ff
inet6 fe80::4b0:c6ff:fe93:25f3/64 scope link
valid_lft forever preferred_lft forever
$ sudo ip netns exec 1-da3d1b5fcb ip route
10.0.0.0/24 dev br0 proto kernel scope link src 10.0.0.1
$ sudo ip netns exec 1-da3d1b5fcb brctl show
bridge name bridge id STP enabled interfaces
br0 8000.06b0c69325f3 no veth2
vxlan1
看到br0、veth2,我们心里终于有了底儿了。我们猜测net1c1容器中的eth0与veth2是一个veth pair,并桥接在br0上,通过ethtool查找veth序号的对应关系可以证实这点:
$ sudo docker attach net1c1
root@021f14bf3924:/# ethtool -S eth0
NIC statistics:
peer_ifindex: 9
101主机:
$ sudo ip netns exec 1-da3d1b5fcb ip -d link
1: lo: mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: br0: mtu 1450 qdisc noqueue state UP
link/ether 06:b0:c6:93:25:f3 brd ff:ff:ff:ff:ff:ff
bridge
7: vxlan1: mtu 1500 qdisc noqueue master br0 state UNKNOWN
link/ether ea:0c:e0:bc:19:c5 brd ff:ff:ff:ff:ff:ff
vxlan
9: veth2: mtu 1450 qdisc noqueue master br0 state UP
link/ether 06:b0:c6:93:25:f3 brd ff:ff:ff:ff:ff:ff
veth
可以看到net1c1的eth0的pair peer index为9,正好与net ns 1-da3d1b5fcb中的veth2的序号一致。
