spark的UDF和UDAF用法
UDF(user defined function)
UDF: 输入一行, 返回一个结果. 一对一关系
放入函数一个值, 就返回一个值, 而不会返回多个值.
如下面的例子就可以看出: (x: String) => "Name=" + x 这个函数, 入参为一个, 返回也是一个, 而不会返回多个值.
来个demo:
In路径下的user.txt文件内容如下:
{
"name": "zhangsan","age": 20}
{
"name": "lisi", "age": 30}
{
"name": "wangwu","age":40}
// 用户可以自定义函数
object SparkSql_UDF {
def main(args: Array[String]): Unit = {
/**
* 注意:
* 如果需要RDD与DF或者DS之间操作,那么都需要引入 import spark.implicits._ 【spark不是包名,而是sparkSession对象的名称】
* 前置条件:导入隐式转换并创建一个RDD
*/
// 设定spark计算框架的运行(部署) 环境
val sparkconf = new SparkConf().setMaster("local[*]").setAppName("spark")
// 创建SparkSql的环境对象
val spark = SparkSession.builder().config(sparkconf).getOrCreate()
// 进行转换之前, 需要引入隐式转换规则
// 这里的spark不是包名的含义, 是SparkSession对象的名字
import spark.implicits._
val frame: DataFrame = spark.read.json("in")
// 向spark中注册一个addName函数,
val addName: UserDefinedFunction = spark.udf.register("addName", (x: String) => "Name=" + x)
// 给DataFrame起一个表名
frame.createOrReplaceTempView("user")
val frame1: DataFrame = spark.sql("select addName(name) bb from user")
// 展示数据
frame1.show()
}
}
运行结果:

UDTF: 输入一行, 返回多行(hive). 一对多的关系. 在sparkSQL中没有UDTF。在hive中有。在sparkSQL中使用flatMap就可以实现该功能!。 一对多的功能.
UDAF: user defined aggregate function
UDAF: 输入多行, 返回一行. aggregate(聚合) 比如: count,sum, avg, 这些是sparkSQL自带的聚合函数,如果有复杂的业务需求,要自己定义
demo:
弱类型的UDAF
SQL的风格
object SparkSql_UDAF_Demo {
def main(args: Array[String]): Unit = {
// 设定spark计算框架的运行(部署) 环境
val sparkconf = new SparkConf().setMaster("local").setAppName("spark")
// 创建SparkSql的环境对象
val spark = SparkSession.builder().config(sparkconf).getOrCreate()
val gm: GenMean = new GenMean
//注册聚合函数, 在后面使用就用gm来使用
spark.udf.register("gm", gm)
val range: Dataset[lang.Long] = spark.range(1, 11)
// 给DataFrame起个表名
range.createTempView("v_range")
// 使用自定义的聚合函数, sql风格
val result: DataFrame = spark.sql("select gm(id) from v_range")
result.show()
// 关闭资源
spark.stop()
}
}
class GenMean extends UserDefinedAggregateFunction {
// 输入数据的类型
override def inputSchema: StructType = {
StructType(List(StructField("value", DoubleType)))
}
/*
产生中间结果的数据类型
相当于每个分区里要进行计算
*/
override def bufferSchema: StructType = StructType(List(
// 相乘之后返回的积
StructField("product", DoubleType),
// 参与运算数字的个数
StructField("count", LongType)
))
// 最终返回的结果类型
override def dataType: DataType = DoubleType
// 确保一致性, 一般用true
override def deterministic: Boolean = true
/*
每个分区里的product和count值要有初始值
指定初始值
*/
override def initialize(buffer: MutableAggregationBuffer): Unit = {
// 相乘的初始值
buffer(0) = 1.0
// 参与运算数字的个数的初始值
buffer(1) = 0L
}
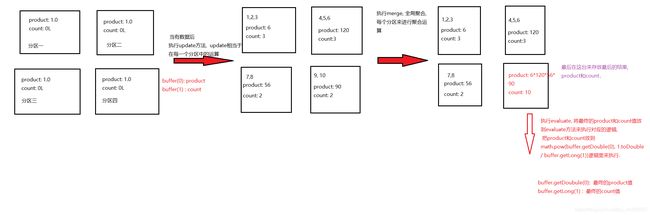
// 每有一条数据参与运算就更新一下中间结果(update相当于在每一个分区中的运算)
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
// 每有一个数字参与运算就进行相乘(包含了之前的中间结果)
buffer(0) = buffer.getDouble(0) + input.getDouble(0)
// 参与运算数据的个数也有在更新(也包含了之前的中间结果)
buffer(1) = buffer.getLong(1) + 1L
}
// 全局聚合, 每个分区来进行聚合运算
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
// 每个分区计算的结果进行相乘
buffer1(0) = buffer1.getDouble(0) * buffer2.getDouble(0)
// 每个分区参与预算的中间结果进行相加
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
/*
计算最终的结果
通过merge方法后, 各个分区的数据都相乘和累加了. 接下来就是将各个分区的数据统计出来的结果来
进行求出几何平均数.