那么vxlan1呢?注意这个vxlan1并非是veth设备,在ip -d link输出的信息中,它的设备类型为vxlan。前面说过Docker的跨多主机容器网络是基于vxlan的,这里的vxlan1就是net1这个overlay network的一个 VTEP,即VXLAN Tunnel End Point – VXLAN隧道端点。它是VXLAN网络的边缘设备。VXLAN的相关处理都在VTEP上进行,例如识别以太网数据帧所属的VXLAN、基于 VXLAN对数据帧进行二层转发、封装/解封装报文等。
至此,我们可以大致画出一幅跨多主机网络的原理图:
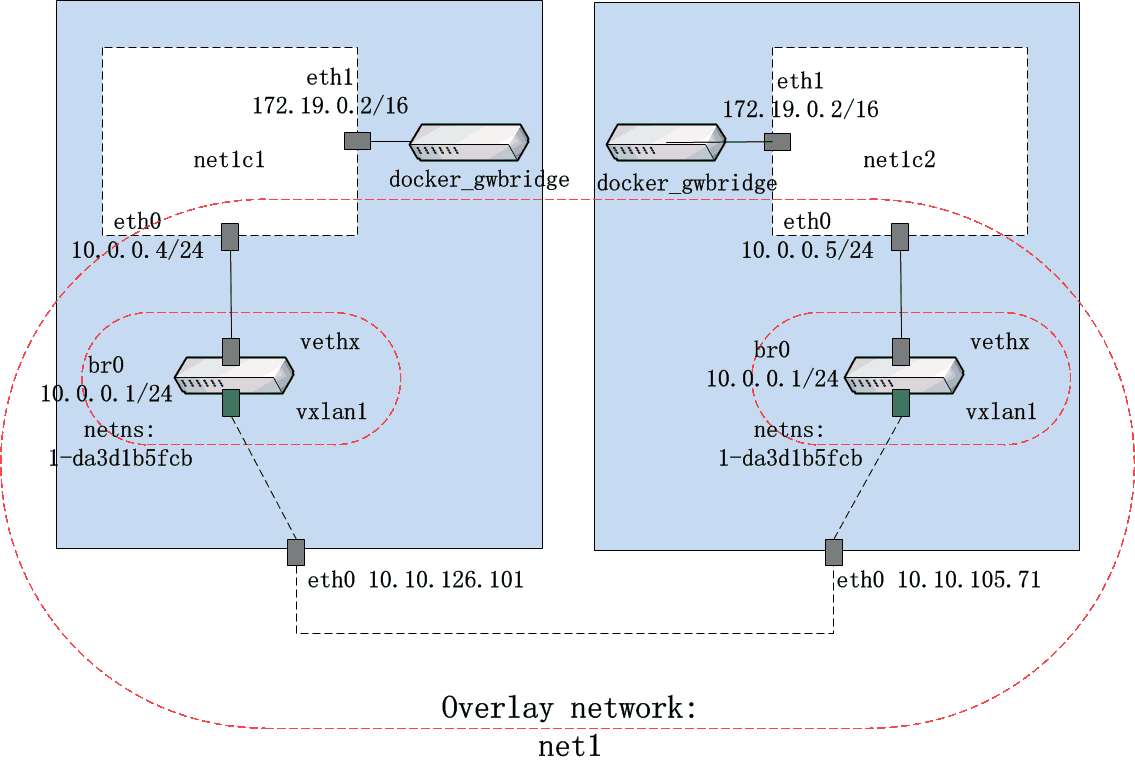
如果在net1c1中ping net1c2,数据包的行走路径是怎样的呢?
1、net1c1(10.0.0.4)中ping net1c2(10.0.0.5),根据net1c1的路由表,数据包可通过直连网络到达net1c2。于是arp请求获取net1c2的MAC地址(在vxlan上的arp这里不详述了),得到mac地址后,封包,从eth0发出;
2、eth0桥接在net ns 1-da3d1b5fcb中的br0上,这个br0是个网桥(交换机)虚拟设备,需要将来自eth0的包转发出去,于是将包转给了vxlan设备;这个可以通过arp -a看到一些端倪:
$ sudo ip netns exec 1-da3d1b5fcb arp -a
? (10.0.0.5) at 02:42:0a:00:00:05 [ether] PERM on vxlan1
3、vxlan是个特殊设备,收到包后,由vxlan设备创建时注册的设备处理程序对包进行处理,即进行VXLAN封包(这期间会查询consul中存储的net1信息),将ICMP包整体作为UDP包的payload封装起来,并将UDP包通过宿主机的eth0发送出去。
4、71宿主机收到UDP包后,发现是VXLAN包,根据VXLAN包中的相关信息(比如Vxlan Network Identifier,VNI=256)找到vxlan设备,并转给该vxlan设备处理。vxlan设备的处理程序进行解包,并将UDP中的payload取出,整体通过br0转给veth口,net1c2从eth0收到ICMP数据包,回复icmp reply。
我们可以通过wireshark抓取相关vxlan包,高版本wireshark内置VXLAN协议分析器,可以直接识别和展示VXLAN包,这里安装的是2.0.1版本(注意:一些低版本wireshark不支持VXLAN分析器,比如1.6.7版本):
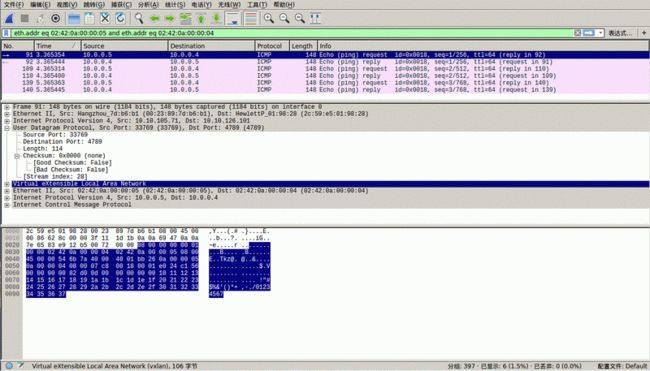
关于VXLAN协议的细节,过于复杂,在后续的文章中maybe会有进一步理解。
© 2016, bigwhite. 版权所有.