*/
override def evaluate(buffer: Row): Any = {
math.pow(buffer.getDouble(0), 1.toDouble / buffer.getLong(1))
}
}
运行结果:
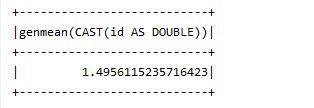
可以画个大概的图来理解UDAF:
DSL的风格:
object SparkSql_UDAF_Demo {
def main(args: Array[String]): Unit = {
// 设定spark计算框架的运行(部署) 环境
val sparkconf = new SparkConf().setMaster("local").setAppName("spark")
// 创建SparkSql的环境对象
val spark = SparkSession.builder().config(sparkconf).getOrCreate()
//创建聚合函数对象
val gm: GenMean = new GenMean
val range: Dataset[lang.Long] = spark.range(1, 11)
import spark.implicits._
// DSL的风格, 不需要注册聚合函数
val result1: DataFrame = range.agg(gm($"id").as("geomean"))
result1.show()
// 关闭资源
spark.stop()
}
}
class GenMean extends UserDefinedAggregateFunction {
// 输入数据的类型
override def inputSchema: StructType = {
StructType(List(StructField("value", DoubleType)))
}
/*
产生中间结果的数据类型
相当于每个分区里要进行计算
*/
override def bufferSchema: StructType = StructType(List(
// 相乘之后返回的积
StructField("product", DoubleType),
// 参与运算数字的个数
StructField("count", LongType)
))
// 最终返回的结果类型
override def dataType: DataType = DoubleType
// 确保一致性, 一般用true
override def deterministic: Boolean = true
/*
每个分区里的product和count值要有初始值
指定初始值
*/
override def initialize(buffer: MutableAggregationBuffer): Unit = {
// 相乘的初始值
buffer(0) = 1.0
// 参与运算数字的个数的初始值
buffer(1) = 0L
}
// 每有一条数据参与运算就更新一下中间结果(update相当于在每一个分区中的运算)
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
// 每有一个数字参与运算就进行相乘(包含了之前的中间结果)
buffer(0) = buffer.getDouble(0) + input.getDouble(0)
// 参与运算数据的个数也有在更新(也包含了之前的中间结果)
buffer(1) = buffer.getLong(1) + 1L
}
// 全局聚合, 每个分区来进行聚合运算
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
// 每个分区计算的结果进行相乘
buffer1(0) = buffer1.getDouble(0) * buffer2.getDouble(0)
// 每个分区参与预算的中间结果进行相加
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
/*
计算最终的结果
通过merge方法后, 各个分区的数据都相乘和累加了. 接下来就是将各个分区的数据统计出来的结果来
进行求出几何平均数.
*/
override def evaluate(buffer: Row): Any = {
math.pow(buffer.getDouble(0), 1.toDouble / buffer.getLong(1))
}
}
运行结果:

强类型的UDAF
继承Aggregator抽象类
// 用户可以自定义聚合函数(强类型)
object SparkSql_UDAF_Class {
def main(args: Array[String]): Unit = {
/**
* 注意:
* 如果需要RDD与DF或者DS之间操作,那么都需要引入 import spark.implicits._ 【spark不是包名,而是sparkSession对象的名称】
* 前置条件:导入隐式转换并创建一个RDD
*/
// 设定spark计算框架的运行(部署) 环境
val sparkconf = new SparkConf().setMaster("local[*]").setAppName("spark")
// 创建SparkSql的环境对象
val spark = SparkSession.builder().config(sparkconf).getOrCreate()
// 进行转换之前, 需要引入隐式转换规则
// 这里的spark不是包名的含义, 是SparkSession对象的名字
import spark.implicits._
// 读取数据
val frame: DataFrame = spark.read.json("in")
frame.show()
// 创建聚合函数对象
val function = new MyAgeAvgClassFunction
// 将聚合函数转换为查询列
val col: TypedColumn[UserBean, Double] = function.toColumn.name("shaojunjun")
// 将DataFrame转换为DataSet
val value1: Dataset[UserBean] = frame.as[UserBean]
// 将转换的查询列放入到DSL风格语法里
value1.select(col).show()
spark.close()
}
}
//声明用户自定义聚合函数(强类型)
// 1. 继承 Aggregator类, 设定泛型
// 2. 实现方法
// 样例类中的属性默认是val, 只读
case class UserBean(name: String, age: BigInt)
case class AvgBuffer(var sum: BigInt, var count: Int)
class MyAgeAvgClassFunction extends Aggregator[UserBean, AvgBuffer, Double]{
// 初始化
override def zero: AvgBuffer = {
// 构建缓冲区对象
AvgBuffer(0,0)
}
//聚合数据
override def reduce(b: AvgBuffer, a: UserBean): AvgBuffer = {
b.sum = b.sum + a.age
b.count = b.count + 1
b
}
// 缓冲区的合并
override def merge(b1: AvgBuffer, b2: AvgBuffer): AvgBuffer = {
b1.sum = b1.sum + b2.sum
b1.count = b1.count + b2.count
b1
}
// 完成计算
override def finish(reduction: AvgBuffer): Double = {
reduction.sum.toDouble / reduction.count
}
// 自定义类型写 Encoders.product
override def bufferEncoder: Encoder[AvgBuffer] = Encoders.product
// 基本类型写 Encoders.scalaDouble
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}